AWS Big Data Blog
Category: Compute
How CyberArk uses Apache Iceberg and Amazon Bedrock to deliver up to 4x support productivity
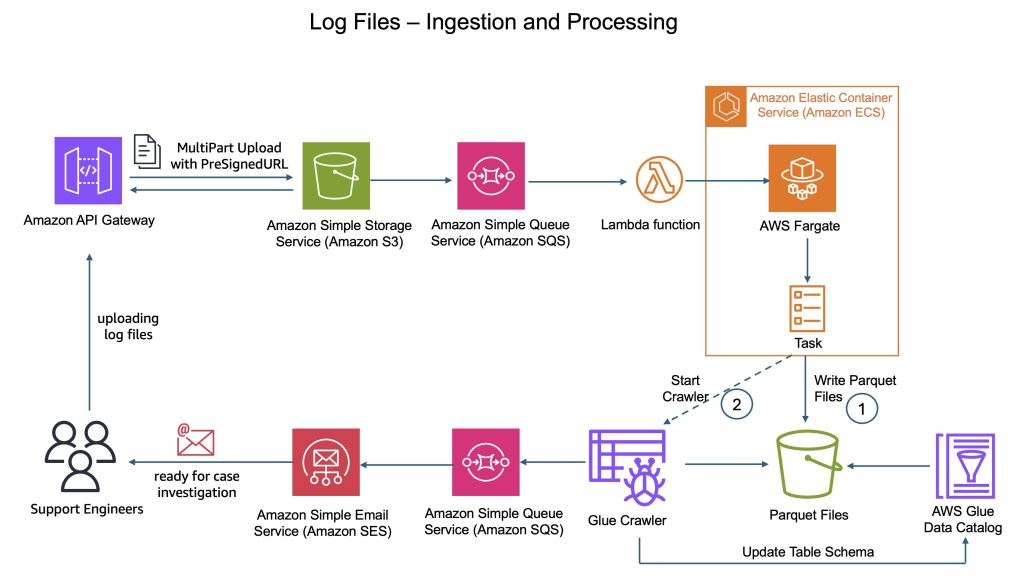
CyberArk is a global leader in identity security. Centered on intelligent privilege controls, it provides comprehensive security for human, machine, and AI identities across business applications, distributed workforces, and hybrid cloud environments. In this post, we show you how CyberArk redesigned their support operations by combining Iceberg’s intelligent metadata management with AI-powered automation from Amazon Bedrock. You’ll learn how to simplify data processing flows, automate log parsing for diverse formats, and build autonomous investigation workflows that scale automatically.
How Tipico democratized data transformations using Amazon Managed Workflows for Apache Airflow and AWS Batch
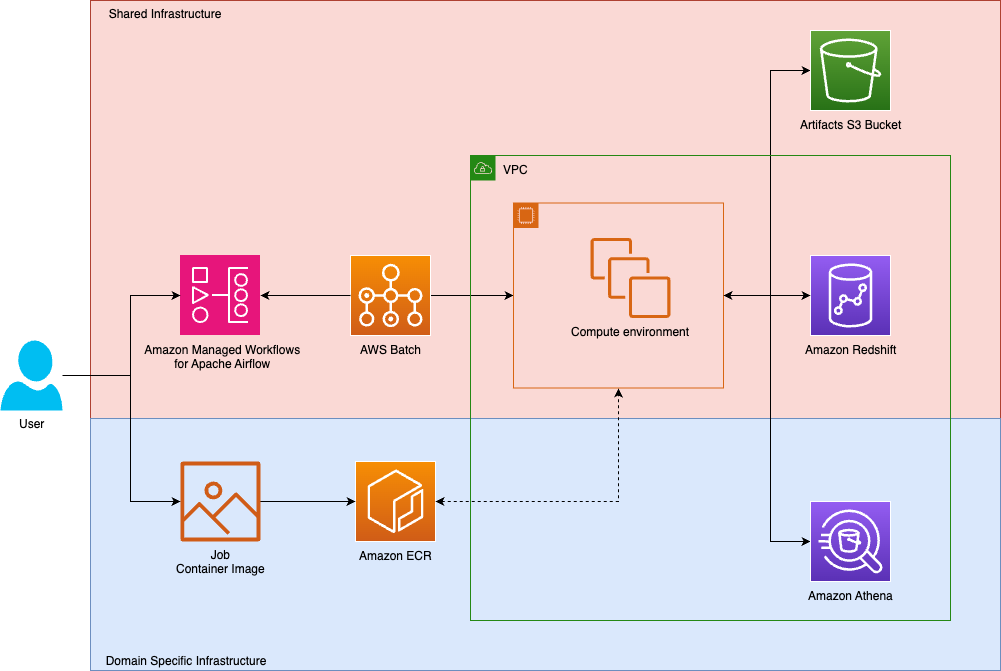
Tipico is the number one name in sports betting in Germany. Every day, we connect millions of fans to the thrill of sport, combining technology, passion, and trust to deliver fast, secure, and exciting betting, both online and in more than a thousand retail shops across Germany. We also bring this experience to Austria, where we proudly operate a strong sports betting business. In this post, we show how Tipico built a unified data transformation platform using Amazon Managed Workflows for Apache Airflow (Amazon MWAA) and AWS Batch.
Create a customizable cross-company log lake, Part II: Build and add Amazon Bedrock
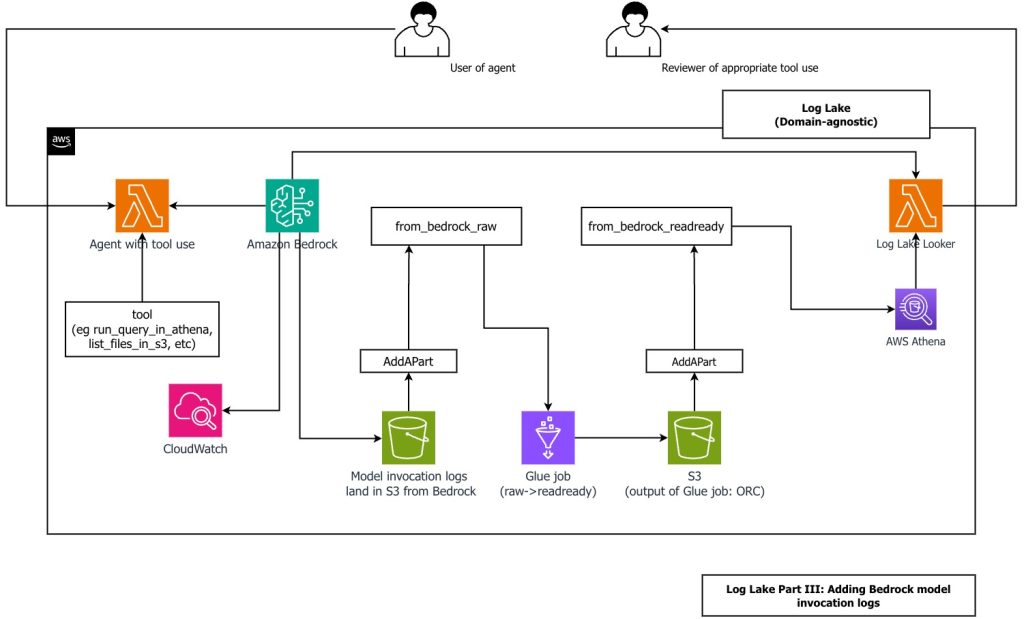
In this post, you learn how to build Log Lake, a customizable cross-company data lake for compliance-related use cases that combines AWS CloudTrail and Amazon CloudWatch logs. You’ll discover how to set up separate tables for writing and reading, implement event-driven partition management using AWS Lambda, and transform raw JSON files into read-optimized Apache ORC format using AWS Glue jobs. Additionally, you’ll see how to extend Log Lake by adding Amazon Bedrock model invocation logs to enable human review of agent actions with elevated permissions, and how to use an AI agent to query your log data without writing SQL.

Modernize Apache Spark workflows using Spark Connect on Amazon EMR on Amazon EC2
In this post, we demonstrate how to implement Apache Spark Connect on Amazon EMR on Amazon Elastic Compute Cloud (Amazon EC2) to build decoupled data processing applications. We show how to set up and configure Spark Connect securely, so you can develop and test Spark applications locally while executing them on remote Amazon EMR clusters.

Building a real-time ICU patient analytics pipeline with AWS Lambda event source mapping
In this post, we demonstrate how to build a serverless architecture that processes real-time ICU patient monitoring data using Lambda event source mapping for immediate alert generation and data aggregation, followed by persistent storage in Amazon S3 with an Iceberg catalog for comprehensive healthcare analytics.

Automate and orchestrate Amazon EMR jobs using AWS Step Functions and Amazon EventBridge
In this post, we discuss how to build a fully automated, scheduled Spark processing pipeline using Amazon EMR on EC2, orchestrated with Step Functions and triggered by EventBridge. We walk through how to deploy this solution using AWS CloudFormation, processes COVID-19 public dataset data in Amazon Simple Storage Service (Amazon S3), and store the aggregated results in Amazon S3.

Achieve low-latency data processing with Amazon EMR on AWS Local Zones
By deploying Amazon EMR on AWS Local Zones, organizations can achieve single-digit millisecond latency data processing for applications while maintaining data residency compliance. This post demonstrates how to use AWS Local Zones to deploy EMR clusters closer to your users, enabling millisecond-level response times.

Enhance Amazon EMR observability with automated incident mitigation using Amazon Bedrock and Amazon Managed Grafana
In this post, we demonstrate how to integrate real-time monitoring with AI-powered remediation suggestions, combining Amazon Managed Grafana for visualization, Amazon Bedrock for intelligent response recommendations, and AWS Systems Manager for automated remediation actions on Amazon Web Services (AWS).

Near real-time streaming analytics on protobuf with Amazon Redshift
In this post, we explore an end-to-end analytics workload for streaming protobuf data, by showcasing how to handle these data streams with Amazon Redshift Streaming Ingestion, deserializing and processing them using AWS Lambda functions, so that the incoming streams are immediately available for querying and analytical processing on Amazon Redshift.

Optimize traffic costs of Amazon MSK consumers on Amazon EKS with rack awareness
In this post, we walk you through a solution for implementing rack awareness in consumer applications that are dynamically deployed across multiple Availability Zones using Amazon EKS.