Artificial Intelligence
University of California Los Angeles delivers an immersive theater experience with AWS generative AI services
This post was co-written with Andrew Browning, Anthony Doolan, Jerome Ronquillo, Jeff Burke, Chiheb Boussema, and Naisha Agarwal from UCLA.
The University of California, Los Angeles (UCLA) is home to 16 Nobel Laureates and has been ranked the #1 public university in the United States for 8 consecutive years. The Office of Advanced Research Computing (OARC) at UCLA is the technology expansion partner to the research enterprise, providing both intellectual and technical know-how to turn research into reality. The UCLA Center for Research and Engineering in Media and Performance (REMAP) approached OARC to build a set of AI microservices to support an immersive production of the musical, Xanadu.
REMAP’s production of Xanadu, in collaboration with the UCLA Department of Theater’s Ray Bolger Musical Theater program, was designed to be an immersive, participatory performance during which the audience collaboratively created media by using mobile phone gestures to draw images on 13 x 9 foot LED screens, called shrines, provided by 4Wall Entertainment and positionally tracked using Mo-Sys StarTrackers. Their drawings were then run through the AWS microservices for inference with the resulting media re-projected back to the shrines as AI generated 2D images and 3D meshes in the show’s digital scenery (in Unreal Engine on hardware by Boxx). OARC successfully designed and implemented a solution for 7 performances, as well as the many playtests and rehearsals leading up to them. The performances ran between May 15 and May 23, 2025 with about 500 total audience members, up to 65 at a time co-creating media during the performance.
In this post, we will walk through the performance constraints and design choices by OARC and REMAP, including how AWS serverless infrastructure, AWS Managed Services, and generative AI services supported the rapid design and deployment of our solution. We will also describe our use of Amazon SageMaker AI and how it can be used reliably in immersive live experiences. We will outline the models used and describe how they contributed to the audience co-created media. We will also review the mechanisms we used to control cost over the duration of both rehearsals and performances. Finally, we will present lessons learned and improvements we plan to make for phase 2 of this project.
Solution overview
OARC’s solution was designed to enable near real-time (NRT) inferencing during a live performance and included the following high-level requirements:
- The microservices had a strict minimum concurrency requirement of 80 mobile phone users for each performance (accommodating 65 audience members plus 12 performers)
- The mean round-trip time (MRTT) from mobile phone sketches to media presentation had to be under 2 minutes to be ready as the performance was happening and provide optimal audience experience
- The AWS GPU resources had to be fault tolerant and highly available during rehearsals and performances, graceful degradation was not an option
- A human-in-the-loop dashboard was required to provide manual control over the infrastructure resources if human intervention was required
- The architecture had to be flexible enough to handle show-to-show modifications as developers found new ways to solve issues
With the above constraints in mind, we designed the system with a serverless-first architecture approach for most of the workload. We deployed HuggingFace models on Amazon SageMaker AI and used available models in Amazon Bedrock, creating a comprehensive inference pipeline that used the flexibility and strengths of both services. Amazon Bedrock offered simplified and managed access to foundation models such as Anthropic Claude, Amazon Nova, Stable Diffusion and Amazon SageMaker AI provided complete machine learning lifecycle control for open source models from HuggingFace.
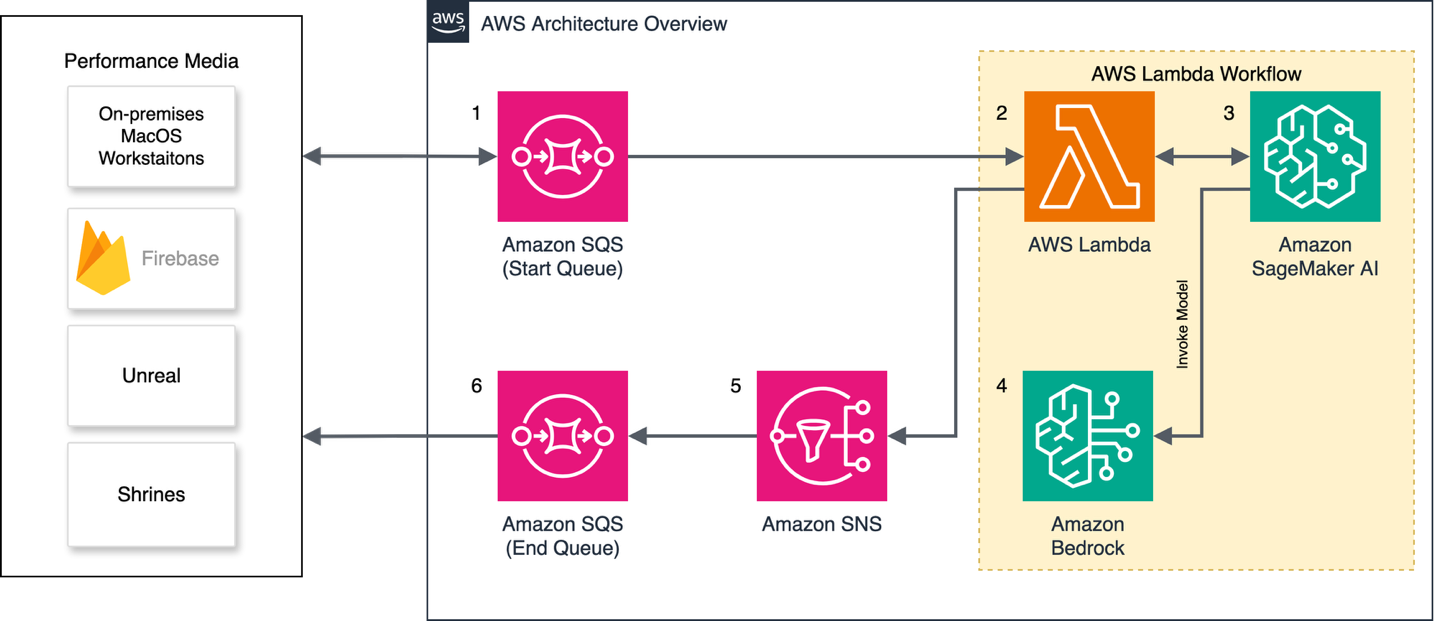
The following architecture diagram shows a high-level view of interactions between the mobile phone sketch creation and OARC’s AWS microservice.
Solution walkthrough
The OARC microservice application design used a serverless-first approach, providing the foundation for an event-driven architecture. User sketches were passed to the microservice using a low-latency Firebase orchestration layer and the work was coordinated through a series of processing steps transforming user sketches into 2D images and 3D meshes. Several on-premises MacOS workstations on the left of the diagram were responsible for initiating workflows, watching for job completions, human in the loop review, and for sending finished assets back to the performance media servers.
Messaging pipeline
Inbound audience sketches and metadata messages were sent to Amazon SQS from the on-premises MacOS workstations, where they were sorted into sub queues by an AWS Lambda helper function. Each queue was responsible for starting a pipeline based on the type of inference processing that the user sketch required (for example, 2D-image, 3D-mesh). The sorting mechanism let the application precisely control its processing rate, so busy pipelines did not block new messages in other pipelines using open resources.
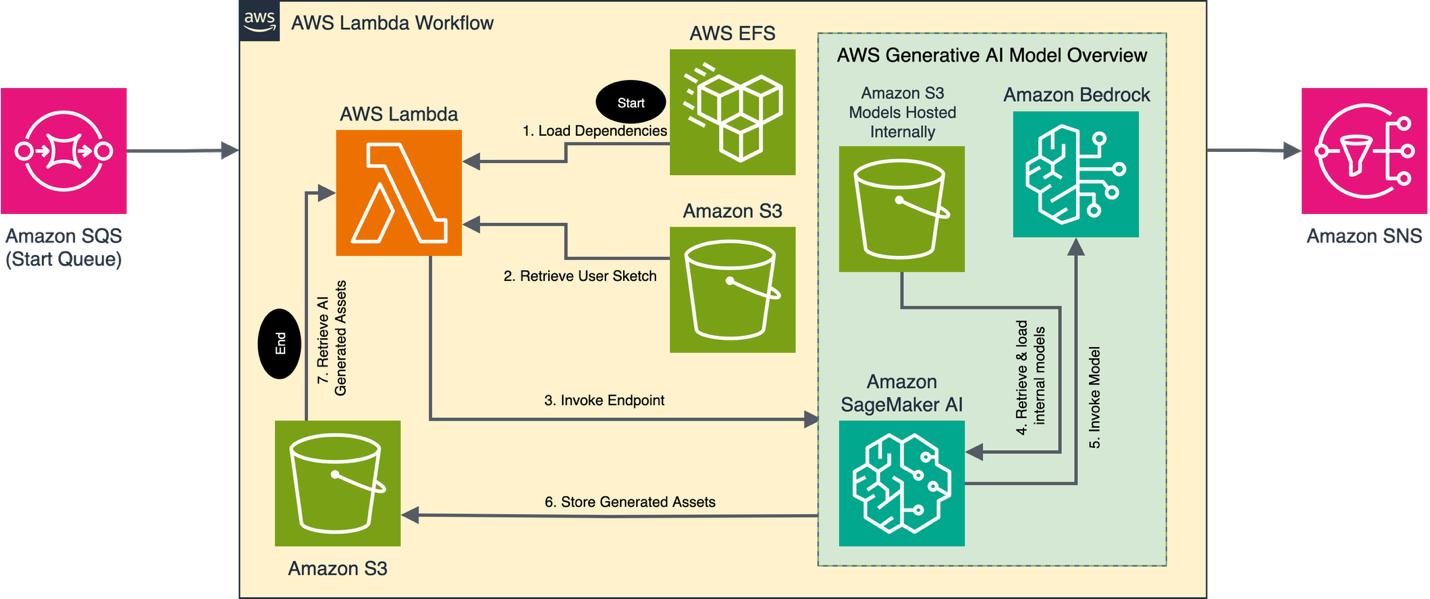
Message processing
A second more complex Lambda function listened for messages from the sorted sub queues and provided the logic to prepare user sketches for inferencing. This function did the validation, error/success messaging, concurrency handling, and orchestration of the pre-processing inference and post-processing steps. This design took a modular approach allowing developers to rapidly integrate new features while keeping merge conflicts to a minimum. Since there was a human-in-the-loop, we did not perform automated post-processing on the images. We could safely trust that issues would be caught before they were sent to the shrines. In the future, we look to validate assets returned by models in SageMaker AI endpoints using guardrails in Amazon Bedrock and other object detection methods along with human-in-the-loop review.
Our processing steps required large Python dependencies including PyTorch. Growing up to 5GB in size, these dependencies were too large to fit in Lambda layers. We used Amazon EFS to host the dependencies in a separate volume mounted to the Lambda function at run time. The size of the dependencies increased the time it took the service to start, but after initial instantiation, future message processing was performant. The increased latency during startup was an ideal use case to address with the Lambda cold starts and latency improvement recommendations. However, we did not implement it because it required some adjustments to our development process late in the project.
Inference requests were handled by 24 SageMaker AI Endpoints, with 8 endpoints responsible for handling the three pipelines. We used the Amazon EC2 G6 instance family to host the models, using 8 g6.12xlarge and 16 g6.4xlarge instances. Each pipeline contained a customized workflow specific to the type of request needed for the production. Each SageMaker AI endpoint leveraged both internally loaded models and large LLMs hosted on Amazon Bedrock to complete each request (the full workflow is detailed in the following AI workflow section). Average processing times, measured from Amazon SageMaker AI job initiation to the return of generated assets to AWS Lambda, ranged from 40-60 seconds on the g6.4xlarge instances, and 20-30 seconds on the g6.12xlarge instances.
After inferencing, the Lambda function sent the message to an Amazon SNS topic responsible for sending success emails, publishing to Amazon SQS, and updating an Amazon DynamoDB table for future analytics. The on-premises MacOS workstations polled the final queue to retrieve new assets as they finished.
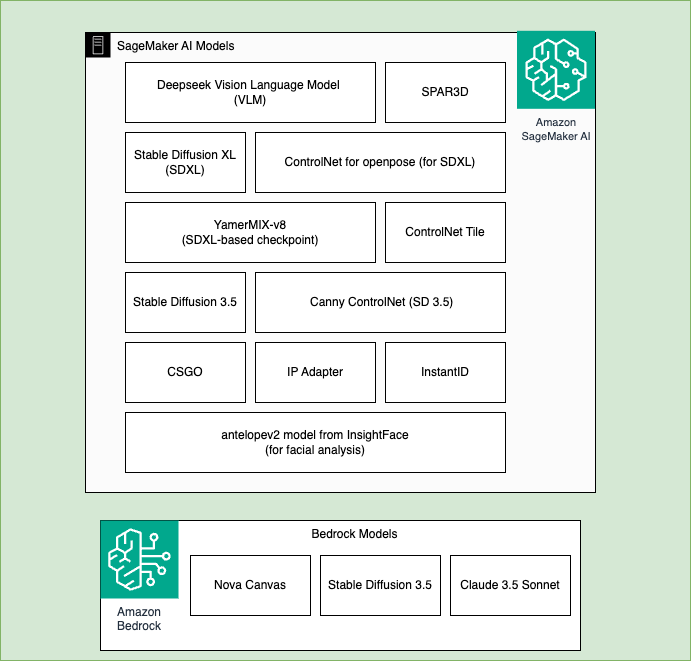
The following image illustrates the models used by both Amazon SageMaker AI and Amazon Bedrock in our solution. Models for Amazon SageMaker AI include: DeepSeek VLM, SDXL, Stable Diffusion 3.5, SPAR3D, ControlNet for openpose, Yamix-8, ControlNet Tile, ControlNet for canny edges, CSGO, IP Adapter, InstantID, antelopev2 model from InsightFace. Models used by Amazon Bedrock include: Nova Canvas, Stable Diffusion 3.5, and Claude 3.5 Sonnet.
AI workflow
The solution leveraged AWS for three distinct inference cycles, called modules. Each module features a tailored AI workflow, utilizing a subset of small and large AI models, to generate 2D images and 3D mesh objects for presentation. Every module begins with an audience prompt, in which participants are asked to draw a sketch for a specific task, such as creating a background, rendering a 2D representation of a 3D object, or placing muses in custom poses and garments. The AI workflow processes these images according to the requirements of each module.
Each module began by generating textual representations of the user’s sketch and any accompanying predesigned reference images. To accomplish this, we used either a DeepSeek VLM loaded onto an Amazon SageMaker AI endpoint or Anthropic’s Claude 3.5 Sonnet model through Amazon Bedrock. The predesigned images included various theatrical poses, designer garments, and helpful assets intended to guide model outputs. Next, these descriptions, user sketches, and supplemental assets were provided as inputs to a local diffusion model paired with a ControlNet or similar framework to generate the desired image. In two of the modules, lower-resolution images were generated to reduce inference time. These lower-quality images were passed into either Nova Canvas in Amazon Bedrock or Stable Diffusion 3.5 to rapidly generate higher-quality images, depending on the module. For example, with Nova Canvas, we used the IMAGE_VARIATION task type to generate a 2048 x 512-pixel image from the low-resolution background sketches created by the DeepSeek VLM. This approach offloaded part of the inference workload, enabling us to run smaller Amazon SageMaker AI instance types without sacrificing quality or speed.
The workflow then proceeded with the final processing routines specific to each output type. For background images, a cast member was overlaid at a varying location near the bottom edge of the image. The custom poses were converted into texture objects, and object sketches were transformed into 3D mesh objects via the image-to-3D model. Finally, Amazon SageMaker AI stored the image assets in an Amazon S3 bucket, where the main AWS Lambda function could retrieve them.
The following image is an example of assets used and produced by one of the modules. User sketch is on the left, actor photo is on top, reference background image is on the bottom, and the AI generated image on the right.

Continuous deployment and management
Deployment of code to the Lambda function was handled by AWS CodeBuild. The job was responsible for listening for pull request merges on GitHub, updating the Python dependencies in EFS, and deploying the updates to the main Lambda function. This code deployment strategy supported consistent and reliable updates across our development, staging, and production environments and obviated the need for manual code deployments and updates, reducing the risk that entails.
SageMaker AI endpoints were managed by a custom web interface that allowed administrators to deploy “known-good” endpoint configurations, allowing for quick deployments of infrastructure, rapid redeploys, and simple shutdowns. The dashboard also contained metrics on jobs running in Amazon SQS and Amazon CloudWatch Logs so that the crew could purge messages from the pipeline.
Lessons learned and improvements
After working through the performances and with the benefit of hindsight, we have some recommendations and considerations that would be useful for future iterations. We recommend using AWS CloudFormation or similar tool to reduce manual deployments and updates of services used in the application. Many developers follow a development, staging, production pipeline to make modifications and enhancements, so automating the configuration of services will reduce errors created compared to a manual deployment.
By using a modular, serverless, event-driven approach we created a reliable and easy to maintain cloud architecture. By using AWS Managed Services developers and administrators can focus on the system design rather than system maintenance. Overall, we found that AWS Managed Services performed exceptionally well and provided a means to develop complex technological architectures to support real-time image inferencing in a high-stakes environment.
The nature of this project created a unique use case. We needed a way to handle a sudden influx of inference requests coming in all at one time. This surge of requests only lasted 15 minutes, so we needed to create a solution that was both reliable and ephemeral. We reviewed both Amazon EC2 and Amazon SageMaker AI as our main options for deploying 20+ instances on demand. To decide on the best system, we evaluated the following: On-demand request reliability, maintenance burden, complexity, deployment, and load balancing. Amazon EC2 is more than capable of handling these requirements, however obtaining the necessary on-demand instances was challenging, and maintaining that many hosts created an excessive maintenance burden. Amazon SageMaker AI met all our criteria, with straightforward configuration, simple and reliable deployment, and an integrated load balancing service. Ultimately, we opted to host most of our models on SageMaker AI with Amazon Bedrock providing managed serverless access to models such as Nova Canvas, Stable Diffusion 3.5, and Claude 3.5 Sonnet. Amazon EKS is another option that may have met our requirements. It is great at quick deployments and seamlessly scalable, however, we felt that Amazon SageMaker AI was the right choice for this project because it was fast to configure.
While SageMaker AI proved reliable for real-time inference during live performances, it also represented the largest share of our project costs—approximately 40% of total cloud spend. During rehearsals and development, we observed that idle or unused SageMaker AI endpoints could be a major source of cost escalation. To mitigate this, we implemented a nightly automated shutdown process using Amazon EventBridge scheduler and AWS Lambda. This simple automation step stopped resources from being left running unintentionally, helping us maintain cost predictability without sacrificing performance. We are also looking at other cost reduction strategies for phase 2.
Conclusion
By making a conscious design choice to use AWS generative AI services and AWS Managed Services for REMAP’s immersive production of the musical Xanadu, we were able to demonstrate that it is possible to support new and dynamic forms of entertainment with AWS.
We showed that serverless event-driven architecture was a fast and low-cost method for building out such services, and we showed how both Amazon Bedrock and Amazon SageMaker AI can work together to utilize the entire array of available generative AI models. We described our message pipeline and the message processing that went on within it. We discussed the generative AI models used and their function and implementation. Finally, we have shown the potential for continued development of immersive musical theatre on this system.
Xanadu Book by Douglas Carter Beane. Music & Lyrics by Jeff Lynne & John Farrar. Directed by Mira Winick & Corey Wright.
About the authors
 Andrew Browning is the Research Data and Web Platforms Manager for the Office of Advanced Research Computing at the University of California Los Angeles (UCLA). He is interested in the use of AI in the fields of Advanced Manufacturing, Medical and Dental Self- Care, and Immersive Performance. He is also interested in creating re-usable PaaS applications to address common problems in those fields.
Andrew Browning is the Research Data and Web Platforms Manager for the Office of Advanced Research Computing at the University of California Los Angeles (UCLA). He is interested in the use of AI in the fields of Advanced Manufacturing, Medical and Dental Self- Care, and Immersive Performance. He is also interested in creating re-usable PaaS applications to address common problems in those fields.
 Anthony Doolan is Application Programmer and AV Specialist at Research Data and Web Platforms | Infrastructure Support Services at OARC, UCLA. Anthony Doolan is a Full Stack Web Developer and AV Specialist for UCLA’s Office of Advanced Research Computing. He develops and maintains full stack web applications, both on premises and cloud-based, and provides audiovisual systems integration and programming expertise.
Anthony Doolan is Application Programmer and AV Specialist at Research Data and Web Platforms | Infrastructure Support Services at OARC, UCLA. Anthony Doolan is a Full Stack Web Developer and AV Specialist for UCLA’s Office of Advanced Research Computing. He develops and maintains full stack web applications, both on premises and cloud-based, and provides audiovisual systems integration and programming expertise.
 Jerome Ronquillo is Web Developer & Cloud Architect at Research Data and Web Platforms at OARC, UCLA. He specializes in designing and implementing scalable, cloud-native solutions that blend innovation with real-world application.
Jerome Ronquillo is Web Developer & Cloud Architect at Research Data and Web Platforms at OARC, UCLA. He specializes in designing and implementing scalable, cloud-native solutions that blend innovation with real-world application.
 Lakshmi Dasari Lakshmi is a Sr. Solutions Architect supporting Public Sector Higher Education customers in Los Angeles. With extensive experience in Enterprise IT architecture, engineering and management, she now helps AWS customers realize the value of cloud with migration and modernization pathways. In her prior role as an AWS Partner Solutions Architect, she accelerated customer’s AWS adoption with AWS SI and ISV partners. She is passionate about inclusion in tech and is actively involved in hiring and mentoring to promote a diverse talent pool at the workplace.
Lakshmi Dasari Lakshmi is a Sr. Solutions Architect supporting Public Sector Higher Education customers in Los Angeles. With extensive experience in Enterprise IT architecture, engineering and management, she now helps AWS customers realize the value of cloud with migration and modernization pathways. In her prior role as an AWS Partner Solutions Architect, she accelerated customer’s AWS adoption with AWS SI and ISV partners. She is passionate about inclusion in tech and is actively involved in hiring and mentoring to promote a diverse talent pool at the workplace.
 Aditya Singh Aditya Singh is an AI/ML Specialist Solutions Architect at AWS who focuses on helping higher education institutions and state/local government organizations accelerate their AI adoption journey using cutting-edge generative AI and machine learning systems. He specializes in Generative AI applications, natural language processing, and MLOps that address unique challenges in the education and public sector.
Aditya Singh Aditya Singh is an AI/ML Specialist Solutions Architect at AWS who focuses on helping higher education institutions and state/local government organizations accelerate their AI adoption journey using cutting-edge generative AI and machine learning systems. He specializes in Generative AI applications, natural language processing, and MLOps that address unique challenges in the education and public sector.
 Jeff Burke is Professor and Chair of the Department of Theater and Associate Dean, Research and Creative Technology in the UCLA School of Theater, Film and Television, where he co-directs the Center for Research in Engineering, Media, and Performance (REMAP). Burke’s research and creative work explores the intersections of emerging technology and creative expression. He is currently the principal investigator of the Innovation, Culture, and Creativity project funded by the National Science Foundation to explore opportunities nationwide for innovation at the intersection of the creative and technology sectors. He developed and produced Xanadu in collaboration with students from across campus.
Jeff Burke is Professor and Chair of the Department of Theater and Associate Dean, Research and Creative Technology in the UCLA School of Theater, Film and Television, where he co-directs the Center for Research in Engineering, Media, and Performance (REMAP). Burke’s research and creative work explores the intersections of emerging technology and creative expression. He is currently the principal investigator of the Innovation, Culture, and Creativity project funded by the National Science Foundation to explore opportunities nationwide for innovation at the intersection of the creative and technology sectors. He developed and produced Xanadu in collaboration with students from across campus.
 Chiheb Boussema is an Applied AI Scientist at REMAP, UCLA where he develops AI solutions for creative applications. His interests currently include scalability and edge deployment of diffusion models, motion control and synthesis for animation, and memory and human-AI interaction modeling and control.
Chiheb Boussema is an Applied AI Scientist at REMAP, UCLA where he develops AI solutions for creative applications. His interests currently include scalability and edge deployment of diffusion models, motion control and synthesis for animation, and memory and human-AI interaction modeling and control.
 Naisha Agarwal is a rising senior at UCLA majoring in computer science. She was the generative AI co-lead for Xanadu where she worked on designing the Generative AI workflows that powered various audience interactions in the show, combining her passion for technology and the arts. She interned at Microsoft Research, working on designing user- authored immersive experiences, augmenting physical spaces with virtual worlds. She has also interned at Kumo where she developed a custom AI chatbot which was later deployed on Snowflake. Additionally, she has published a paper on recommender systems at the KDD conference. She is passionate about using computer science to solve real world problems.
Naisha Agarwal is a rising senior at UCLA majoring in computer science. She was the generative AI co-lead for Xanadu where she worked on designing the Generative AI workflows that powered various audience interactions in the show, combining her passion for technology and the arts. She interned at Microsoft Research, working on designing user- authored immersive experiences, augmenting physical spaces with virtual worlds. She has also interned at Kumo where she developed a custom AI chatbot which was later deployed on Snowflake. Additionally, she has published a paper on recommender systems at the KDD conference. She is passionate about using computer science to solve real world problems.