Artificial Intelligence
Accelerating the deployment of PPE detection solution to comply with safety guidelines

Personal protective equipment (PPE) such as face covers (face mask), hand covers (gloves), and head covers (helmet) are essential for many businesses. For example, helmets are required at construction sites for employee safety, and gloves and face masks are required in the restaurant industry for hygienic operations. In the current COVID-19 pandemic environment, PPE compliance has also become important as face masks are mandated by many businesses. In this post, we demonstrate how you can deploy a solution to automatically check face mask compliance on your business premises and extract actionable insights using the Amazon Rekognition DetectProtectiveEquipment API.
This solution has been developed by AWS Professional Services to help customers that rely heavily on on-site presence of customers or employees to support their safety. Our team built the following architecture to automate PPE detection by consuming the customer’s camera video feeds. This solution enabled a large sports entertainment customer to take timely action to ensure people who are on the premises comply with face mask requirements. The architecture is designed to take raw camera feeds for model inference and pass the model output to an analytic dashboard for further analysis. As of this writing, it’s successfully deployed at a customer site with multiple production cameras.
Let’s walk through the solution in detail and discuss the scalability and security of the application.
Solution overview
The PPE detection solution architecture is an end-to-end pipeline consisting of three components:
- Video ingestion pipeline – Ensures you receive on-demand video feeds from camera and preprocesses the feeds to break them into frames. Finally, it saves the frames in an Amazon Simple Storage Service (Amazon S3) bucket for ML model inference.
- Machine learning inference pipeline – Demonstrates how the machine learning (ML) model processes the frames as soon as they arrive at the S3 bucket. The model outputs are stored back in the S3 bucket for further visualization.
- Model interaction pipeline – Used for visualizing the model outputs. The model outputs feed into Amazon QuickSight, which you can use to analyze the data based on the camera details, day, and time of day.
The following diagram illustrates this architecture (click to expand).

We now discuss each section in detail.
Video ingestion pipeline
The following diagram shows the architecture of the video ingestion pipeline.
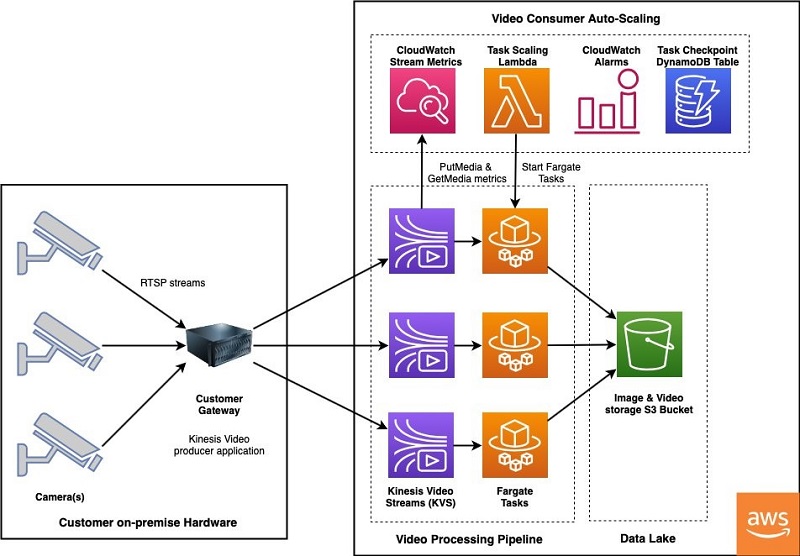
The video ingestion pipeline begins at a gateway located on premises at the customer location. The gateway is a Linux machine with access to RTSP streams on the cameras. Installed on the gateway is the open-source GStreamer framework and AWS-provided Amazon Kinesis Video Streams GStreamer plugin. For additional information on setting up a gateway with the tools needed to stream video to AWS, see Example: Kinesis Video Streams Producer SDK GStreamer Plugin.
The gateway continuously publishes live video to a Kinesis video stream, which acts like a buffer while AWS Fargate tasks read video fragments for further processing. To accommodate customer-specific requirements around the location of cameras that periodically come online and the time of day when streaming processing is needed, we developed a cost-effective and low-operational overhead consumer pipeline with automatic scaling. This avoids manually starting and stopping processing tasks when a camera comes online or goes dark.
Consuming from Kinesis Video Streams is accomplished via an AWS Fargate task running on Amazon Elastic Container Service (Amazon ECS). Fargate is a serverless compute engine that removes the need to provision and manage servers, and you pay for compute resources only when necessary. Processing periodic camera streams is an ideal use case for a Fargate task, which was developed to automatically end when no video data is available on a stream. Additionally, we built the framework to automatically start tasks using a combination of Amazon CloudWatch alarms, AWS Lambda, and checkpointing tables in Amazon DynamoDB. This ensures that the processing always continues from the video segment where the streaming data was paused.
The Fargate task consumes from the Kinesis Video Streams GetMedia API to obtain real-time, low-latency access to individual video fragments and combines them into video clips of 30 seconds or more. The video clips are then converted from MKV to an MP4 container and resampled to 1 frame per second (FPS) to extract an image from each second of video. Finally, the processed video clips and images are copied into an S3 bucket to feed the ML inference pipeline.
ML inference pipeline
The following diagram illustrates the architecture of the ML pipeline.
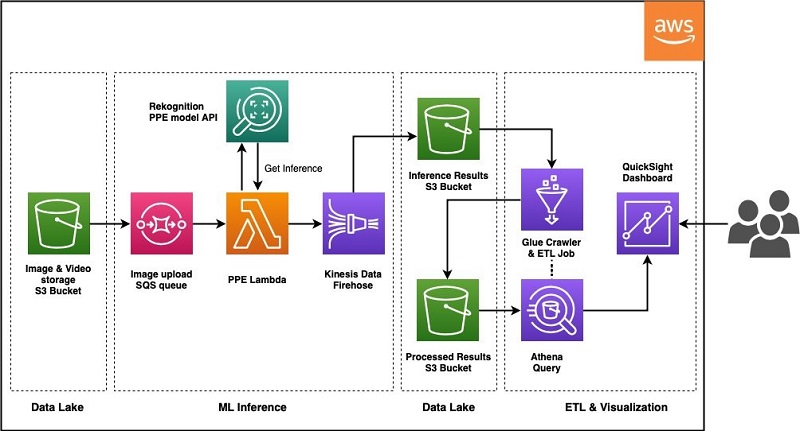
The ML pipeline is architected to be automatically triggered when new data lands in the S3 bucket, and it utilizes a new deep learning-based computer vision model tailored for PPE detection in Amazon Rekognition. As soon as the S3 bucket receives a new video or image object, it generates and delivers an event notification to an Amazon Simple Queue Service (Amazon SQS) queue, where each queue item triggers a Lambda invocation. Each Lambda invocation calls the Amazon Rekognition DetectProtectiveEquipment API to generate model inference and delivers the result back to Amazon S3 through Amazon Kinesis Data Firehose.
The Amazon Rekognition PPE API detects several types of equipment, including hand covers (gloves), face covers (face masks), and head covers (helmets). For our use case, the customer was focused on detecting face masks. The computer vision model in Amazon Rekognition first detects if people are in a given image, and then detects face masks. Based on the location of the face mask on a face, if a person is wearing a face mask not covering their nose or mouth, the service will assign a noncompliant label. When the model can’t detect a face due to image quality, such as when the region of interest (face) is too small, it labels that region as unknown. For each image, the Amazon Rekognition API returns the number of compliant, noncompliant, and unknowns, which are used to calculate meaningful metrics for end users. The following table lists the metrics.
| Metrics | Description |
| Face Cover Non-Compliant | Average number of detected faces not wearing masks appropriately across time |
| Face Cover Non-Compliant % | Average number of detected faces not wearing masks divided by average number of detected faces |
| Detected Face Rate | Average number of detected faces divided by average number of detected people (provides context to the effectiveness of the cameras for this key metric) |
We use the following formulas to calculate these metrics:
- Total number of noncompliant = Total number of detected faces not wearing face cover in the frame
- Total number of compliant = Total number of detected faces wearing face cover in the frame
- Total number of unknowns = Total number of people for which a face cover or face can’t be detected in the frame
- Total number of detected faces = Total number of noncompliant + Total number of compliant
- Total number of detected people = Total number of unknowns + Total number of detected faces
- Mask noncompliant per frame = Total number of noncompliant in the frame

Preprocessing for crowded images and images of very small size
Amazon Rekognition PPE detection supports up to 15 people per image. To support images where more than 15 people are present, we fragment the image into smaller tiles and process them via Amazon Rekognition. Also, PPE detection requires a minimum face size of 40×40 pixels for an image with 1920×1080 pixels. If the image is too small, we interpolate it before performing inference. For more information about size limits, see Guidelines and Quotas in Amazon Rekognition.
Model interaction pipeline
Finally, we can visualize the calculated metrics in QuickSight. QuickSight is a cloud-native and serverless business intelligence tool that enables straightforward creation of interactive visualizations. For more information about setting up a dashboard, see Getting Started with Data Analysis in Amazon QuickSight.
As shown in the following dashboard, end users can configure and display the top priority statistics at the top of the dashboard, such as total count of noncompliant, seating area total count of noncompliant, and front entrance total count of noncompliant. In addition, end users can interact with the line chart to dive deep into the mask-wearing noncompliant patterns. The bottom chart shows such statistics of the eight cameras over time.
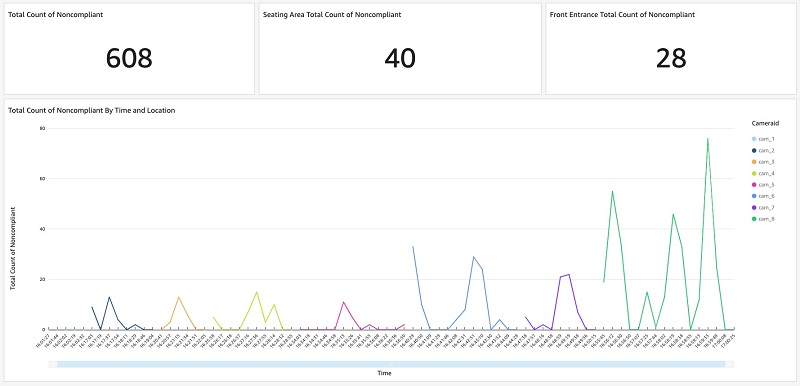
You can create additional visualizations according to your business needs. For more information, see Working with Visual Types in Amazon QuickSight.
Code template
This section contains the code template to help you get started in deploying this solution into your AWS account. This is an AWS Serverless Application Model (AWS SAM) project and requires you to have the AWS Command Line Interface (AWS CLI) and AWS SAM CLI set up in your system.
To build and deploy the AWS CloudFormation stack, complete the following steps:
- Install the AWS CLI and configure your AWS CLI credentials.
- Install the AWS SAM CLI using these instructions.
- Download the Ppe-detection-ml-pipeline.zip
- Unzip the contents of the .zip file and navigate to the root of the project.
- Build the project – This will package the Lambda functions. Note: Python 3.8 and pip are required for this deployment.
- Deploy the CloudFormation stack in your AWS account
Choose an appropriate AWS region to deploy the stack. Use the defaults for all other prompts.
Note: Use sam deploy for subsequent stack updates.
We use Amazon S3 as a data lake to store the images coming out of the video ingestion pipeline after it splits the original camera feeds into 1 FPS images.
After deploying the stack, create the input folder inside the S3 bucket. The input prefix can contain multiple folders, which helps in organizing the results by camera source. To test the pipeline, upload a .jpg containing people and faces to input/[camera_id]/ folder in the S3 bucket. The camera_id can be any arbitrary name. The output and error prefixes are created automatically when the PPE detection job is triggered. The output prefix contains model inference outputs. The error prefix contains records of jobs that failed to run. Make sure you have a similar folder structure in the deployed S3 bucket for the code to work correctly. The S3 data lake bucket folder structure which organizes the collected image and camera metadata along with the model responses:
For example, this sample image is uploaded to the S3 Bucket location: input/CAMERA01/. After Amazon Kinesis Data Firehose delivers the event to Amazon S3, the output/ prefix will contain a file with a JSON record indicating the PPE compliant status of each individual.
The provided AWS SAM project creates the resources, roles, and necessary configuration of the pipeline. Note that the IAM roles deployed are very permissive and should be restricted in production environments.
Conclusion
In this post, we showed how we take a live camera feed as input to build a video ingestion pipeline and prepare the data for ML inference. Next we demonstrated a scalable solution to perform PPE detection using the Amazon Rekognition API. Then we discussed how to visualize the model output results on a QuickSight dashboard for building meaningful dashboards for your safety compliance guidelines. Finally, we provided an AWS SAM project of the ML pipeline if you want to deploy this in your own AWS account.
We also demonstrated how the AWS Professional Services team can help customers with the implementation and deployment of an end-to-end architecture for detecting PPE at scale using Amazon Rekognition’s new PPE detection feature. For additional information, see Automatically detecting personal protective equipment on persons in images using Amazon Rekognition to learn more about the new PPE detection API, insight into model outputs, and different ways to deploy a PPE solution for your own camera and networking requirements.
AWS Professional Services can help customize and implement the PPE detection solution based on your organization’s requirements. To learn more about how we can help, please connect with us with the help of your account manager.
About the Authors
 Pranati Sahu is a Data Scientist at AWS Professional Services and Amazon ML Solutions Lab team. She has an MS in Operations Research from Arizona State University, Tempe and has worked on machine learning problems across industries including social media, consumer hardware, and retail. In her current role, she is working with customers to solve some of the industry’s complex machine learning use cases on AWS.
Pranati Sahu is a Data Scientist at AWS Professional Services and Amazon ML Solutions Lab team. She has an MS in Operations Research from Arizona State University, Tempe and has worked on machine learning problems across industries including social media, consumer hardware, and retail. In her current role, she is working with customers to solve some of the industry’s complex machine learning use cases on AWS.

Surya Dulla is an Associate Cloud Developer at AWS Professional Services. She has an MS in Computer Science from Towson University, Maryland. She has experience in developing full stack applications, microservices in health care and financial industry. In her current role, she focuses on delivering best operational solutions for enterprises using AWS suite of developer tools.

Rohit Rangnekar is a Principal IoT Architect with AWS Professional Services based in the San Francisco Bay Area. He has an MS in Electrical Engineering from Virginia Tech and has architected and implemented data & analytics, AI/ML, and IoT platforms globally. Rohit has a background in software engineering and IoT edge solutions which he leverages to drive business outcomes in healthcare, space and telecom, semiconductors and energy verticals among others.

Taihua (Ray) Li is a data scientist with AWS Professional Services. He holds a M.S. in Predictive Analytics degree from DePaul University and has several years of experience building artificial intelligence powered applications for non-profit and enterprise organizations. At AWS, Ray helps customers to unlock business potentials and to drive actionable outcomes with machine learning. Outside of work, he enjoys fitness classes, biking, and traveling.

Han Man is a Data Scientist with AWS Professional Services. He has a PhD in engineering from Northwestern University and has several years of experience as a management consultant advising clients across many industries. Today he is passionately working with customers to develop and implement machine learning, deep learning, & AI solutions on AWS. He enjoys playing basketball in his spare time and taking his bulldog, Truffle, to the beach.

Jin Fei is a Senior Data Scientist with AWS Professional Services. He has a PhD in computer science in the area of computer vision and image analysis from University of Houston. He has worked as researchers and consultants in different industries including energy, manufacture, health science and finance. Other than providing machine learning and deep learning solutions to customers, his specialties also include IoT, software engineering and architectural design. He enjoys reading, photography, and swimming.

Kareem Williams is a data scientist with Amazon Research. He holds a M.S. in Data Science from Southern Methodist University and has several years of experience solving challenging business problems with ML for SMB and Enterprise organizations. Currently, Kareem is working on leveraging AI to build a more diverse and inclusive workspace at Amazon. In his spare time he enjoys soccer, hikes, and spending time with his family.