Artificial Intelligence
Streamline AI operations with the Multi-Provider Generative AI Gateway reference architecture
As organizations increasingly adopt AI capabilities across their applications, the need for centralized management, security, and cost control of AI model access is a required step in scaling AI solutions. The Generative AI Gateway on AWS guidance addresses these challenges by providing guidance for a unified gateway that supports multiple AI providers while offering comprehensive governance and monitoring capabilities.
The Generative AI Gateway is a reference architecture for enterprises looking to implement end-to-end generative AI solutions featuring multiple models, data-enriched responses, and agent capabilities in a self-hosted way. This guidance combines the broad model access of Amazon Bedrock, unified developer experience of Amazon SageMaker AI, and the robust management capabilities of LiteLLM, all while supporting customer access to models from external model providers in a more secure and reliable manner.
LiteLLM is an open source project that addresses common challenges faced by customers deploying generative AI workloads. LiteLLM simplifies multi-provider model access while standardizing production operational requirements including cost tracking, observability, prompt management, and more. In this post we’ll introduce how the Multi-Provider Generative AI Gateway reference architecture provides guidance for deploying LiteLLM into an AWS environment for production generative AI workload management and governance.
The challenge: Managing multi-provider AI infrastructure
Organizations building with generative AI face several complex challenges as they scale their AI initiatives:
- Provider fragmentation: Teams often need access to different AI models from various providers—Amazon Bedrock, Amazon SageMaker AI, OpenAI, Anthropic, and others—each with different APIs, authentication methods, and billing models.
- Decentralized governance model: Without a unified access point, organizations struggle to implement consistent security policies, usage monitoring, and cost controls across different AI services.
- Operational complexity: Managing multiple access paradigms ranging from AWS Identity and Access Management roles to API keys, model-specific rate limits, and failover strategies across providers creates operational overhead and increases the risk of service disruptions.
- Cost management: Understanding and controlling AI spending across multiple providers and teams becomes increasingly difficult, particularly as usage scales.
- Security and compliance: Facilitating consistent security policies and audit trails across different AI providers presents significant challenges for enterprise governance.
Multi-Provider Generative AI Gateway reference architecture
This guidance addresses these common customer challenges by providing a centralized gateway that abstracts the complexity of multiple AI providers behind a single, managed interface.
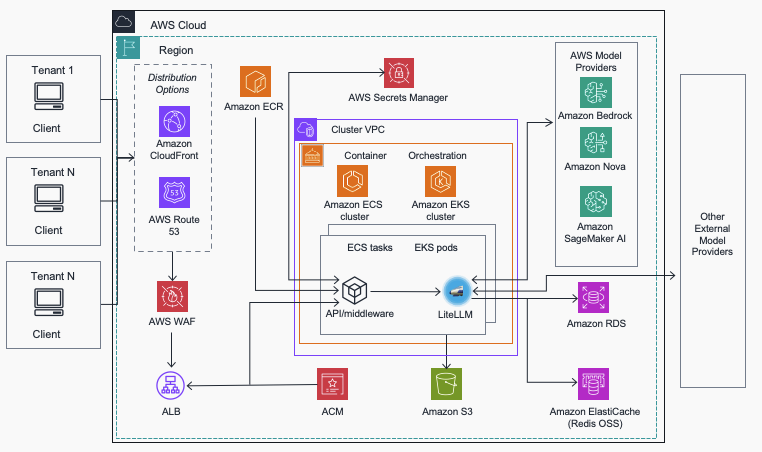
Built on AWS services and using the open source LiteLLM project, organizations can use this solution to integrate with AI providers while maintaining centralized control, security, and observability.
Flexible deployment options on AWS
The Multi-Provider Generative AI Gateway supports multiple deployment patterns to meet diverse organizational needs:
Amazon ECS deployment
For teams preferring containerized applications with managed infrastructure, the ECS deployment provides serverless container orchestration with automatic scaling and integrated load balancing.
Amazon EKS deployment
Organizations with existing Kubernetes expertise can use the EKS deployment option, which provides full control over container orchestration while benefiting from a managed Kubernetes control plane. Customers can deploy a new cluster or leverage existing clusters for deployment.
The reference architecture provided for these deployment options is subject to additional security testing based on your organization’s specific security requirements. Conduct additional security testing and review as necessary before deploying anything into production.
Network architecture options
The Multi-Provider Generative AI Gateway supports multiple network architecture options:
Global Public-Facing Deployment
For AI services with global user bases, combine the gateway with Amazon CloudFront (CloudFront) and Amazon Route 53. This configuration provides:
- Enhanced security with AWS Shield DDoS protection
- Simplified HTTPS management with the Amazon CloudFront default certificates
- Global edge caching for improved latency
- Intelligent traffic routing across regions
Regional direct access
For single-Region deployments prioritizing low latency and cost optimization, direct access to the Application Load Balancer (ALB) removes the CloudFront layer while maintaining security through properly configured security groups and network ACLs.
Private internal access
Organizations requiring complete isolation can deploy the gateway within a private VPC without internet exposure. This configuration makes sure that the AI model access remains within your secure network perimeter, with ALB security groups restricting traffic to authorized private subnet CIDRs only.
Comprehensive AI governance and management
The Multi-Provider Generative AI Gateway is built to enable robust AI governance standards from a straightforward administrative interface. In addition to policy-based configuration and access management, users can configure advanced capabilities like load-balancing and prompt caching.
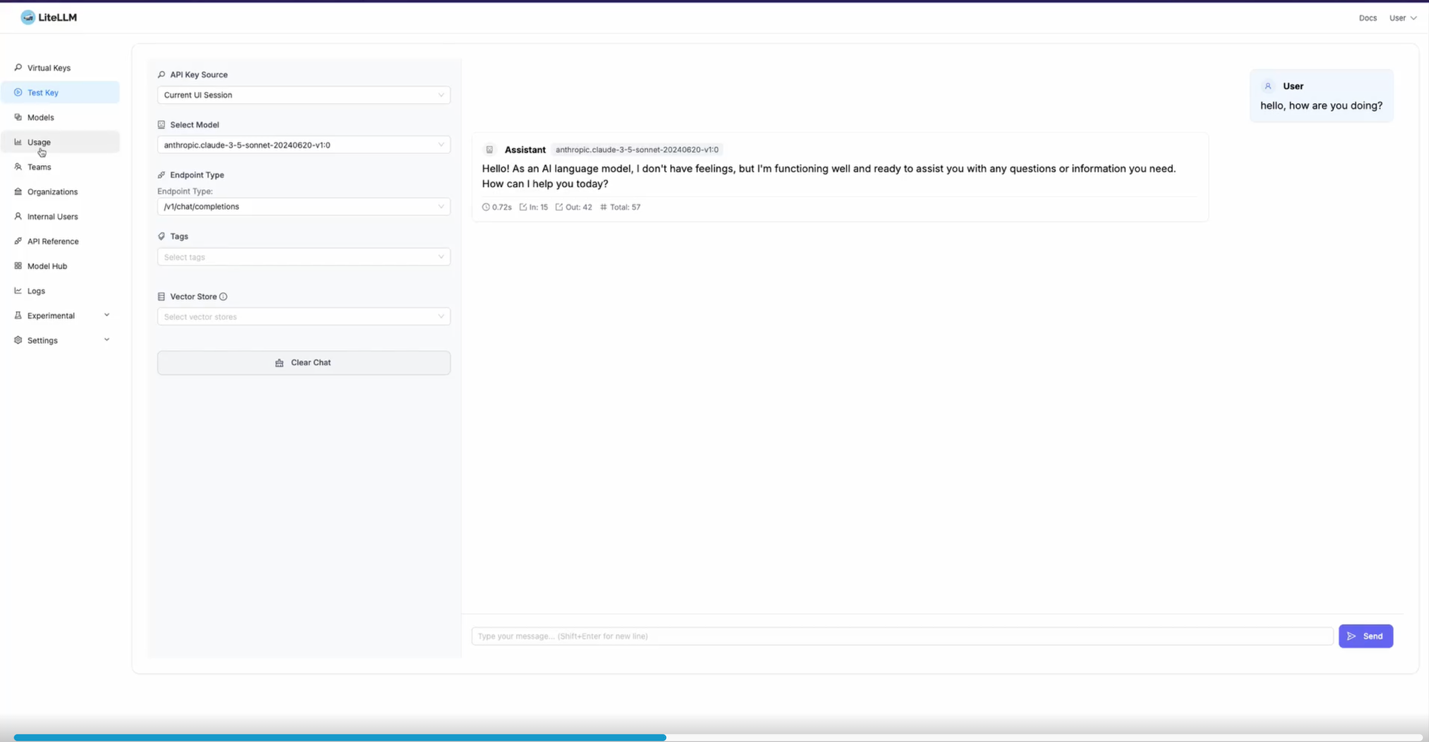
Centralized administration interface
The Generative AI Gateway includes a web-based administrative interface in LiteLLM that supports comprehensive management of LLM usage across your organization.
Key capabilities include:
User and team management: Configure access controls at granular levels, from individual users to entire teams, with role-based permissions that align with your organizational structure.
API key management: Centrally manage and rotate API keys for the connected AI providers while maintaining audit trails of key usage and access patterns.
Budget controls and alerting: Set spending limits across providers, teams, and individual users with automated alerts when thresholds are approached or exceeded.
Comprehensive cost controls: Costs are influenced by AWS infrastructure and LLM providers. While it is the customer’s responsibility to configure this solution to meet their cost requirements, customers may review the existing cost settings for additional guidance.
Supports multiple model providers: Compatible with Boto3, OpenAI, and LangGraph SDK, allowing customers to use the best model for the workload regardless of the provider.
Support for Amazon Bedrock Guardrails: Customers can leverage guardrails created on Amazon Bedrock Guardrails for their generative AI workloads, regardless of the model provider.
Intelligent routing and resilience
Common considerations around model deployment include model and prompt resiliency. These factors are important to consider how failures are handled when responding to a prompt or accessing data stores.
Load balancing and failover: The gateway implements sophisticated routing logic that distributes requests across multiple model deployments and automatically fails over to backup providers when issues are detected.
Retry logic: Built-in retry mechanisms with exponential back-off facilitate reliable service delivery even when individual providers experience transient issues.
Prompt caching: Intelligent caching helps reduce costs by avoiding duplicate requests to expensive AI models while maintaining response accuracy.
Advanced policy management
Model deployment architecture can range from the simple to highly complex. The Multi-Provider Generative AI Gateway features the advanced policy management tools needed to maintain a strong governance posture.
Rate limiting: Configure sophisticated rate limiting policies that can vary by user, API key, model type, or time of day to facilitate fair resource allocation and help prevent abuse.
Model access controls: Restrict access to specific AI models based on user roles, making sure that sensitive or expensive models are only accessible to authorized personnel.
Custom routing rules: Implement business logic that routes requests to specific providers based on criteria such as request type, user location, or cost optimization requirements.
Monitoring and observability
As AI workloads grow to include more components, so to do observability needs. The Multi-Provider Generative AI Gateway architecture integrates with Amazon CloudWatch. This integration enables users to configure myriad monitoring and observability solutions, including open-source tools such as Langfuse.
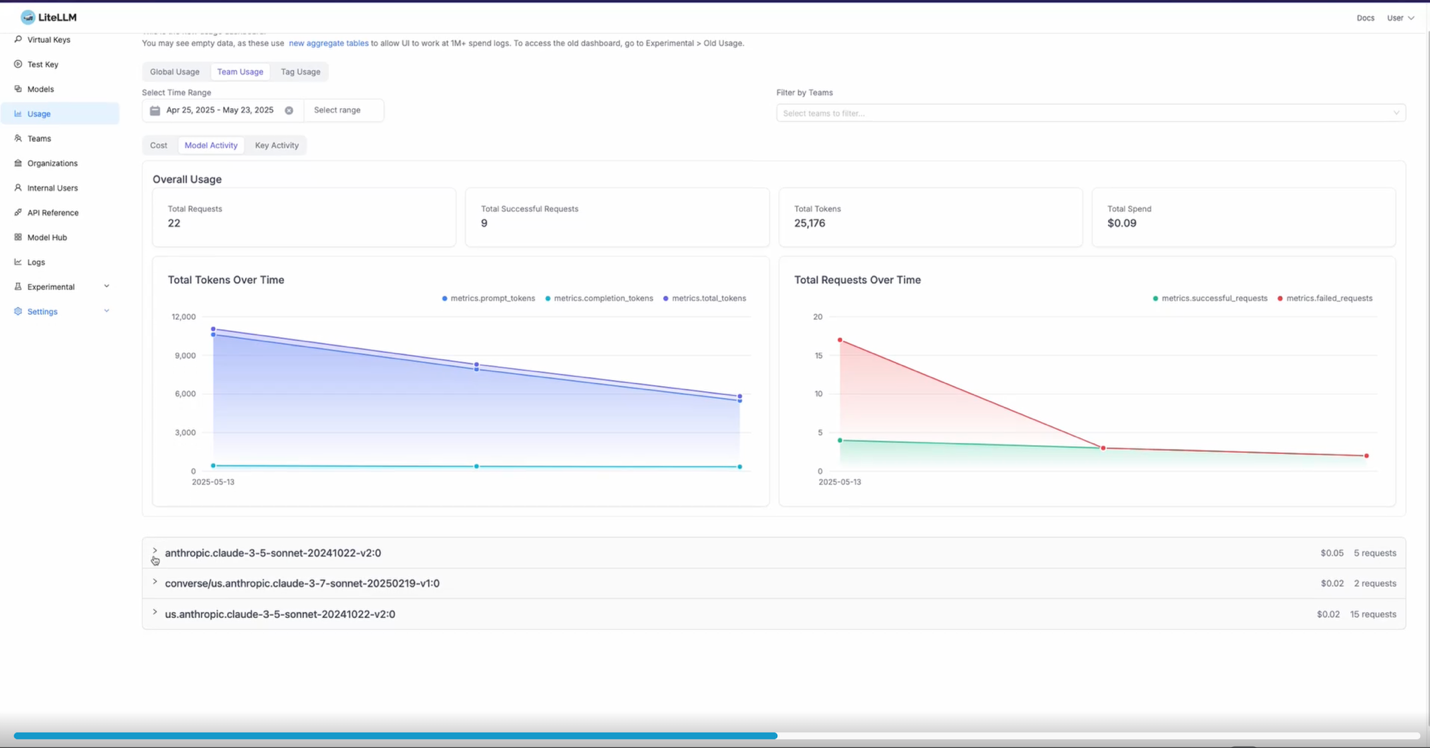
Comprehensive logging and analytics
The gateway interactions are automatically logged to CloudWatch, providing detailed insights into:
- Request patterns and usage trends across providers and teams
- Performance metrics including latency, error rates, and throughput
- Cost allocation and spending patterns by user, team, and model type
- Security events and access patterns for compliance reporting
Built-in troubleshooting
The administrative interface provides real-time log viewing capabilities so administrators can quickly diagnose and resolve usage issues without needing to access CloudWatch directly.
Amazon SageMaker integration for expanded model access
Amazon SageMaker helps enhance the Multi-Provider Generative AI Gateway guidance by providing a comprehensive machine learning system that seamlessly integrates with the gateway’s architecture. By using the Amazon SageMaker managed infrastructure for model training, deployment, and hosting, organizations can develop custom foundation models or fine-tune existing ones that can be accessed through the gateway alongside models from other providers. This integration removes the need for separate infrastructure management while facilitating consistent governance across both custom and third-party models. SageMaker AI model hosting capabilities expands the gateway’s model access to include self-hosted models, as well as those available on Amazon Bedrock, OpenAI, and other providers.
Our open source contributions
This reference architecture builds upon our contributions to the LiteLLM open source project, enhancing its capabilities for enterprise deployment on AWS. Our enhancements include improved error handling, enhanced security features, and optimized performance for cloud-native deployments.
Getting started
The Multi-Provider Generative AI Gateway reference architecture is available today through our GitHub repository, complete with:
- Infrastructure-as-Code: Amazon CloudFormation and AWS Cloud Development Kit (CDK) templates for automated deployment into an Amazon ECS cluster
- Comprehensive documentation: Step-by-step deployment guides and configuration examples
- Interactive workshop: Hands-on learning experience to explore the gateway capabilities
- Detailed deployment guide: Deployment blog on AWS Builder Center
The code repository describes several flexible deployment options to get started.
Public gateway with global CloudFront distribution
Use CloudFront to provide a globally distributed, low-latency access point for your generative AI services. The CloudFront edge locations deliver content quickly to users around the world, while AWS Shield Standard helps protect against DDoS attacks. This is the recommended configuration for public-facing AI services with a global user base.
Custom domain with CloudFront
For a more branded experience, you can configure the gateway to use your own custom domain name, while still benefiting from the performance and security features of CloudFront. This option is ideal if you want to maintain consistency with your company’s online presence.
Direct access via public Application Load Balancer
Customers who prioritize low-latency over global distribution can opt for a direct-to-ALB deployment, without the CloudFront layer. This simplified architecture can offer cost savings, though it requires extra consideration for web application firewall protection.
Private VPC-only access
For a high level of security, you can deploy the gateway entirely within a private VPC, isolated from the public internet. This configuration is well-suited for processing sensitive data or deploying internal-facing generative AI services. Access is restricted to trusted networks like VPN, Direct Connect, VPC peering, or AWS Transit Gateway.
Learn more and deploy today
Ready to simplify your multi-provider AI infrastructure? Access the complete solution package to explore an interactive learning experience with step-by-step guidance describing each step of the deployment and management process.
Conclusion
The Multi-Provider Generative AI Gateway is a solution guidance intended to help customers get started working on generative AI solutions in a well-architected manner, while taking advantage of the AWS environment of services and complimentary open-source packages. Customers can work with models from Amazon Bedrock, Amazon SageMaker JumpStart, or third-party model providers. Operations and management of workloads is conducted via the LiteLLM management interface, and customers can choose to host on ECS or EKS based on their preference.
In addition, we have published a sample that integrates the gateway into an agentic customer service application. The agentic system is orchestrated using LangGraph and deployed on Amazon Bedrock AgentCore. LLM calls are routed through the gateway, providing the flexibility to test agents with different models–whether hosted on AWS or another provider.
This guidance is just one part of a mature generative AI foundation on AWS. For deeper reading on the components of a generative AI system on AWS, see Architect a mature generative AI foundation on AWS, which describes additional components of a generative AI system.
About the authors
 Dan Ferguson is a Sr. Solutions Architect at AWS, based in New York, USA. As a machine learning services expert, Dan works to support customers on their journey to integrating ML workflows efficiently, effectively, and sustainably.
Dan Ferguson is a Sr. Solutions Architect at AWS, based in New York, USA. As a machine learning services expert, Dan works to support customers on their journey to integrating ML workflows efficiently, effectively, and sustainably.
 Bobby Lindsey is a Machine Learning Specialist at Amazon Web Services. He’s been in technology for over a decade, spanning various technologies and multiple roles. He is currently focused on combining his background in software engineering, DevOps, and machine learning to help customers deliver machine learning workflows at scale. In his spare time, he enjoys reading, research, hiking, biking, and trail running.
Bobby Lindsey is a Machine Learning Specialist at Amazon Web Services. He’s been in technology for over a decade, spanning various technologies and multiple roles. He is currently focused on combining his background in software engineering, DevOps, and machine learning to help customers deliver machine learning workflows at scale. In his spare time, he enjoys reading, research, hiking, biking, and trail running.
 Nick McCarthy is a Generative AI Specialist at AWS. He has worked with AWS clients across various industries including healthcare, finance, sports, telecoms and energy to accelerate their business outcomes through the use of AI/ML. Outside of work he loves to spend time traveling, trying new cuisines and reading about science and technology. Nick has a Bachelors degree in Astrophysics and a Masters degree in Machine Learning.
Nick McCarthy is a Generative AI Specialist at AWS. He has worked with AWS clients across various industries including healthcare, finance, sports, telecoms and energy to accelerate their business outcomes through the use of AI/ML. Outside of work he loves to spend time traveling, trying new cuisines and reading about science and technology. Nick has a Bachelors degree in Astrophysics and a Masters degree in Machine Learning.
 Chaitra Mathur is as a GenAI Specialist Solutions Architect at AWS. She works with customers across industries in building scalable generative AI platforms and operationalizing them. Throughout her career, she has shared her expertise at numerous conferences and has authored several blogs in the Machine Learning and Generative AI domains.
Chaitra Mathur is as a GenAI Specialist Solutions Architect at AWS. She works with customers across industries in building scalable generative AI platforms and operationalizing them. Throughout her career, she has shared her expertise at numerous conferences and has authored several blogs in the Machine Learning and Generative AI domains.
 Sreedevi Velagala is a Solution Architect within the World-Wide Specialist Organization Technology Solutions team at Amazon Web Services, based in New Jersey. She has been focused on delivering tailored solutions and guidance aligned with the unique needs of diverse clientele across AI/ML, Compute, Storage, Networking and Analytics domains. She has been instrumental in helping customers learn how AWS can lower the compute costs for machine learning workloads using Graviton, Inferentia and Trainium. She leverages her deep technical knowledge and industry expertise to deliver tailored solutions that align with each client’s unique business needs and requirements.
Sreedevi Velagala is a Solution Architect within the World-Wide Specialist Organization Technology Solutions team at Amazon Web Services, based in New Jersey. She has been focused on delivering tailored solutions and guidance aligned with the unique needs of diverse clientele across AI/ML, Compute, Storage, Networking and Analytics domains. She has been instrumental in helping customers learn how AWS can lower the compute costs for machine learning workloads using Graviton, Inferentia and Trainium. She leverages her deep technical knowledge and industry expertise to deliver tailored solutions that align with each client’s unique business needs and requirements.