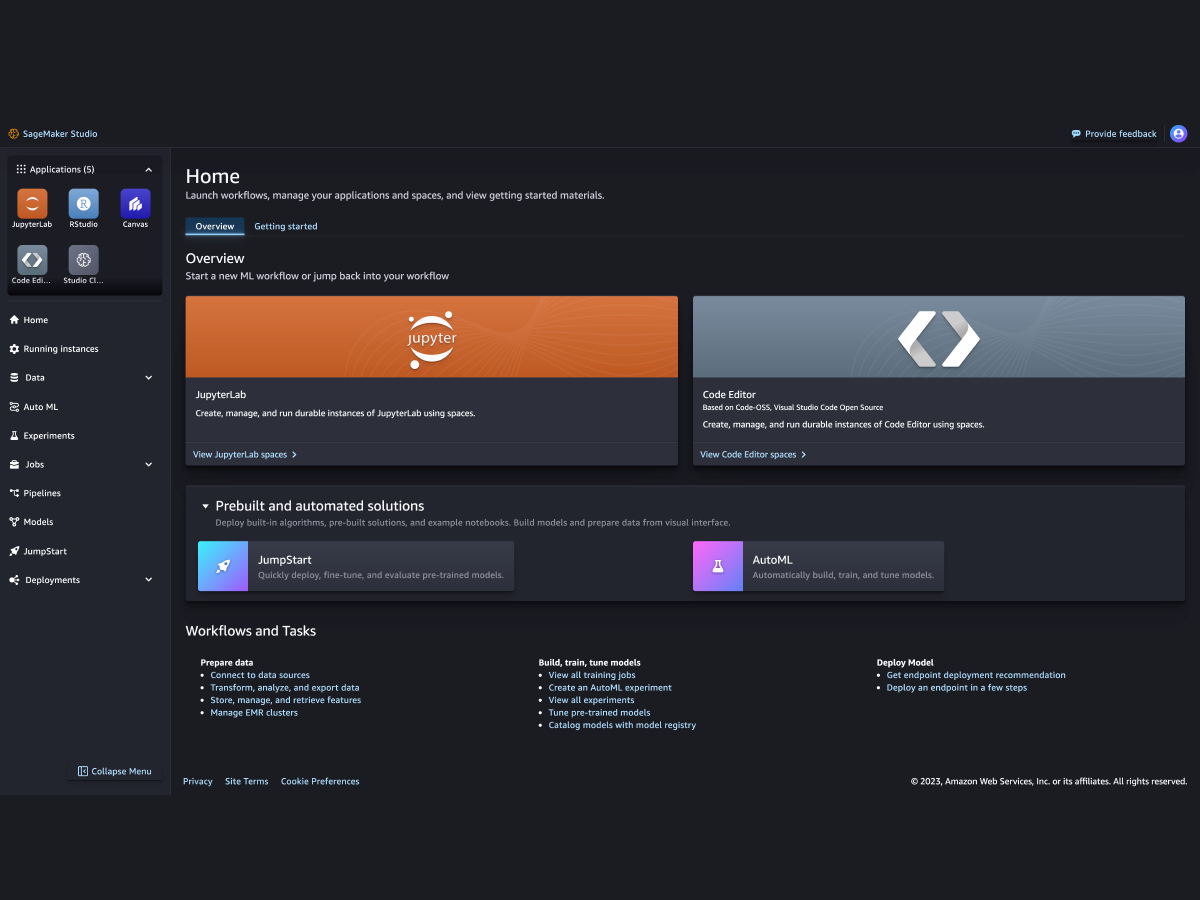
Amazon SageMaker Studio
A single web-based interface for end-to-end AI model development
Why SageMaker Studio?
Amazon SageMaker Studio supports complete end-to-end AI model development, from preparing data to building, training, customizing models, deploying, and managing your AI models. You can quickly start working with your data and build models using your preferred integrated development environment (IDE).. Streamline team collaboration, code efficiently using the AI-powered coding companion, tune and debug models, deploy and manage models in production, and automate workflows—all within a single, unified web-based interface.
Benefits of SageMaker Studio
Build AI models in your preferred IDE, whether a fully managed cloud IDE or your local environment. Launch fully managed IDEs including JupyterLab, Code Editor, and RStudio, and scale compute dynamically. Customize models with an agentic experience in JupyterLab with Kiro and agent skills preinstalled, or through your preferred agentic IDE. Bring any ACP-compatible agent including Claude Code, Gemini, OpenCode, and Codex. Train models on multi-turn agent interactions using the SageMaker Python SDK or the guided UI in Studio.
Access purpose-built tools for each step of your AI model development, from preparing data to building, training, deploying, and managing models. Quickly upload data, create new notebooks, train and tune models, move back and forth between steps to adjust experiments, compare results, and deploy models to production, all in one place.. Build faster with an AI coding agent. Kiro is available directly in SageMaker AI Studio JupyterLab and Code Editor. You can also bring any ACP-compatible coding agent into JupyterLab, including Claude Code.
Customize and train generative AI models with access to hundreds of popular publicly available models and over 15 prebuilt solutions through Amazon SageMaker JumpStart. You can access models from top model providers such as AI21 Labs, LightOn, Stability AI, Hugging Face, Alexa, and Meta AI. Then quickly evaluate, compare, and select the best foundation models (FMs) for your use case based on predefined metrics such as accuracy, robustness, and toxicity. Human evaluations can be used for more subjective dimensions such as creativity and style.
Accelerate your model development with popular apps from AWS Partners. Use a seamless and fully managed experience with no infrastructure to provision or operate, all within the security and privacy of your SageMaker AI environment.
Use cases
-
Build generative AI applications faster with access to a wide range of publicly available FMs, model evaluation tools, IDEs backed by high-performance accelerated computing, and the ability to directly fine-tune and deploy FMs at scale from SageMaker Studio.
Unify your end-to-end AI model development in SageMaker Studio with the most comprehensive tools all in one place. SageMaker AI offers high-performing MLOps tools to help you automate and standardize workflows and governance tools to support transparency and auditability across your organization.
SageMaker Studio offers a unified experience to explore data, build models and move seamlessly from experimentation to production. Create, browse, and connect to Amazon EMR clusters. Build, test, and run interactive data preparation and analytics applications with AWS Glue interactive sessions. Monitor and debug Spark jobs using familiar tools such as Spark UI—all right from SageMaker Studio.
AI apps from AWS Partners
Access industry-leading apps in a secure, managed environment to accelerate your generative AI and ML development.