Artificial Intelligence
Category: Artificial Intelligence
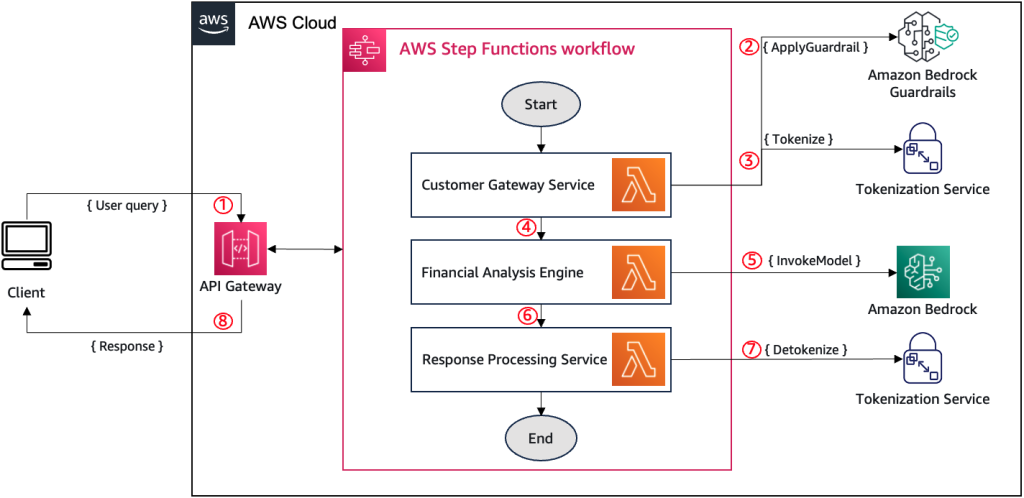
Integrate tokenization with Amazon Bedrock Guardrails for secure data handling
In this post, we show you how to integrate Amazon Bedrock Guardrails with third-party tokenization services to protect sensitive data while maintaining data reversibility. By combining these technologies, organizations can implement stronger privacy controls while preserving the functionality of their generative AI applications and related systems.

Rapid ML experimentation for enterprises with Amazon SageMaker AI and Comet
In this post, we showed how to use SageMaker and Comet together to spin up fully managed ML environments with reproducibility and experiment tracking capabilities.
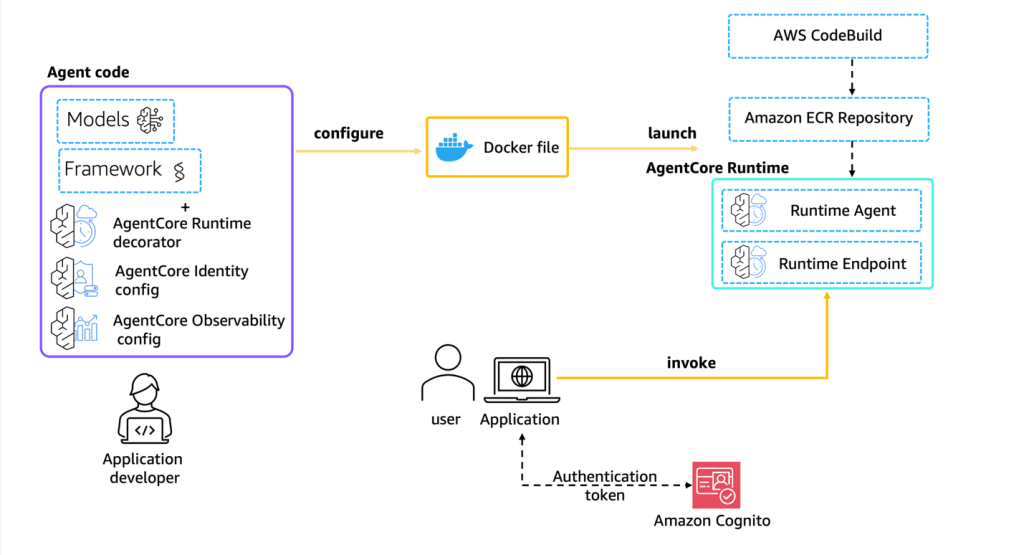
Move your AI agents from proof of concept to production with Amazon Bedrock AgentCore
This post explores how Amazon Bedrock AgentCore helps you transition your agentic applications from experimental proof of concept to production-ready systems. We follow the journey of a customer support agent that evolves from a simple local prototype to a comprehensive, enterprise-grade solution capable of handling multiple concurrent users while maintaining security and performance standards.

Scale visual production using Stability AI Image Services in Amazon Bedrock
This post was written with Alex Gnibus of Stability AI. Stability AI Image Services are now available in Amazon Bedrock, offering ready-to-use media editing capabilities delivered through the Amazon Bedrock API. These image editing tools expand on the capabilities of Stability AI’s Stable Diffusion 3.5 models (SD3.5) and Stable Image Core and Ultra models, which […]

Prompting for precision with Stability AI Image Services in Amazon Bedrock
Amazon Bedrock now offers Stability AI Image Services: 9 tools that improve how businesses create and modify images. The technology extends Stable Diffusion and Stable Image models to give you precise control over image creation and editing. Clear prompts are critical—they provide art direction to the AI system. Strong prompts control specific elements like tone, […]
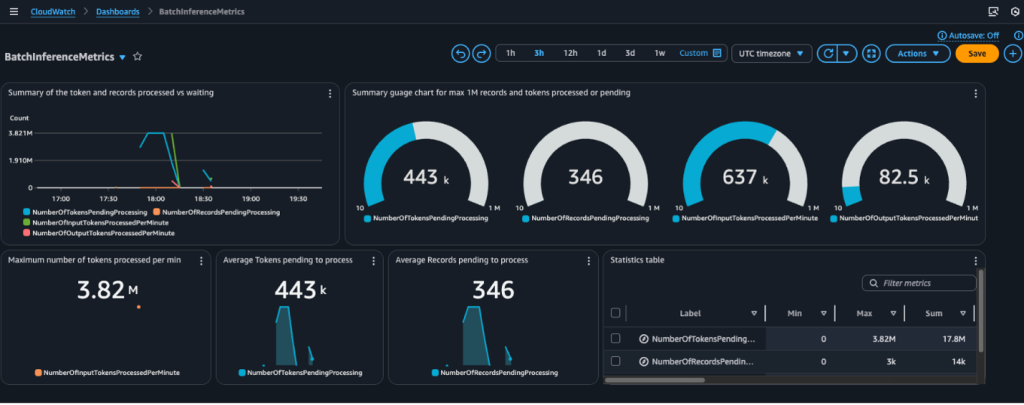
Monitor Amazon Bedrock batch inference using Amazon CloudWatch metrics
In this post, we explore how to monitor and manage Amazon Bedrock batch inference jobs using Amazon CloudWatch metrics, alarms, and dashboards to optimize performance, cost, and operational efficiency.
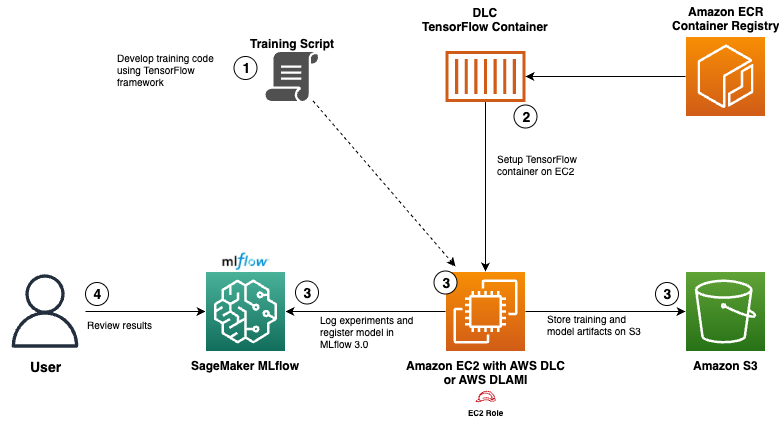
Use AWS Deep Learning Containers with Amazon SageMaker AI managed MLflow
In this post, we show how to integrate AWS DLCs with MLflow to create a solution that balances infrastructure control with robust ML governance. We walk through a functional setup that your team can use to meet your specialized requirements while significantly reducing the time and resources needed for ML lifecycle management.

Build Agentic Workflows with OpenAI GPT OSS on Amazon SageMaker AI and Amazon Bedrock AgentCore
In this post, we show how to deploy gpt-oss-20b model to SageMaker managed endpoints and demonstrate a practical stock analyzer agent assistant example with LangGraph, a powerful graph-based framework that handles state management, coordinated workflows, and persistent memory systems.
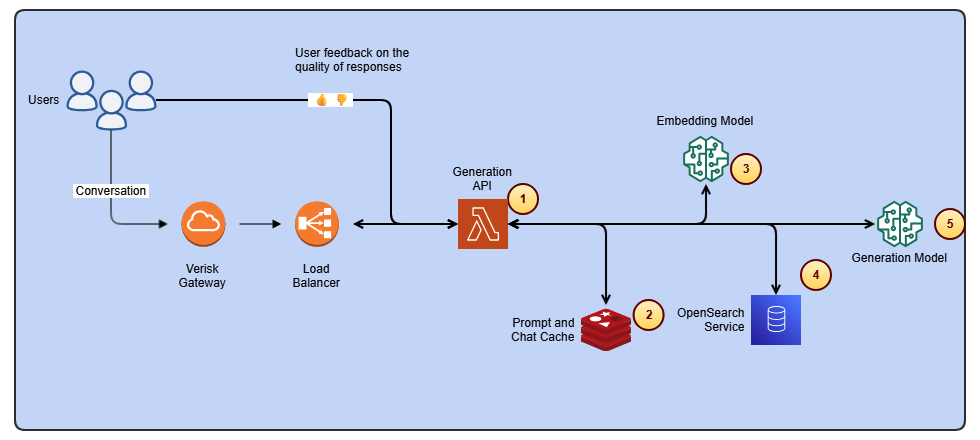
Streamline access to ISO-rating content changes with Verisk rating insights and Amazon Bedrock
In this post, we dive into how Verisk Rating Insights, powered by Amazon Bedrock, large language models (LLM), and Retrieval Augmented Generation (RAG), is transforming the way customers interact with and access ISO ERC changes.
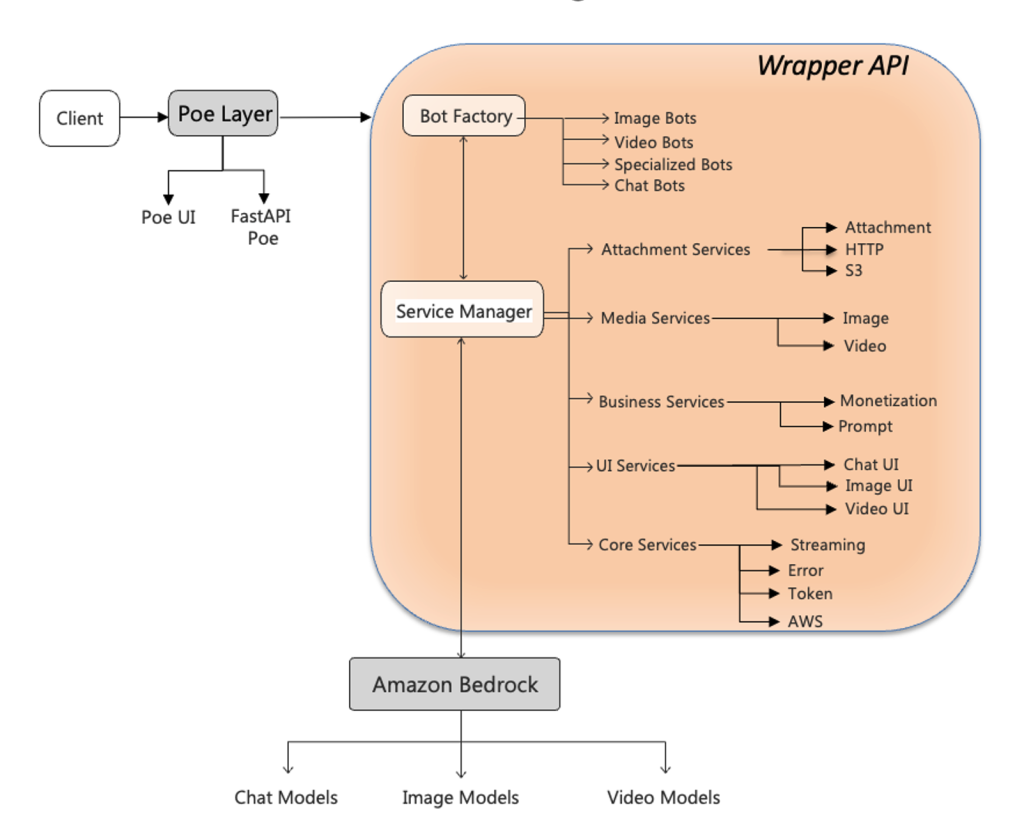
Unified multimodal access layer for Quora’s Poe using Amazon Bedrock
In this post, we explore how the AWS Generative AI Innovation Center and Quora collaborated to build a unified wrapper API framework that dramatically accelerates the deployment of Amazon Bedrock FMs on Quora’s Poe system. We detail the technical architecture that bridges Poe’s event-driven ServerSentEvents protocol with Amazon Bedrock REST-based APIs, demonstrate how a template-based configuration system reduced deployment time from days to 15 minutes, and share implementation patterns for protocol translation, error handling, and multi-modal capabilities.