AWS Big Data Blog
Category: AWS Glue

Securely share your data across AWS accounts using AWS Lake Formation
Data lakes have become very popular with organizations that want a centralized repository that allows you to store all your structured data and unstructured data at any scale. Because data is stored as is, there is no need to convert it to a predefined schema in advance. When you have new business use cases, you […]

Enrich datasets for descriptive analytics with AWS Glue DataBrew
Data analytics remains a constantly hot topic. More and more businesses are beginning to understand the potential their data has to allow them to serve customers more effectively and give them a competitive advantage. However, for many small to medium businesses, gaining insight from their data can be challenging because they often lack in-house data […]

Query cross-account AWS Glue Data Catalogs using Amazon Athena
Many AWS customers rely on a multi-account strategy to scale their organization and better manage their data lake across different projects or lines of business. The AWS Glue Data Catalog contains references to data used as sources and targets of your extract, transform, and load (ETL) jobs in AWS Glue. Using a centralized Data Catalog […]

Ibotta builds a self-service data lake with AWS Glue
This is a guest post co-written by Erik Franco at Ibotta. Ibotta is a free cash back rewards and payments app that gives consumers real cash for everyday purchases when they shop and pay through the app. Ibotta provides thousands of ways for consumers to earn cash on their purchases by partnering with more than […]

Effective data lakes using AWS Lake Formation, Part 2: Creating a governed table for streaming data sources
February 2023: The content of this blog post can be now be found on AWS Lake Formation public documentation. Please refer to it instead. We announced the general availability of AWS Lake Formation transactions, row-level security, and acceleration at AWS re:Invent 2021. In Part 1 of this series, we explained how to set up a […]

Simplify Snowflake data loading and processing with AWS Glue DataBrew
May 2024: Connecting to Snowflake as a data source is now supported natively. To learn more, visit our documentation. Historically, inserting and retrieving data from a given database platform has been easier compared to a multi-platform architecture for the same operations. To simplify bringing data in from a multi-database platform, AWS Glue DataBrew supports bringing […]
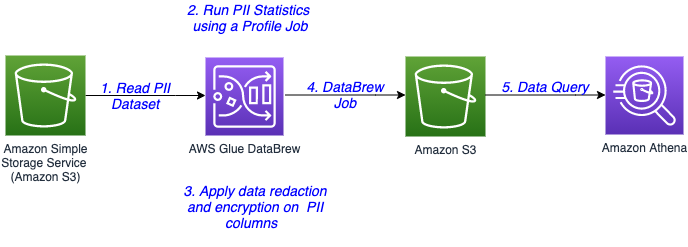
Introducing PII data identification and handling using AWS Glue DataBrew
AWS Glue DataBrew, a visual data preparation tool, now allows users to identify and handle sensitive data by applying advanced transformations like redaction, replacement, encryption, and decryption on their personally identifiable information (PII) data, and other types of data they deem sensitive. With exponential growth of data, companies are handling huge volumes and a wide […]

Improve Amazon Athena query performance using AWS Glue Data Catalog partition indexes
The AWS Glue Data Catalog provides partition indexes to accelerate queries on highly partitioned tables. In the post Improve query performance using AWS Glue partition indexes, we demonstrated how partition indexes reduce the time it takes to fetch partition information during the planning phase of queries run on Amazon EMR, Amazon Redshift Spectrum, and AWS […]
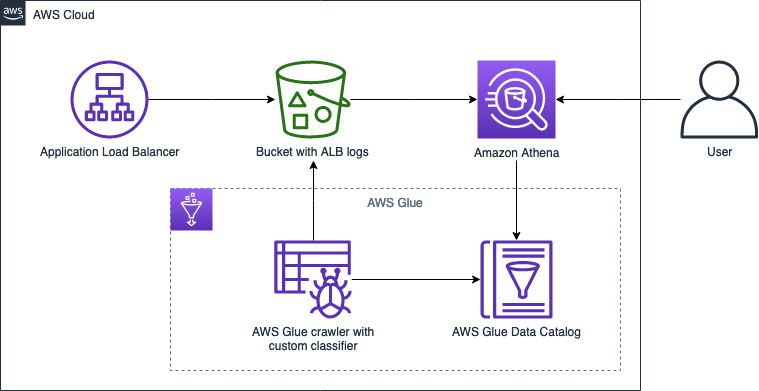
Catalog and analyze Application Load Balancer logs more efficiently with AWS Glue custom classifiers and Amazon Athena
You can query Application Load Balancer (ALB) access logs for various purposes, such as analyzing traffic distribution and patterns. You can also easily use Amazon Athena to create a table and query against the ALB access logs on Amazon Simple Storage Service (Amazon S3). (For more information, see How do I analyze my Application Load […]
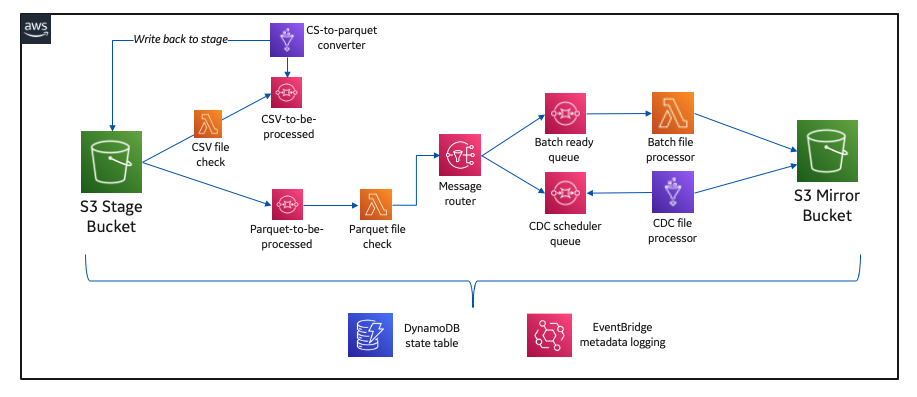
How GE Aviation built cloud-native data pipelines at enterprise scale using the AWS platform
This post was co-written with Alcuin Weidus, Principal Architect from GE Aviation. GE Aviation, an operating unit of GE, is a world-leading provider of jet and turboprop engines, as well as integrated systems for commercial, military, business, and general aviation aircraft. GE Aviation has a global service network to support these offerings. From the turbosupercharger […]