Amazon Web Services ブログ
COVID-19 データの分析用のパブリックデータレイク
COVID-19 のパンデミックは、世界中に脅威をもたらし、命を奪い続けています。私たちはこの病気と戦うために組織や科学的分野を超えて協力する必要があります。数え切れないほどの医療従事者、医学研究者、科学者、公衆衛生担当者は、すでに最前線で患者の世話、治療法の探求、国民の教育、政策立案の手助けをしています。AWS は、COVID-19 の原因となるウイルスをよりよく理解および追跡し、対応を計画し、最終的に封じ込めて制圧するために必要なデータとツールをこれらの専門家に提供することが一助になることを信じています。
今日、私たちはパブリックの AWS COVID-19 のデータレイクを用意しました。このデータレイクは、新型コロナウイルス (SARS-CoV-2) とこれに関連する病気である COVID-19 の拡大と特性に関する、キュレーション済みの最新のデータセットを一元化したリポジトリです。世界的には、このデータを収集するためにいくつかの取り組みが進行中であり、当社はパートナーと協力して、この重要なデータを自由に利用できる状態にし、最新の状態に保てるように尽力しています。AWS クラウドでホストされており、ジョンズ・ホプキンズ大学とニューヨークタイムズからの COVID-19 のケーストラッキングデータ、Definitive Healthcare からの病院の病床の利用可能性、およびアレン人工知能研究所からの COVID-19 および関連するコロナウイルスに関する 45,000 を超える研究記事をキュレーションされたデータレイクに提供しています。その他の信頼できる情報源からデータが公開されれば、このデータレイクに定期的に追加していきます。
誰もがこの重要な情報に簡単にアクセスして実験できるようになることで、この病気との戦いに打ち勝つための飛躍的な進歩をより早く実現できます。AWS COVID-19 データレイクを使用すると、実験者は、利用可能なすべてのデータソースからデータを抽出してラングリングする時間を無駄にすることなく、所定の場所にあるデータについての分析を迅速に行うことができます。AWS またはサードパーティーのツールを使用して、傾向分析の実行、キーワード検索の実行、質問/回答分析の実行、機械学習モデルの構築と実行、またはカスタム分析の実行により、特定のニーズを満たすことができます。この戦いに関わるステークホルダーは独自の視点を持っているので、ユーザーは、このパブリックデータレイクを使うことも、このデータレイクを独自のデータと組み合わせて使うこともできますし、あるいは AWS Data Exchange 経由で提供されるソースデータセットを直接サブスクライブすることもできます。
私たちは、各地の保健当局が感染を追跡するためのダッシュボードを構築し、病院の病床や人工呼吸器などの重要なリソースを効率的に配給するために協力できると考えています。あるいは、疫学者は、独自のモデルとデータセットを補完して、ホットスポットや傾向についてのより優れた予測を取得できます。
たとえば、科学分野とテクノロジー分野のリーダーが協力して、病気の治療、予防、または管理を行う非営利団体である Chan Zuckerberg Biohub では、科学者が AWS COVID-19 データレイクを使用して新たな疫学的洞察を得ています。「私たちの研究チームは、COVID を疫学的により適切に予測するために、AWS COVID-19 データレイクのデータセットを独自のデータと組み合わせて活用することで、病気の広がり、その地理的側面、および時間発展の傾向を分析しています」と Chan Zuckerberg Biohub のデータサイエンスおよび情報技術担当の Vice President である Jim Karkanias 氏は述べています。
この投稿では、AWS COVID-19 データレイクを分析に使用する方法の例を紹介します。このデータレイクは、パブリックに読み取り可能な Amazon S3 バケット (s3://covid19-lake) のデータで構成されています。この投稿は、AWS Glue データカタログでそのデータの定義を設定して、分析エンジンに公開する方法を示しています。その後、サーバーレス SQL クエリエンジンである Amazon Athena を使用して AWS COVID-19 データレイクをクエリできます。
前提条件
この記事では、次の条件が満たされていることを前提としています。
- AWS アカウントへのアクセス
- AWS CloudFormation スタックを作成するためのアクセス許可
- AWS Glue リソースを作成するためのアクセス許可 (カタログデータベースとテーブル)
CloudFormation テンプレートを使用したデータへのアクセスの設定
AWS COVID-19 データレイクのデータを AWS アカウントのデータカタログで利用できるようにするには、次のテンプレートを使用して CloudFormation スタックを作成します。AWS アカウントにサインインしている場合、次のリンクをクリックすると、あらかじめほとんどの部分が入力されたスタック作成フォームにジャンプします。唯一しなければならないのは、[スタックの作成] を選択することです。CloudFormation スタックの作成手順については、Cloud Formation のドキュメントの はじめにをご覧ください。
このテンプレートは、データカタログに covid-19 データベースを作成し、パブリック AWS COVID-19 データレイクを指すテーブルを作成します。あなたのアカウントでデータをホストする必要はありません。データは AWS がホストします。AWS Data Exchange 経由でデータセット更新される度に、データレイクのデータも AWS 側で更新します。
AWS アカウントのデータカタログを介してデータを探す
CloudFormation スタックが CREATE_COMPLETE のステータスを示したら、Glue データカタログにアクセスして、テンプレートが作成したテーブルを確認します。以下のようなテーブルを確認できるはずです。
| テーブル名 | 説明 | ソース | 提供者 |
enigma_jhu |
確認された COVID-19 の症例 | ジョンズホプキンズ | Enigma |
- 米国におけるコロナウイルス (COVID-19) のデータ – 米国で確認された症例と死亡例を州別および郡別に追跡します。
| テーブル名 | 説明 | ソース | 提供者 |
nytimes_states |
米国の州レベルでの COVID-19 の症例に関するデータ | ニューヨークタイムズ | Rearc |
nytimes_counties |
米国の郡レベルでの COVID-19 の症例に関するデータ |
- コロナウイルス感染症 (COVID-19) のテストデータ – COVID-19 についてテストされた人々、保留中のテスト、および陽性と陰性のテストの数を追跡します。
| テーブル名 | 説明 | ソース | 提供者 |
covid_testing_states_daily |
米国の合計テスト数の日次の傾向 (州別) | COVID 追跡プロジェクト | Rearc |
covid_testing_us_daily |
米国の合計テスト数の日次の傾向 | ||
covid_testing_us_total |
米国の合計テスト数 |
- 米国の病院の病床 – COVID-19 – 米国における病院の病床とその利用に関するデータ。
| テーブル名 | 説明 | ソース | 提供者 |
hospital_beds |
米国における病院の病床とその利用 | Definitive Healthcare | Rearc |
- COVID-19 Open Research Dataset (CORD-19) – COVID-19、SARS-CoV-2、および関連するコロナウイルスに関する 45,000 以上の研究記事 (33,000 以上が全文) のコレクション。AWS は、Amazon Comprehend Medical から抽出された注釈を使用して、これらを前処理して充実しました。
| テーブル名 | 説明 | ソース/提供者 |
alleninstitute_metadata |
CORD-19 データセットからプルされた論文のメタデータ。sha 列は論文 ID を示します。これは、データレイク内の論文のファイル名です。 | アレン人工知能研究所 |
alleninstitute_comprehend_medical |
CORD-19 データセットに対する Amazon Comprehend Medical の実行結果。 |
- 視覚化をサポートするためのルックアップテーブル。
| テーブル名 | 説明 |
country_codes |
国コードのルックアップテーブル |
county_populations |
最近の国勢調査データに基づく郡ごとの人口のルックアップテーブル |
us_state_abbreviations |
米国の州の略号のルックアップテーブル |
さらに、これらのテーブルの列の説明を確認できます。たとえば、次のスクリーンショットは、ジョンズホプキンズからの COVID-19 の症例を含むテーブルのメタデータを示しています。
Amazon Athena を介したデータのクエリ
このセクションでは、Athena を使用してこれらのテーブルをクエリする方法を示します。Athena は、AWS COVID19 データレイクのデータを簡単に分析できるサーバーレスのインタラクティブクエリサービスです。Athena は SQL をサポートしています。SQL は、データアナリストが構造化データの分析に使用する共通言語です。このデータをクエリするには、次の手順を実行します。
- Athena コンソールにログインします。
Athena を初めて使用する場合は、Amazon S3 でクエリ結果の場所を指定する必要があります。
- ドロップダウンメニューから、
covid-19のデータベースを選択します。 - クエリを入力します。
次のクエリは、米国の郡ごとに分類された、病院の病床の利用可能性と隣り合うように結合された過去 7 日間の確定症例の増加を返します。
次のスクリーンショットは、このクエリの結果を示しています。

Athena では、たとえば独自の視覚化を構築するために、REST API を介してこれらのクエリを実行することもできます。さらに、Athena は、データレイクで使用できる多くのエンジンの 1 つにすぎません。たとえば、Amazon Redshift Spectrum を使用してレイクデータを Redshift データウェアハウスの他のデータセットと結合したり、Amazon QuickSight を使用してデータセットを視覚化したりできます。
また、COVID-19 のケーストラッキングデータ、テストデータ、および病院の病床データから、パブリック Amazon QuickSight ダッシュボードを作成しました。このダッシュボードで日々の更新を追跡できます。SQL の行を記述することなく、ドリルダウンして、国、州、および郡ごとの内訳を表示することもできます。以下は、ダッシュボードの最近のスクリーンショットです。

CORD-19 研究記事
CORD-19 データセットは、COVID-19、SARS-CoV-2、および関連するコロナウイルスに関する研究記事のメタデータと全文のコレクションです。質問/回答を探すためにこのデータを Amazon Kendra でインデックスするか、Amazon Comprehend Medical でデータを充実させることができます。これまでに、すでに後者を実行し、それを alleninstitute_comprehend_medical というテーブルに配置しました。
alleninsitute_metadata テーブルは、タイトル、著者、ジャーナル、URL など、各論文の詳細フィールドを提供します。alleninstitute_comprehend_medical テーブルには、病状、投薬、投薬量、強度、頻度などの重要な医学的概念が含まれています。このメタデータを使用すると、概念をすばやくクエリし、著者やジャーナルを分析または集約して、論文を見つけることができます。
ジャーナルでの集計
IL-6 阻害剤の使用は COVID-19 の治療法となる可能性があり、臨床試験が進行中です。これらのテーブルの使用方法を示すために、この投稿では、発表した論文の数に基づいて、IL-6 について最もよく議論しているジャーナルを把握する場合のユースケースを示します。これを行うには、次のクエリを実行します。
次のスクリーンショットは、結果の例を示しています。データプロバイダーは、このデータセットを時間の経過とともに更新するため、結果が異なる場合があります (ここで、2 番目に多い数にはジャーナル情報がないことがわかります)。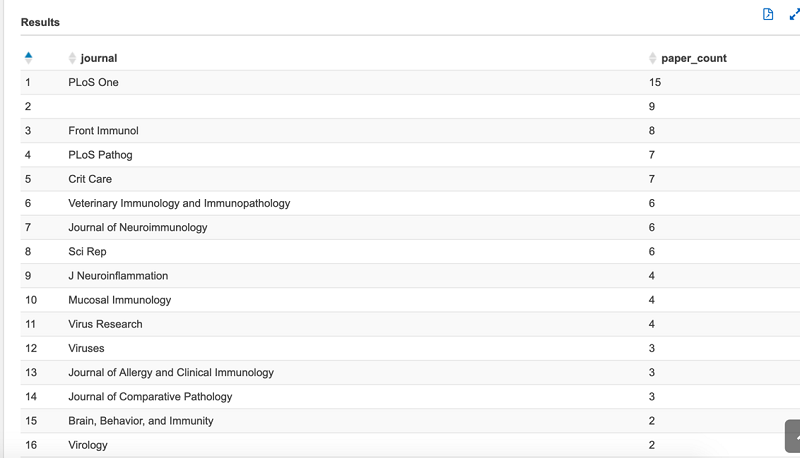
論文にドリルダウン
これらのジャーナルの 1 つに掲載されている論文の URL とタイトルを表示するには、これらの両方のテーブルをもう一度クエリするだけです。たとえば、Crit Care ジャーナルの IL-6 関連の論文にドリルダウンするには、次のクエリを入力します。
次のスクリーンショットは、結果の例を示しています。
 これらの例は、パブリックデータレイクで実行できる無数の分析の一部です。AWS COVID-19 データレイクへのアクセスに、使用する AWS のサービスの標準料金を超える追加費用は発生しません。たとえば、Athena を使用する場合、クエリの実行と S3 クエリ結果の場所でのデータストレージのコストは発生しますが、データレイクへのアクセスのコストは発生しません。さらに、このデータを未加工の形式で使用する場合は、AWS Data Exchange を通じてサブスクライブし、ダウンロードして、最新の状態に保つことができます。パブリック AWS COVID-19 データレイクを試してみることをお勧めします。
これらの例は、パブリックデータレイクで実行できる無数の分析の一部です。AWS COVID-19 データレイクへのアクセスに、使用する AWS のサービスの標準料金を超える追加費用は発生しません。たとえば、Athena を使用する場合、クエリの実行と S3 クエリ結果の場所でのデータストレージのコストは発生しますが、データレイクへのアクセスのコストは発生しません。さらに、このデータを未加工の形式で使用する場合は、AWS Data Exchange を通じてサブスクライブし、ダウンロードして、最新の状態に保つことができます。パブリック AWS COVID-19 データレイクを試してみることをお勧めします。
まとめ
組織や科学分野での垣根を超え、私たちの総力をもってすれば、COVID-19 のパンデミックとの戦いにきっと打ち勝つことができるでしょう。AWS COVID-19 データレイクを使用することで、誰もが病気に関連するキュレーションされたデータを実験および分析できるほか、独自のデータや結果を共有できます。私たちは、データ、テクノロジー、科学を組み合わせたオープンで協力的な取り組みを通じて、COVID-19 を封じ込め、感染規模を縮小し、最終的には完治させるために必要な洞察を引き出し、飛躍的な進歩を実現できると信じています。
AWS COVID-19 データレイクの詳細については、aws.amazon.com/covid-19-data-lake/ をご参照ください。また、AWS が危機に対処する方法についての日々の更新については、Amazon の COVID-19 ブログを参照してください。
著者について
AWS データレイクチームのメンバーは、Roy Ben-Alta、Jason Berkowitz、Chris Casey、Patrick Combes、Lucy Friedmann、Fred Lee、Megan Maxwell、Rourke McNamara、Herain Oberoi、Stephen Orban、Brian Ross、Nikki Rouda、Noah Schwartz、Noritaka Sekiyama、Mehul A. Shah、Ben Snively、および Ying Wangです。