AWS Big Data Blog
Stream data from relational databases to Amazon Redshift with upserts using AWS Glue streaming jobs
Traditionally, read replicas of relational databases are often used as a data source for non-online transactions of web applications such as reporting, business analysis, ad hoc queries, operational excellence, and customer services. Due to the exponential growth of data volume, it became common practice to replace such read replicas with data warehouses or data lakes to have better scalability and performance. In most real-world use cases, it’s important to replicate the data from a source relational database to the target in real time. Change data capture (CDC) is one of the most common design patterns to capture the changes made in the source database and relay them to other data stores.
AWS offers a broad selection of purpose-built databases for your needs. For analytic workloads such as reporting, business analysis, and ad hoc queries, Amazon Redshift is powerful option. With Amazon Redshift, you can query and combine exabytes of structured and semi-structured data across your data warehouse, operational database, and data lake using standard SQL.
To achieve CDC from Amazon Relational Database Service (Amazon RDS) or other relational databases to Amazon Redshift, the simplest solution is to create an AWS Database Migration Service (AWS DMS) task from the database to Amazon Redshift. This approach works well for simple data replication. To have more flexibility to denormalize, transform, and enrich the data, we recommend using Amazon Kinesis Data Streams and AWS Glue streaming jobs between AWS DMS tasks and Amazon Redshift. This post demonstrates how this second approach works in a customer scenario.
Example use case
For our example use case, we have a database that stores data of a fictional organization that holds sports events. We have three dimension tables: sport_event, ticket, and customer, and one fact table: ticket_activity. The table sport_event stores sport type (such as baseball or football), date, and location. The table ticket stores seat level, location, and ticket policy for the target sport event. The table customer stores individual customer names, email addresses, and phone numbers, which are sensitive information. When a customer buys a ticket, the activity (e.g. who purchased the ticket) is recorded in the table ticket_activity. One record is inserted into the table ticket_activity every time a customer buys a ticket, so new records are being ingested into this fact table continuously. The records ingested into the table ticket_activity are only updated when needed, when an administrator maintains the data.
We assume a persona, a data analyst, who is responsible for analyzing trends of the sports activity from this continuous data in real time. To use Amazon Redshift as a primary data mart, the data analyst needs to enrich and clean the data so that users like business analysts can understand and utilize the data easily.
The following are examples of the data in each table.
The following is the dimension table sport_event.
| event_id | sport_type | start_date | location | |
| 1 | 35 | Baseball | 9/1/2021 | Seattle, US |
| 2 | 36 | Baseball | 9/18/2021 | New York, US |
| 3 | 37 | Football | 10/5/2021 | San Francisco, US |
The following is the dimension table ticket (the field event_id is the foreign key for the field event_id in the table sport_event).
| ticket_id | event_id | seat_level | seat_location | ticket_price | |
| 1 | 1315 | 35 | Standard | S-1 | 100 |
| 2 | 1316 | 36 | Standard | S-2 | 100 |
| 3 | 1317 | 37 | Premium | P-1 | 300 |
The following is the dimension table customer.
| customer_id | name | phone | ||
| 1 | 222 | Teresa Stein | teresa@example.com | +1-296-605-8486 |
| 2 | 223 | Caleb Houston | celab@example.com | 087-237-9316×2670 |
| 3 | 224 | Raymond Turner | raymond@example.net | +1-786-503-2802×2357 |
The following is the fact table ticket_activity (the field purchased_by is the foreign key for the field customer_id in the table customer).
| ticket_id | purchased_by | created_by | updated_by | |
| 1 | 1315 | 222 | 8/15/2021 | 8/15/2021 |
| 2 | 1316 | 223 | 8/30/2021 | 8/30/2021 |
| 3 | 1317 | 224 | 8/31/2021 | 8/31/2021 |
To make the data easy to analyze, the data analyst wants to have only one table that includes all the information instead of joining all four tables every time they want to analyze. They also want to mask the field phone_number and tokenize the field email_address as sensitive information. To meet this requirement, we merge these four tables into one table and denormalize, tokenize, and mask the data.
The following is the destination table for analysis, sport_event_activity.
| ticket_id | event_id | sport_type | start_date | location | seat_level | seat_location | ticket_price | purchased_by | name | email_address | phone_number | created_at | updated_at | |
| 1 | 1315 | 35 | Baseball | 9/1/2021 | Seattle, USA | Standard | S-1 | 100 | 222 | Teresa Stein | 990d081b6a420d04fbe07dc822918c7ec3506b12cd7318df7eb3af6a8e8e0fd6 | +*-***-***-**** | 8/15/2021 | 8/15/2021 |
| 2 | 1316 | 36 | Baseball | 9/18/2021 | New York, USA | Standard | S-2 | 100 | 223 | Caleb Houston | c196e9e58d1b9978e76953ffe0ee3ce206bf4b88e26a71d810735f0a2eb6186e | ***-***-****x**** | 8/30/2021 | 8/30/2021 |
| 3 | 1317 | 37 | Football | 10/5/2021 | San Francisco, US | Premium | P-1 | 300 | 224 | Raymond Turner | 885ff2b56effa0efa10afec064e1c27d1cce297d9199a9d5da48e39df9816668 | +*-***-***-****x**** | 8/31/2021 | 8/31/2021 |
Solution overview
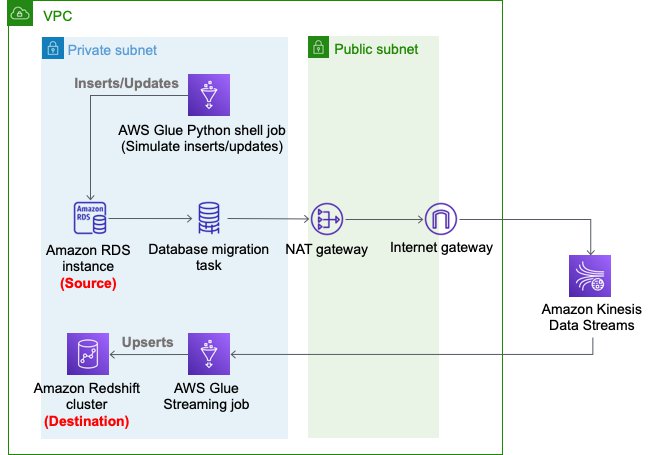
The following diagram depicts the architecture of the solution that we deploy using AWS CloudFormation.

We use an AWS DMS task to capture the changes in the source RDS instance, Kinesis Data Streams as a destination of the AWS DMS task CDC replication, and an AWS Glue streaming job to read changed records from Kinesis Data Streams and perform an upsert into the Amazon Redshift cluster. In the AWS Glue streaming job, we enrich the sports-event records.
Set up resources with AWS CloudFormation
This post includes a CloudFormation template for a quick setup. You can review and customize it to suit your needs.
The CloudFormation template generates the following resources:
- An Amazon RDS database instance (source).
- An AWS DMS replication instance, used to replicate the table
ticket_activityto Kinesis Data Streams. - A Kinesis data stream.
- An Amazon Redshift cluster (destination).
- An AWS Glue streaming job, which reads from Kinesis Data Streams and the RDS database instance, denormalizes, masks, and tokenizes the data, and upserts the records into the Amazon Redshift cluster.
- Three AWS Glue Python shell jobs:
rds-ingest-data-initial-<CloudFormation Stack name>creates four source tables on Amazon RDS and ingests the initial data into the tablessport_event,ticket, andcustomer. Sample data is automatically generated at random by Faker library.rds-ingest-data-incremental-<CloudFormation Stack name>ingests new ticket activity data into the source tableticket_activityon Amazon RDS continuously. This job simulates customer activity.rds-upsert-data-<CloudFormation Stack name>upserts specific records in the source tableticket_activityon Amazon RDS. This job simulates administrator activity.
- AWS Identity and Access Management (IAM) users and policies.
- An Amazon VPC, a public subnet, two private subnets, an internet gateway, a NAT gateway, and route tables.
- We use private subnets for the RDS database instance, AWS DMS replication instance, and Amazon Redshift cluster.
- We use the NAT gateway to have reachability to pypi.org to use MySQL Connector for Python from the AWS Glue Python shell jobs. It also provides reachability to Kinesis Data Streams and an Amazon Simple Storage Service (Amazon S3) API endpoint.
The following diagram illustrates this architecture.
To set up these resources, you must have the following prerequisites:
- IAM roles
dms-vpc-role,dms-cloudwatch-logs-role, anddms-access-for-endpoint. If you haven’t used AWS DMS before, you need to create these special IAM roles from the IAM console or the AWS Command Line Interface (AWS CLI). For instructions, see Creating the IAM roles to use with the AWS CLI and AWS DMS API. - If you already unchecked Use only IAM access control for new databases and Use only IAM access control for new tables in new databases in the AWS Lake Formation console Settings page, you need to select these two check boxes again and save your settings. For more information, see Changing the Default Security Settings for Your Data Lake.
To launch the CloudFormation stack, complete the following steps:
- Sign in to the AWS CloudFormation console.
- Choose Launch Stack:

- Choose Next.
- For S3BucketName, enter the name of your new S3 bucket.
- For VPCCIDR, enter the CIDR IP address range that doesn’t conflict with your existing networks.
- For PublicSubnetCIDR, enter the CIDR IP address range within the CIDR you gave in VPCCIDR.
- For PrivateSubnetACIDR and PrivateSubnetBCIDR, enter the CIDR IP address range within the CIDR you gave for VPCCIDR.
- For SubnetAzA and SubnetAzB, choose the subnets you want to use.
- For DatabaseUserName, enter your database user name.
- For DatabaseUserPassword, enter your database user password.
- Choose Next.
- On the next page, choose Next.
- Review the details on the final page and select I acknowledge that AWS CloudFormation might create IAM resources with custom names.
- Choose Create stack.
Stack creation can take about 20 minutes.
Ingest new records
In this section, we walk you through the steps to ingest new records.
Set up an initial source table
To set up an initial source table in Amazon RDS, complete the following steps:
- On the AWS Glue console, choose Jobs.
- Select the
job rds-ingest-data-initial-<CloudFormation stack name>. - On the Actions menu, choose Run job.
- Wait for the Run status to show as
SUCCEEDED.
This AWS Glue job creates a source table event on the RDS database instance.
Start data ingestion to the source table on Amazon RDS
To start data ingestion to the source table on Amazon RDS, complete the following steps:
- On the AWS Glue console, choose Triggers.
- Select the trigger
periodical-trigger-<CloudFormation stack name>. - On the Actions menu, choose Activate trigger.
- Choose Enable.
This trigger runs the job rds-ingest-data-incremental-<CloudFormation stack name> to ingest one record every minute.
Start data ingestion to Kinesis Data Streams
To start data ingestion from Amazon RDS to Kinesis Data Streams, complete the following steps:
- On the AWS DMS console, choose Database migration tasks.
- Select the task
rds-to-kinesis-<CloudFormation stack name>. - On the Actions menu, choose Restart/Resume.
- Wait for the Status to show as Load complete, replication ongoing.
The AWS DMS replication task ingests data from Amazon RDS to Kinesis Data Streams continuously.
Start data ingestion to Amazon Redshift
Next, to start data ingestion from Kinesis Data Streams to Amazon Redshift, complete the following steps:
- On the AWS Glue console, choose Jobs.
- Select the job
streaming-cdc-kinesis2redshift-<CloudFormation stack name>. - On the Actions menu, choose Run job.
- Choose Run job again.
This AWS Glue streaming job is implemented based on the guidelines in Updating and inserting new data. It performs the following actions:
- Creates a staging table on the Amazon Redshift cluster using the Amazon Redshift Data API
- Reads from Kinesis Data Streams, and creates a DataFrame with filtering only INSERT and UPDATE records
- Reads from three dimension tables on the RDS database instance
- Denormalizes, masks, and tokenizes the data
- Writes into a staging table on the Amazon Redshift cluster
- Merges the staging table into the destination table
- Drops the staging table
After about 2 minutes from starting the job, the data should be ingested into the Amazon Redshift cluster.
Validate the ingested data
To validate the ingested data in the Amazon Redshift cluster, complete the following steps:
- On the Amazon Redshift console, choose EDITOR in the navigation pane.
- Choose Connect to database.
- For Connection, choose Create a new connection.
- For Authentication, choose Temporary credentials.
- For Cluster, choose the Amazon Redshift cluster
cdc-sample-<CloudFormation stack name>. - For Database name, enter
dev. - For Database user, enter the user that was specified in the CloudFormation template (for example,
dbmaster). - Choose Connect.
- Enter the query
SELECT * FROM sport_event_activityand choose Run.
Now you can see the ingested records in the table sport_event_activity on the Amazon Redshift cluster. Let’s note the value of ticket_id from one of the records. For this post, we choose 1317 as an example.

Update existing records
Your Amazon Redshift cluster now has the latest data ingested from the tables on the source RDS database instance. Let’s update the data in the source table ticket_activity on the RDS database instance to see that the updated records are replicated to the Amazon Redshift cluster side.
The CloudFormation template creates another AWS Glue job. This job upserts the data with specific IDs on the source table event. To upsert the records in the source table, complete the following steps:
- On the AWS Glue console, choose Jobs.
- Choose the job
rds-upsert-data-<CloudFormation stack name>. - On the Actions menu, choose Edit job.
- Under Security configuration, script libraries, and job parameters (optional), for Job parameters, update the following parameters:
- For Key, enter
--ticket_id_to_be_updated. - For Value, replace 1 with one of the ticket IDs you observed on the Amazon Redshift console.
- For Key, enter
- Choose Save.
- Choose the job
rds-upsert-data-<CloudFormation stack name>. - On the Actions menu, choose Run job.
- Choose Run job.
This AWS Glue Python shell job simulates a customer activity to buy a ticket. It updates a record in the source table ticket_activity on the RDS database instance using the ticket ID passed in the job argument --ticket_id_to_be_updated. It automatically selects one customer, updates the field purchased_by with the customer ID, and updates the field updated_at with the current timestamp.
To validate the ingested data in the Amazon Redshift cluster, run the same query SELECT * FROM sport_event_activity. You can filter the record with the ticket_id value you noted earlier.

According to the rows returned to the query, the record ticket_id=1317 has been updated. The field updated_at has been updated from 2021-08-16 06:05:01 to 2021-08-16 06:53:52, and the field purchased_by has been updated from 449 to 14. From this result, you can see that this record has been successfully updated on the Amazon Redshift cluster side as well. You can also choose Queries in the left pane to see past query runs.
Clean up
Now to the final step, cleaning up the resources.
- Stop the AWS DMS replication task
rds-to-kinesis-<CloudFormation stack name>. - Stop the AWS Glue streaming job
streaming-cdc-kinesis2redshift-<CloudFormation stack name>. - Delete the CloudFormation stack.
Conclusion
In this post, we demonstrated how you can stream data—not only new records, but also updated records from relational databases—to Amazon Redshift. With this approach, you can easily achieve upsert use cases on Amazon Redshift clusters. In the AWS Glue streaming job, we demonstrated the common technique to denormalize, mask, and tokenize data for real-world use cases.
About the Authors
 Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He enjoys collaborating with different teams to deliver results like this post. In his spare time, he enjoys playing video games with his family.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He enjoys collaborating with different teams to deliver results like this post. In his spare time, he enjoys playing video games with his family.
 Roman Gavrilov is an Engineering Manager at AWS Glue. He has over a decade of experience building scalable Big Data and Event-Driven solutions. His team works on Glue Streaming ETL to allow near real time data preparation and enrichment for machine learning and analytics.
Roman Gavrilov is an Engineering Manager at AWS Glue. He has over a decade of experience building scalable Big Data and Event-Driven solutions. His team works on Glue Streaming ETL to allow near real time data preparation and enrichment for machine learning and analytics.