Integrazione di Amazon Redshift per Apache Spark
Crea applicazioni Apache Spark che leggono e scrivono dati da Amazon Redshift
A cosa serve l’integrazione di Amazon Redshift per Apache Spark?

Vantaggi di Amazon Redshift
-
Ampliare le origini dei dati che puoi utilizzare nelle applicazioni di analisi approfondite e machine learning (ML) in esecuzione in Amazon EMR, AWS Glue o SageMaker, leggendo e scrivendo dati nel tuo data warehouse.
-
Semplificare il processo macchinoso e spesso manuale di configurazione di connettori e driver JDBC non certificati, riducendo i tempi di preparazione per le attività di analisi e ML.
-
Utilizzare diverse funzionalità di pushdown come funzioni di ordinamento, aggregazione, limitazione, unione e funzioni scalari, per spostare dal data warehouse Amazon Redshift solo i dati rilevanti.
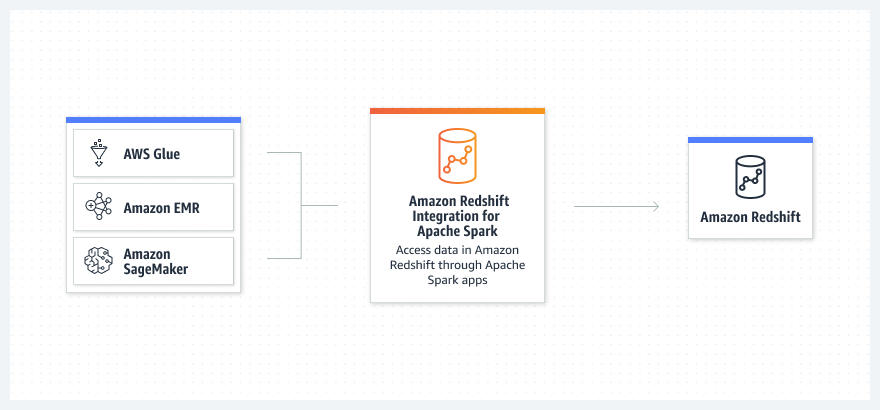
Come funziona
Casi d’uso
-
Crea applicazioni Apache Spark in Java, Scala e Python con i servizi di analisi AWS basati su Apache Spark.
-
Leggi e scrivi dati in Amazon Redshift con Amazon EMR, AWS Glue, SageMaker e i servizi di analisi e ML di AWS.
-
Utilizza Amazon EMR o AWS Glue per acquisire il codice dei frame di dati dal tuo processo o notebook Apache Spark e connetterti ad Amazon Redshift.
-
Semplifica il tuo processo senza installazioni o test, con una maggiore sicurezza (credenziali basate su IAM), pushdown operativi e formato di file Parquet per le prestazioni.
Clienti
Corey Johnson, Data Architect Manager - Huron Consulting
Huron è una società globale di servizi professionali che collabora con i clienti per realizzare nuove possibilità creando strategie solide, ottimizzando le operazioni, accelerando la trasformazione digitale e consentendo alle aziende e ai loro dipendenti di plasmare il proprio futuro.
"Diamo ai nostri ingegneri la possibilità di creare le loro pipeline di dati e applicazioni con Apache Spark utilizzando Python e Scala. Volevamo una soluzione su misura che semplificasse le operazioni e fornisse ai nostri clienti un servizio più rapido ed efficiente ed è quello che otteniamo con la nuova integrazione di Amazon Redshift per Apache Spark.”
Alcuin Weidus, Senior Principal Data Architect - GE Aerospace
GE Aerospace è un fornitore globale di motori a reazione, componenti e sistemi per aerei commerciali e militari. L'azienda progetta, sviluppa e produce motori a reazione dalla prima guerra mondiale.
GE Aerospace utilizza le analisi di AWS e Amazon Redshift per ottenere informazioni aziendali critiche che favoriscono importanti decisioni aziendali. Con il supporto della copia automatica di Amazon S3, possiamo creare pipeline di dati più semplici per spostare i dati da Amazon S3 ad Amazon Redshift. I nostri team di prodotti di dati possono accedere ai dati e fornire informazioni agli utenti finali più rapidamente. Dedichiamo più tempo ad aggiungere valore attraverso i dati e meno tempo alle integrazioni”.
Neema Raphael, Chief Data Officer - Goldman Sachs
The Goldman Sachs Group, Inc. è un’istituzione finanziaria leader a livello mondiale che offre un’ampia gamma di servizi finanziari nei settori dell’investment banking, dei titoli, della gestione degli investimenti e del consumer banking a una clientela ampia e diversificata che comprende aziende, istituzioni finanziarie, enti pubblici e utenti privati.
"Il nostro obiettivo è fornire un accesso self-service ai dati a tutti gli utenti di Goldman Sachs. Attraverso Legend, la nostra piattaforma open source di gestione e governance dei dati, consentiamo agli utenti di sviluppare applicazioni e di ricavare informazioni basate sui dati, collaborando con il settore dei servizi finanziari. Con l'integrazione di Amazon Redshift per Apache Spark, il nostro team della piattaforma di dati sarà in grado di accedere ai dati di Amazon Redshift con passaggi manuali minimi, consentendo processi ETL senza codice che daranno ai nostri ingegneri la possibilità di concentrarsi più facilmente sul perfezionamento del loro flusso di lavoro e di raccogliere informazioni complete e tempestive. Poiché i nostri utenti possono ora accedere facilmente ai dati più recenti in Amazon Redshift, ci aspettiamo un miglioramento nelle prestazioni delle applicazioni e una maggiore sicurezza”.
Risorse
Hai trovato quello che cercavi?
Facci sapere la tua opinione per aiutarci a migliorare la qualità dei contenuti delle nostre pagine