Что такое логистическая регрессия?
Что такое логистическая регрессия?
Логистическая регрессия — это метод анализа данных, который использует математику для поиска взаимосвязей между двумя факторами данных. Затем эта взаимосвязь используется для прогнозирования значения одного из этих факторов на основе другого. Предсказание обычно имеет конечное количество результатов, например «да» или «нет».
Например, предположим, вы хотите угадать, нажмет ли посетитель вашего сайта кнопку оформления заказа в своей корзине или нет. Логистический регрессионный анализ учитывает поведение посетителей в прошлом, например время, проведенное на сайте, и количество товаров в корзине. Он определяет, что в прошлом, если посетители проводили на сайте более пяти минут и добавляли более трех товаров в корзину, они нажимали кнопку оформления заказа. Используя эту информацию, функция логистической регрессии может предсказать поведение нового посетителя веб-сайта.
Почему логистическая регрессия важна?
Логистическая регрессия — важный метод в области искусственного интеллекта и машинного обучения (AI/ML). Модели машинного обучения – это программы, которые можно обучить выполнению сложных задач обработки данных без вмешательства человека. Модели машинного обучения, построенные с использованием логистической регрессии, помогают организациям получать полезную информацию из своих бизнес-данных. Они могут использовать эти данные для прогнозного анализа, чтобы снизить эксплуатационные расходы, повысить эффективность и ускорить масштабирование. Например, компании могут выявить закономерности, которые улучшают удержание сотрудников или приводят к более прибыльному дизайну продукта.
Ниже мы перечислим некоторые преимущества использования логистической регрессии по сравнению с другими методами машинного обучения.
Простота
Модели логистической регрессии математически менее сложны, чем другие методы машинного обучения. Таким образом, вы можете внедрить их, даже если никто из вашей команды не обладает глубоким опытом в области машинного обучения.
Скорость
Модели логистической регрессии могут обрабатывать большие объемы данных с высокой скоростью, поскольку они требуют меньших вычислительных мощностей, таких как память и способность обработки. Это делает их идеальными для организаций, которые начинают с проектов машинного обучения, чтобы быстро добиться успеха.
Гибкость
Логистическую регрессию можно использовать для поиска ответов на вопросы, которые имеют два или более конечных результатов. Ее также можно использовать для предварительной обработки данных. Например, с помощью логистической регрессии можно сортировать данные с большим диапазоном значений, например банковские транзакции, в меньший конечный диапазон значений. Затем можно обработать этот небольшой набор данных, используя другие методы машинного обучения для более точного анализа.
Наглядность
Логистический регрессионный анализ позволяет разработчикам лучше понять внутренние программные процессы, чем другие методы анализа данных. Устранение неполадок и исправление ошибок также упрощаются, поскольку вычисления менее сложны.
Каковы области применения логистической регрессии?
Логистическая регрессия имеет несколько реальных применений в самых разных отраслях.
Обрабатывающая промышленность
Производственные компании используют логистический регрессионный анализ для оценки вероятности выхода из строя деталей оборудования. Затем они планируют графики технического обслуживания на основе этой оценки, чтобы свести к минимуму будущие сбои.
Здравоохранение
Медицинские исследователи планируют профилактику и лечение, прогнозируя вероятность заболевания у пациентов. Они используют модели логистической регрессии для сравнения влияния семейного анамнеза или генов на заболевания.
Финансы
Финансовые компании должны анализировать финансовые операции на предмет мошенничества и оценивать заявки на получение кредита и страховые заявки на предмет риска. Эти проблемы подходят для модели логистической регрессии, поскольку они имеют дискретные результаты, такие как высокий риск или низкий риск, мошенничество или его отсутствие.
Маркетинг
Инструменты онлайн-рекламы используют модель логистической регрессии, чтобы предсказать, будут ли пользователи нажимать на рекламу. В результате маркетологи могут анализировать реакцию пользователей на различные слова и изображения и создавать высокоэффективные рекламные объявления, которые будут привлекать клиентов.
Как работает регрессионный анализ?
Логистическая регрессия – это один из нескольких различных методов регрессионного анализа, которые специалисты по обработке данных обычно используют в машинном обучении. Чтобы понять логистическую регрессию, мы должны сначала понять базовый регрессионный анализ. Ниже мы используем пример линейного регрессионного анализа, чтобы продемонстрировать, как работает регрессионный анализ.
Определите вопрос
Любой анализ данных начинается с делового вопроса. Для логистической регрессии вам следует сформулировать вопрос так, чтобы получить конкретные результаты:
- Влияют ли дождливые дни на ежемесячные продажи? (да или нет)
- Какой тип деятельности по кредитной карте осуществляет клиент? (правомерный, мошеннический или потенциально мошеннический)
Соберите исторические данные
После определения вопроса вам необходимо определить факторы данных, которые задействованы. Затем вы соберете прошлые данные по всем факторам. Например, чтобы ответить на первый вопрос, показанный выше, вы можете отследить количество дождливых дней и ежемесячные данные о продажах за каждый месяц за последние три года.
Обучите модель регрессионного анализа
Вы будете обрабатывать исторические данные с помощью программного обеспечения для регрессии. Программа обработает различные точки данных и свяжет их математически с помощью уравнений. Например, если количество дождливых дней за три месяца равно 3, 5 и 8, а количество продаж в этих месяцах равно 8, 12 и 18, алгоритм регрессии свяжет коэффициенты с уравнением:
Количество продаж = 2* (количество дождливых дней) + 2
Делайте прогнозы для неизвестных значений
Для неизвестных значений программа использует уравнение для прогнозирования. Если вы знаете, что в июле будет дождь в течение шести дней, программное обеспечение оценит стоимость продажи в июле в 14.
Как работает модель логистической регрессии?
Чтобы понять модель логистической регрессии, давайте сначала разберемся с уравнениями и переменными.
Уравнения
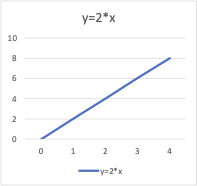
В математике уравнения дают связь между двумя переменными: x и y. Эти уравнения или функции можно использовать для построения графика вдоль осей x и y, введя разные значения x и y. Например, если вы построили график для функции y = 2* x, вы получите прямую линию, как показано ниже. Поэтому эту функцию также называют линейной функцией.
Переменные
В статистике переменные – это факторы данных или атрибуты, значения которых различаются. Для любого анализа определенные переменные являются независимыми или объясняющими переменными. Эти атрибуты являются причиной результата. Другие переменные являются зависимыми или переменными ответа; их значения зависят от независимых переменных. В целом логистическая регрессия исследует, как независимые переменные влияют на одну зависимую переменную, рассматривая исторические значения обеих переменных.
В приведенном выше примере x называется независимой переменной, предикторной переменной или объясняющей переменной, потому что она имеет известное значение. Y называется зависимой переменной, переменной результата или переменной отклика, потому что ее значение неизвестно.
Функция логистической регрессии
Логистическая регрессия – это статистическая модель, которая использует логистическую или логитную функцию в математике в качестве уравнения между x и y. Логитная функция отображает y как сигмовидную функцию от x.
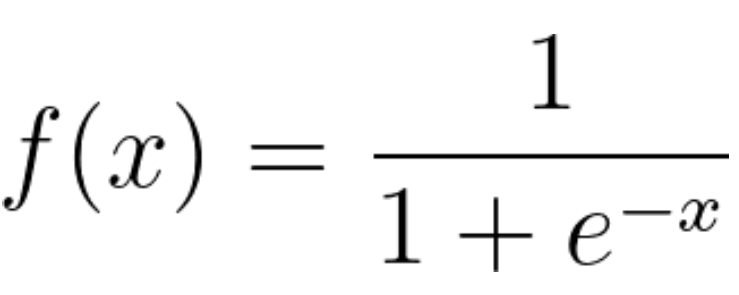
Если вы построили это уравнение логистической регрессии, вы получите S-образную кривую, как показано ниже.
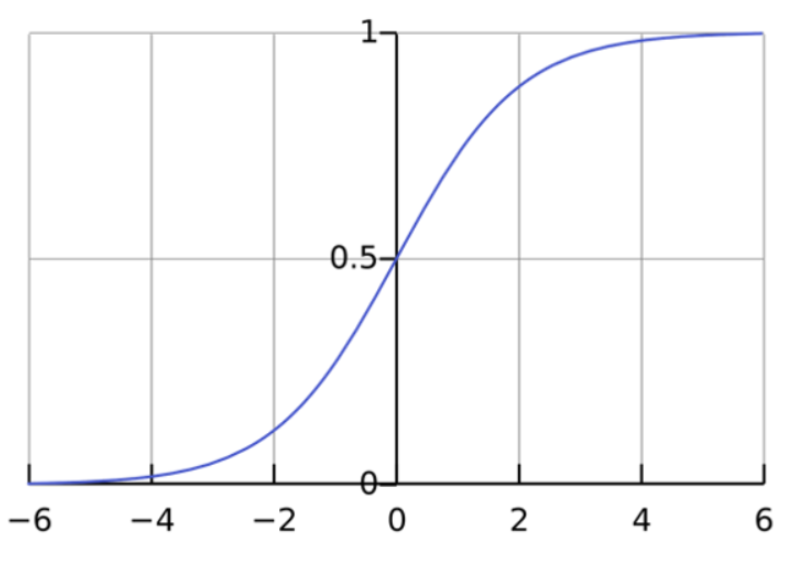
Как вы можете видеть, логитная функция возвращает только значения от 0 до 1 для зависимой переменной, независимо от значений независимой переменной. Так логистическая регрессия оценивает значение зависимой переменной. Методы логистической регрессии также моделируют уравнения между несколькими независимыми переменными и одной зависимой переменной.
Логистический регрессионный анализ с несколькими независимыми переменными
Во многих случаях несколько независимых переменных влияют на значение зависимой переменной. Для моделирования таких наборов входных данных формулы логистической регрессии предполагают линейную зависимость между различными независимыми переменными. Вы можете изменить функцию сигмоида и вычислить конечную выходную переменную как
y = f(β0 + β1x1 + β2x2+… βnxn)
Символ β представляет коэффициент регрессии. Логитная модель может вычислять эти значения коэффициентов в обратном порядке, если предоставить ей достаточно большой экспериментальный набор данных с известными значениями как зависимых, так и независимых переменных.
Логарифмические коэффициенты
Логитная модель также может определять отношение успеха к неудаче или логарифмические коэффициенты. Например, если вы играли в покер с друзьями и выиграли четыре матча из 10, ваши шансы на выигрыш составляют четыре шестых или четыре из шести, что соответствует соотношению вашего успеха к неудаче. Вероятность выигрыша, с другой стороны, составляет четыре из 10.
Математически ваши шансы с точки зрения вероятности равны p/(1 - p), а ваши логарифмические коэффициенты – log (p/(1 - p)). Логистическую функцию можно представить в виде логарифмических коэффициентов, как показано ниже:
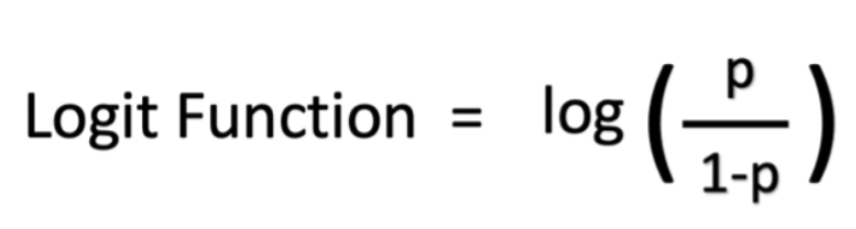
Какие существуют типы логистического регрессионного анализа?
Существует три подхода к логистическому регрессионному анализу, основанному на результатах зависимой переменной.
Бинарная логистическая регрессия
Бинарная логистическая регрессия хорошо подходит для задач бинарной классификации, которые имеют только два возможных результата. Зависимая переменная может иметь только два значения, например yes и no или 0 и 1.
Несмотря на то, что логистическая функция вычисляет диапазон значений от 0 до 1, модель бинарной регрессии округляет ответ до ближайших значений. Обычно ответы ниже 0,5 округляются до 0, а ответы выше 0,5 – до 1, так что логистическая функция возвращает двоичный результат.
Многочленная логистическая регрессия
Многочленная регрессия может анализировать проблемы, которые имеют несколько возможных результатов, если количество результатов ограничено. Например,так можно предсказать, вырастут ли цены на жилье на 25 %, 50 %, 75 % или 100 % на основе данных о населении, но не можно предсказать точную стоимость дома.
Многочленная логистическая регрессия работает путем сопоставления значений результатов с различными значениями от 0 до 1. Поскольку логистическая функция может возвращать диапазон непрерывных данных, таких как 0,1, 0,11, 0,12 и т. д., многочленная регрессия также группирует выходные данные с максимально близкими возможными значениями.
Порядковая логистическая регрессия
Порядковая логистическая регрессия, или упорядоченная логитная модель, является особым типом многочленной регрессии для задач, в которых числа представляют собой ранги, а не фактические значения. Например, вы можете использовать порядковую регрессию для прогнозирования ответа на вопрос опроса, в котором клиентам предлагается оценить ваш сервис как плохой, удовлетворительный, хороший или отличный на основе числового значения, такого как количество товаров, которые они приобрели у вас за год.
Как логистическая регрессия сравнивается с другими методами машинного обучения?
Двумя распространенными методами анализа данных являются линейный регрессионный анализ и глубокое обучение.
Анализ линейной регрессии
Как объяснялось выше, линейная регрессия моделирует взаимосвязь между зависимыми и независимыми переменными с помощью линейной комбинации. Уравнение линейной регрессии
y= β0X0 + β1X1 + β2X2+… βnXn+ ε, где от β1 до βn и ε – коэффициенты регрессии
Логистическая регрессия против линейной
Линейная регрессия предсказывает непрерывную зависимую переменную с использованием заданного набора независимых переменных. Непрерывная переменная может иметь диапазон значений, например цену или возраст. Таким образом, линейная регрессия может предсказать фактические значения зависимой переменной. Она может ответить на такие вопросы, как «Какой будет цена на рис через 10 лет?»
В отличие от линейной регрессии, логистическая регрессия – это алгоритм классификации. Она не может предсказать фактические значения для непрерывных данных, однако может ответить на такие вопросы, как «Вырастет ли цена на рис на 50 % за 10 лет?».
Глубокое обучение
Глубокое обучение использует нейронные сети или программные компоненты, имитирующие человеческий мозг, для анализа информации. Вычисления глубокого обучения основаны на математической концепции векторов.
Логистическая регрессия против глубокого обучения
Логистическая регрессия менее сложна и требует меньших вычислительных ресурсов, чем глубокое обучение. Что еще более важно, вычисления глубокого обучения не могут быть исследованы или изменены разработчиками из-за их сложной машинной природы. С другой стороны, расчеты логистической регрессии прозрачны и их легче устранять.
Как провести логистический регрессионный анализ на AWS?
Логистическую регрессию можно запустить на AWS с помощью Amazon SageMaker. SageMaker – это полностью управляемый сервис машинного обучения со встроенными алгоритмами линейной и логистической регрессии, а также несколькими другими пакетами статистического программного обеспечения.
- Каждый специалист по обработке данных может использовать SageMaker для быстрой подготовки, создания, обучения и развертывания моделей логистической регрессии.
- SageMaker берет на себя большую часть работы на каждом этапе логистической регрессии, чтобы упростить разработку высококачественных моделей.
- SageMaker предоставляет все компоненты, необходимые для логистической регрессии, в одном наборе инструментов, чтобы вы могли быстрее, проще и с меньшими затратами доставлять модели в производство.
Начните с логистической регрессии, создав аккаунт AWS уже сегодня.