Perché scegliere Amazon SageMaker?
Amazon SageMaker è un servizio completamente gestito che riunisce un'ampia gamma di strumenti per abilitare il machine learning (ML) ad alte prestazioni e a basso costo per qualsiasi caso d'uso. Con SageMaker è possibile creare, addestrare e implementare modelli ML su larga scala utilizzando strumenti come notebook, debugger, profilatori, pipeline, MLOps e altro ancora, il tutto in un unico ambiente di sviluppo integrato (IDE). SageMaker supporta i requisiti di governance con controllo degli accessi semplificato e trasparenza sui progetti di ML. Inoltre, è possibile creare FM, modelli di grandi dimensioni addestrati su enormi set di dati, con strumenti appositamente progettati per ottimizzare, sperimentare, riaddestrare e implementare gli FM. SageMaker offre l'accesso a centinaia di modelli preaddestrati, inclusi FM disponibili al pubblico, che è possibile implementare con pochi clic.
Perché scegliere Amazon SageMaker?
Amazon SageMaker è un servizio completamente gestito che riunisce un'ampia gamma di strumenti per abilitare il machine learning (ML) ad alte prestazioni e a basso costo per qualsiasi caso d'uso. Con SageMaker è possibile creare, addestrare e implementare modelli ML su larga scala utilizzando strumenti come notebook, debugger, profilatori, pipeline, MLOps e altro ancora, il tutto in un unico ambiente di sviluppo integrato (IDE). SageMaker supporta i requisiti di governance con controllo degli accessi semplificato e trasparenza sui progetti di ML. Inoltre, è possibile creare FM, modelli di grandi dimensioni addestrati su enormi set di dati, con strumenti appositamente progettati per ottimizzare, sperimentare, riaddestrare e implementare gli FM. SageMaker offre l'accesso a centinaia di modelli preaddestrati, inclusi FM disponibili al pubblico, che è possibile implementare con pochi clic.
Vantaggi di SageMaker
Consenti a più persone di innovare con il ML
-
Analisti aziendali
-
Data scientist
-
Ingegneri ML
-
Analisti aziendali
-

Analisti aziendali
Elabora previsioni ML utilizzando un'interfaccia grafica con Amazon SageMaker Canvas. -
Data scientist
-
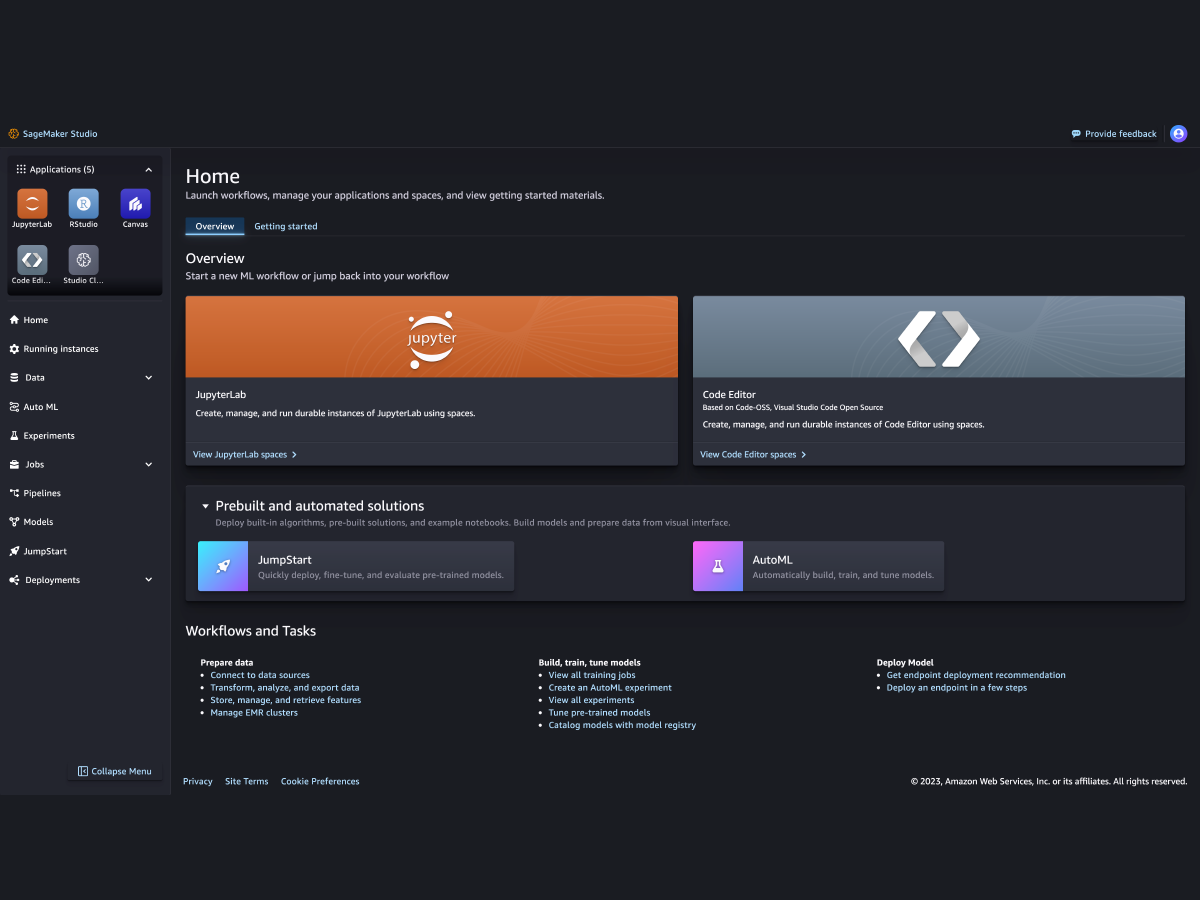
Data scientist
Prepara dati e costruisci, addestra e implementa modelli con SageMaker Studio. -
Ingegneri ML
-

Ingegneri ML
Implementa e gestisci modelli su vasta scala con SageMaker MLOps.
Supporto per i principali framework di ML, kit di strumenti e linguaggi di programmazione
