Amazon Web Services 한국 블로그
이상 탐지를 위한 Amazon SageMaker 의 Random Cut Forest 빌트인 알고리즘
Amazon SageMaker에서 새로운 빌트인 알고리즘으로 Random Cut Forest(RCF)를 사용하실 수 있습니다. RCF는 데이터셋에서 이상치(outlier)를 탐지하는 비지도 학습 알고리즘입니다. 이번 블로그에서는 이상 탐지(anomaly detection) 문제에 대해 설명하고, Amazon SageMaker의 RCF 알고리즘에 대해서도 함께 알아보겠습니다. 아울러, 실제 데이터셋을 대상으로 Amazon SageMaker의 RCF 알고리즘을 어떻게 사용하는지도 소개합니다.
이상 탐지 기술의 중요성
우리가 어느 한 도시에서 여러 개의 블럭(block)을 대상으로 일정 시간 동안 교통량에 대한 데이터를 수집했다고 가정해 봅시다. 만약 교통량이 순간 급증한 경우, 이것을 추돌 사고가 일어난 것으로 볼 것인지 또는 통상 일어나는 러시 아워(rush hour) 상태로 볼 것인지 예측할 수 있을까요? 또 교통량 순간 급증 현상이 한 블럭에서만 일어난 것인지, 여러 블럭에서 일어난 것인지 여부도 중요할까요? 한편 (IT 비즈니스 영역에서 많이 다루는 문제인) 클러스터를 구성하는 서버들 간의 네트워크 트래픽에 대해서도 생각해볼 수 있습니다. 이를테면 인프라가 디도스(DDOS, 분산 서비스 거부) 공격을 받는 상태인지, 또는 네트워크 액티비티가 계속 증가하고 있는지 등에 대해 자동으로 추적할 수 있을까요?
‘이상(anomaly)’ 라는 것은 정형화된 데이터 또는 특정 패턴을 보이는 데이터와 다른 형태로 나타나는 데이터를 말합니다. 예를 들면, 시계열 데이터에서 예측 불가한 순간 급변 형태의 값을 보이는 것을 생각해볼 수 있습니다. 또 예측치와 맞지 않는 결과, 분류가 안되는 데이터 등도 ‘이상’의 예에 해당됩니다. 데이터넷에 이러한 이상치들이 포함되어 있을 경우 머신 러닝 작업의 복잡도가 어마어마하게 높아집니다. 왜냐하면 “정상적인 (regular)” 데이터의 경우 단순한 모델로 표현될 수 있기 때문입니다.
Amazon SageMaker의 Random Cut Forest 알고리즘
Amazon SageMaker의 Random Cut Forest (RCF) 알고리즘은 데이터셋에 포함되어 있는 이상치들을 탐지하는 비지도 학습 알고리즘입니다. 특히, Amazon SageMaker의 RCF 알고리즘은 각 데이터에 대해 이상치 스코어(anomaly score)를 부여합니다. 이상치 스코어가 낮을 경우 해당 데이터는 정상(normal)일 가능성이 높은 반면, 높은 스코어를 보일 경우 이 데이터는 이상(anomaly)일 가능성이 높다는 것을 나타냅니다.
스코어의 “높음/낮음”에 대한 판단 정도는 애플리케이션에 따라 다릅니다만, 통상 평균값에서 3 표준편차 범위를 넘을 경우 이상치로 간주합니다 (데이터가 정규분포를 따른다고 가정했을 때, 3표준편차 범위(μ±3σ)는 전체 데이터셋의 99.73%에 해당하며, 따라서 0.27%에 해당하는 데이터를 이상치로 볼 수 있다는 의미입니다).
Amazon SageMaker의 RCF 알고리즘은 우선 학습 데이터에서 임의로 샘플을 추출하여 작업을 수행합니다. 학습 데이터가 지나치게 커서 머신 한 대에 올리기 어려울 경우, reservoir sampling 기법을 이용하여 데이터 스트림으로부터 샘플 데이터를 효율적으로 추출합니다 (reservoir sampling에 대한 자세한 내용은 https://en.wikipedia.org/wiki/Reservoir_sampling 를 참고하시기 바랍니다).
이를 통해서 서브 샘플 데이터들이 Random Cut Forest를 구성하는 트리 각각에 분포하게 됩니다. 각각의 서브 샘플 데이터는 바운딩 박스를 랜덤하게 분할하는 식으로 만들어진 이진 트리를 구성하게 되는데, 이러한 트리 구성은 각 리프 노드(즉, 트리 맨 끝의 터미널 노드)가 데이터를 하나만 담고 있는 바운딩 박스로 만들어질 때까지 계속 반복됩니다.
입력 데이터에 할당된 이상치 스코어는 포레스트를 구성하는 트리의 평균 깊이(depth)와 반비례합니다. RCF 알고리즘에 대한 더 자세한 내용은 Amazon SageMaker RCF 문서를 참조하시기 바랍니다. 내부 알고리즘은 이 블로그의 맨 끝에 있는 참고 문헌의 설명을 바탕으로 구현되었습니다.
실습 예제: 택시 승차 데이터를 통한 뉴욕 시의 사건/사고 탐지
이제 뉴욕 시의 택시 승차 현황을 6개월 동안 수집한 데이터를 가지고 Amazon SageMaker의 RCF 알고리즘을 어떻게 사용하면 되는지 함께 알아보겠습니다. 이 데이터셋은 Numenta Anomaly Benchmakr (NAB) New York City Taxi dataset 에서 다운 받을 수 있습니다. 아래 정리한 예제 코드를 이용해서, SageMaker RCF 모델을 학습시킨 다음 승차 데이터에서 이상치를 탐지해보겠습니다. 예제 코드에 대한 자세한 내용은 깃허브 노트북을 참고하시기 바랍니다.
Amazon S3를 기반으로 한 데이터 수집, 검토, 저장
먼저 NAB 데이터셋을 다운 받아서 그래프로 그려봅시다. 이 데이터셋은 6개월 치 뉴욕 시 택시 승차 데이터로 구성되어 있으며, 각 데이터 포인트는 30분 동안 승차 횟수를 집계한 결과를 의미합니다.

예상대로, 택시 승차 횟수가 대략 일정한 주기를 보이고 있습니다. 하루 중 대체로 출퇴근 시간에 통행량이 높게 나타나고 한 밤중에는 낮은 값을 보이고 있습니다. 또 평일이 주말보다 승차 횟수가 높을 것으로 주 단위 패턴을 예상해볼 수 있습니다.
위의 그래프를 조금 더 자세히 들여다보면, 몇 가지 이상한 패턴을 보이는 데이터 포인트를 찾을 수 있습니다. 이를 통해서, 사람은 놀라운 시각적 능력을 지니고 있으며 때문에 수백 만 년에 걸쳐 대단히 뛰어난 패턴-추적 능력을 발달시켜 왔다는 점도 생각해볼 수 있겠습니다.
특히, 이상치 데이터가 승차 횟수의 급격한 증가/감소, 또는 주기적인 흐름과는 다른 패턴 등으로 나타난다는 점을 알 수 있습니다. 이들 중 몇몇은 특정 이벤트와 관련이 있을 수 있는데, 예를 들면 뉴욕 시 마라톤 경기 (t=5954), 12월31일 연말연시 이벤트 (t=8833), 대규모 눈폭풍 (t=10090) 등 입니다.
Amazon SageMaker의 다른 알고리즘과 마찬가지로, 모델 학습 작업은 RecordIO prodobuf 포맷으로 인코딩한 데이터에서 가장 좋은 성능을 나타냅니다. 아래의 코드를 참고해서, CSV-포맷의 원본 데이터를 변환한 다음 이 결과를 Amazon S3 버킷에 저장합니다.
모델 학습(Training)
다운받은 데이터셋을 대상으로 SageMaker 의 Random Cut Forest 모델을 학습시키기에 앞서, 몇 가지 트레이닝 잡 파라미터 (training job parameter)를 지정해야 합니다. 이를테면 (1) Amazon SageMaker의 Random Cut Forest 알고리즘을 위한 Amazon Elastic Container Registry (ECR) 도커(Docker) 컨테이너, (2) 학습 데이터의 위치, (3) 알고리즘을 실행시킬 인스턴스 타입 같은 것들입니다. 또 알고리즘에서 필요한 하이퍼파라미터도 지정해야 합니다. Amazon SageMaker의 RCF 알고리즘에는 num_trees와 num_samples_per_tree 와 같은 2가지 주요 하이퍼파라미터가 있습니다.
num_trees 라는 하이퍼파라미터는 RCF 모델에서 사용될 트리의 갯수를 설정합니다. 트리 각각은 학습 데이터의 서브샘플을 이용해서 개별적으로 모델을 학습하고, (트리의 깊이(depth)에 반비례하는) 해당 데이터에 대한 이상치 스코어를 결과로 리턴합니다. 전체 RCF 모델에 의해 데이터에 할당된 이상치 스코어는 모델에 포함되어 있는 트리를 통해 계산된 이상치 스코어들의 평균값입니다.
num_samples_per_tree 라는 하이퍼파라미터는 임의로 샘플링된 학습 데이터가 트리 각각에 얼마나 많이 할당되는지를 나타냅니다. num_samples_per_tree 값을 잘 선정하는 방법 중 하나로 데이터셋에 포함된 이상치의 예상 비율에 역수를 취하는 것을 생각해볼 수 있습니다. 더 자세한 내용은 Amazon SageMaker RCF – How it Works를 참고하시기 바랍니다.
아래의 코드를 실행하면 Amazon SageMaker RCF 모델에서 50개의 트리, 각 트리별로 200개의 서브샘플을 할당하고 이를 기반으로 학습(training)을 진행할 수 있습니다.
이상 패턴 스코어 예측
이제 학습 데이터 각각에 대한 이상치 스코어를 계산하는 (학습이 완료된) 모델을 이용합니다. 다른 Amazon SageMaker 알고리즘과 마찬가지로, 앞에서 생성한 모델을 이용하는 추론 엔드포인트(inference endpoint)부터 먼저 생성합니다.
다음으로, 각 데이터 포인트와 관련된 이상치 스코어를 가지고 학습 데이터 전체를 대상으로 추론(inference)를 수행합니다. 이상치를 분류하기 위해 여기서는 간단하고 통상적인 기법을 사용하겠습니다. 즉 평균값에서 3 표준편차 범위를 넘는 모든 이상치 스코어에 대해 이상치로 간주합니다. 사실 이보다 더 좋은 기법이 있긴 하지만, 이번 데모에서는 이 정도 기법만으로도 충분할 것 같습니다.
끝으로, 이상치로 판단되는 데이터들을 하이라이트시켜서 (굵은 점으로 표시) 택시 승차 데이터와 함께 스코어를 그래프에 표시합니다.

위의 그림은 SageMaker RCF 알고리즘이 이상치 데이터를 잡아낸 결과를 보여주고 있습니다. t=5954 에 있는 뉴욕 마라톤 행사, t=8833 의 연말연시(Happy new year) 이벤트, t=10090의 대규모 눈폭풍 사태 등을 주요 사례로 생각해볼 수 있습니다. 사실 사용할 수 있는 데이터 자체가 매우 적었지만, 시계열 패턴에서 정밀한 변화를 감지해내는 모델 성향 결과를 통해 이상치 스코어 예측 결과 중 이상치에 해당하는 것들을 찾아냈습니다.
전처리 방법: shingling을 이용하여 정확도를 향상시키기
기계 학습 작업에서, 정확도와 성능을 향상시키기 위해서는 보통 전처리 작업을 필요로 합니다. 이상 탐지 알고리즘에서, shingling 은 연속성을 지닌 데이터에서 길이 s만큼의 시퀀스를 s-차원의 벡터로 변환함으로써 1차원 데이터를 s-차원 데이터로 바꾸는 기술입니다 (참고: w-shingling in Wiki).
이렇게 하면 정기적으로 나타나는 변화를 탐지하기도 좋고, 이상치 스코어의 원래 값에서 작은-규모의 노이즈를 필터링 하는데도 효과적입니다. 다만, shingle 사이즈가 너무 작을 경우, Random Cut Forest 알고리즘이 데이터의 작은 변화에도 심하게 영향을 받을 수 있다는 점에 주의하시기 바랍니다.
앞의 택시 승차 데이터에 대한 그래프를 보면 이해가 쉬우실 겁니다. 반면 shingle 사이즈가 너무 크면 작은 크기의 이상치를 탐지하지 못할 수 있습니다. SageMaker RCF 하이퍼파라미터인 num_trees와 num_samples_per_tree 와 같이, 주어진 문제에 따라 shingle 사이즈에 대한 최적값은 다 다를 수 있습니다.
다음 그림은 1차원 데이터 스트림을 4차원 shingle로 변환하는 shingling 기법을 설명하고 있습니다. 첫 번째 shingle 데이터는 데이터 스트림 중 1, 2, 3, 4 번째 데이터로 구성되어 있고, 두 번째 shingle 데이터는 그 다음 4 개의 데이터 (데이터 스트림의 2, 3, 4, 5 번째 데이터)로 구성되어 있습니다. 이어지는 shingle 데이터도 같은 방식으로 변환됨을 알 수 있습니다.

뉴욕 시 (NYC) 택시 승차 데이터에서 각 데이터 포인트는 30분 간격으로 승차 기록을 집계한 정보입니다. 따라서 택시 승차가 매일 일정하다고 예상하는 것 역시 논리적으로 봐도 문제가 없을 것입니다. 예를 들면 평일에는 승차 횟수가 거의 비슷하게 나타나는 식이겠죠. 즉, 월요일과 화요일의 승차 횟수가 별 차이가 없을 것입니다. 따라서 shingle 사이즈를 48로 잡아보겠습니다 (24 시간 = 48 데이터 포인트 * 0.5 시간 (데이터 포인트 집계 단위). 이상의 내용을 바탕으로 뉴욕 시 (NYC) 택시 승차 데이터를 shingle 변환하는 함수를 다음과 같이 작성합니다.
다음 그래프는 원본 데이터셋에 shingle 변환을 적용한 후, Amazon SageMaker의 학습 잡(training job), 추론 잡(inference job)을 실행해서 얻은 이상치 스코어를 표시한 결과입니다.

얼핏 봐도 알 수 있듯이, 특정 시점의 대규모 이상치값을 훨씬 더 잘 찾아냈음을 알 수 있습니다. 예를 들면 t=10090에서 대규모 눈폭풍 상태가 일어났을 때 택시 승차 횟수가 급격하게 줄어든 경우처럼 말입니다. 레이블 정보가 있는 테스트 데이터가 있으면, SageMaker RCF 알고리즘을 이용해서 정밀도(precision), 재현율(recall), F1-스코어 같은 정확도 측정 결과를 얻을 수 있습니다. 이러한 측정 결과를 분석해서 num_trees와 num_samples_per_tree 의 최적치를 결정할 수도 있고, 정확도 스코어를 최대로 높일 수도 있습니다.
벤치마크 테스트
Amazon SageMaker RCF 알고리즘은 피처 갯수, 데이터셋 크기, EC2 인스턴스의 갯수에 비례해서 좋은 확장성을 지니고 있습니다. 이 섹션에서는 SageMaker RCF 알고리즘의 성능, 정확도, 확장성에 대한 벤치마크 테스트 결과를 소개합니다. 벤치마크 테스트를 위해 사용한 실험용 데이터는 (정상(normal) 데이터를 의미하는) 가우시안 분포를 따르는 데이터 클러스터 2개와, (이상(anomalous) 데이터를 의미하는) 작은 크기의 가우시안 분포를 따르는 데이터 클러스터 1개로 구성되어 있습니다.
특히, 이상 데이터에 해당하는 데이터 클러스터 1개는 정상 데이터에 해당하는 데이터 클러스터 2개의 사이에 위치해 있습니다. 이상치 데이터 포인트는 (벤치마크 테스트를 위해 생성한) 각 데이터셋에 약 0.5% 만큼 포함되도록 했습니다. 모든 실험은 ml.m4.xlarge 인스턴스 상에서 수행했습니다.
성능
우리는 다양한 기능 갯수와 데이터 사이즈로 구성된 데이터셋을 이용하여 SageMaker RCF 알고리즘의 성능을 측정했습니다. 다음 그래프는 RCF 모델을 학습시키기 위해 필요한 시간을 측정한 결과입니다. 실험에서 설정한 하이퍼파라미터는num_trees=100, num_samples_per_tree=256 입니다. 학습 시간이 데이터셋 크기 증가에 따라 선형적으로 증가하는 점에 주목하시기 바랍니다.

SageMaker RCF 알고리즘은 이상치 예측에 있어서도 매우 효율적임을 알 수 있습니다. 다음 그래프는 피처의 차원에 따른 추론 쓰루풋을 측정한 결과입니다.
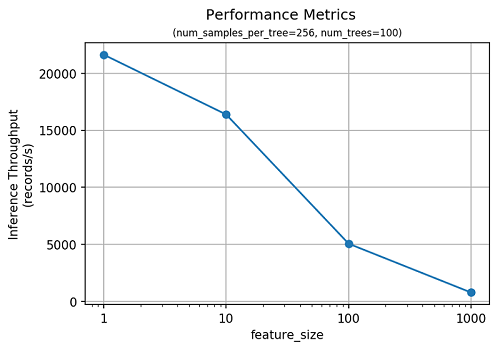
정확도
이상 탐지 분야에서, 정확도를 판단하는데 사용되는 몇 가지 표준적인 측정기준이 있습니다. 정밀도(precision)는 알고리즘을 통해 이상치로 예측된 결과와 실제로 올바르게 탐지된 이상치의 비율을 의미합니다. 재현율(recall)은 파악된 이상치 전체 대비 올바르게 탐지된 이상치의 비율을 의미합니다. F1 스코어는 정밀도(precision)와 재현율(recall)의 조화 평균(harmonic mean)으로 계산합니다.
다음 그래프에서는 피처 갯수 10개 (즉, 10 차원), 레코드 갯수 1억개로 구성된 데이터셋을 대상으로, 하이퍼파라미터 num_samples_per_tree의 값에 따른 정확도를 측정한 결과를 보여주고 있습니다. 앞에서 설명한 것처럼, num_samples_per_tree와 데이터셋에서 이상치의 비율이 대체로 반비례한다는 것을 이 실험 결과를 통해 알 수 있습니다.
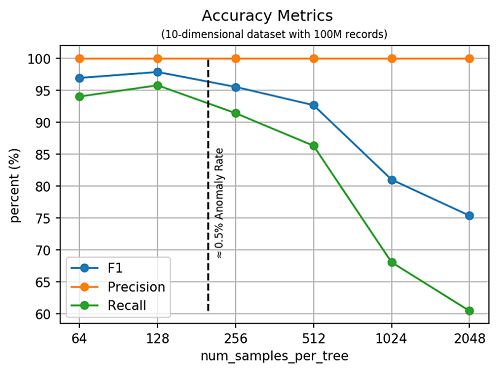
특히, 실험용 데이터셋에서 (우리가 설정한 이상치의 비율 근처에서) num_samples_per_tree의 F1 스코어가 최고치를 나타냈다는 점에 주목하시기 바랍니다. 우리는 SageMaker RCF 알고리즘을 scikit-learn의 Isolation Forest(IF) 알고리즘과도 정확도 측면에서 비교해 보았습니다. 데이터셋 크기가 작은 경우, 두 알고리즘 의 정확도는 큰 차이를 보이지는 않았습니다. 10,000개의 레코드셋, 10차원으로 구성된 데이터셋에 대해 RCF, IF 알고리즘 모두 99.6%의 F1 스코어를 보였습니다. 하지만, scikit-learn의 IF 알고리즘은 이번 벤치마크 테스트에서 사용된 대규모 데이터셋에 대해서는 제대로 동작하지 못했습니다.
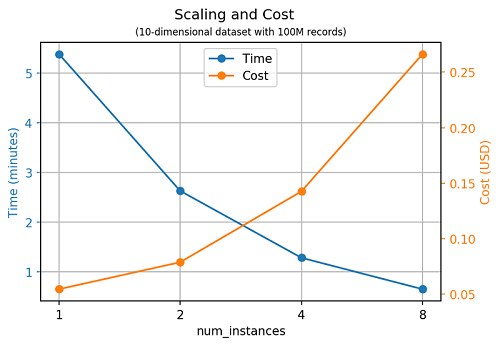
확장성
SageMaker RCF 알고리즘은 인스턴스의 갯수에 따라서도 완벽하게 뛰어난 확장성을 보여주고 있습니다. 인스턴스의 갯수를 2배로 늘리면 모델 학습에 필요한 시간이 대략 절반으로 줄어든다는 것을 아래 그래프를 통해 알 수 있습니다.
맺으면서
Amazon SageMaker는 대규모 머신 러닝 모델을 학습시키고 배포하는 문제를 해결하기 위한 완전 관리형, end-to-end 솔루션입니다. Amazon SageMaker RCF 알고리즘은 여러분이 Amazon SageMaker를 이용해서 이상 탐지 문제를 잘 해결할 수 있도록 해줍니다.
이 글에서는 작은 크기의 1차원 시계열 데이터셋을 이용한 예제를 소개했습니다. 하지만, Amazon SageMaker RCF 알고리즘은 대량의 데이터셋, 피처가 많은 데이터셋을 대상으로 이상 탐지를 하는데 있어 특히 뛰어난 성능을 지니고 있습니다. AWS AI 알고리즘 팀은 여러분이 Amazon SageMaker RCF 알고리즘을 통해 혁신을 이루고, 보다 나은 개선 효과를 얻으시기를 진심으로 바랍니다.
참고 문헌
[1] Sudipto Guha, Nina Mishra, Gourav Roy, and Okke Schrijvers. “Robust random cut forest based anomaly detection on streams.” In International Conference on Machine Learning, pp. 2712-2721. 2016.
[2] Byung-Hoon Park, George Ostrouchov, Nagiza F. Samatova, and Al Geist. “Reservoir-based random sampling with replacement from data stream.” In Proceedings of the 2004 SIAM International Conference on Data Mining, pp. 492-496. Society for Industrial and Applied Mathematics, 2004.
이 글은 AWS Machine Learning 블로그의 Use the built-in Amazon SageMaker Random Cut Forest algorithm for anomaly detection의 한국어 번역으로 AWS 코리아 남궁 영환 AI 전문 솔루션즈 아키텍트께서 제공해 주셨습니다.