Amazon Web Services ブログ
Amazon SageMaker エンドポイント用のサーバーレスフロントエンドを構築する
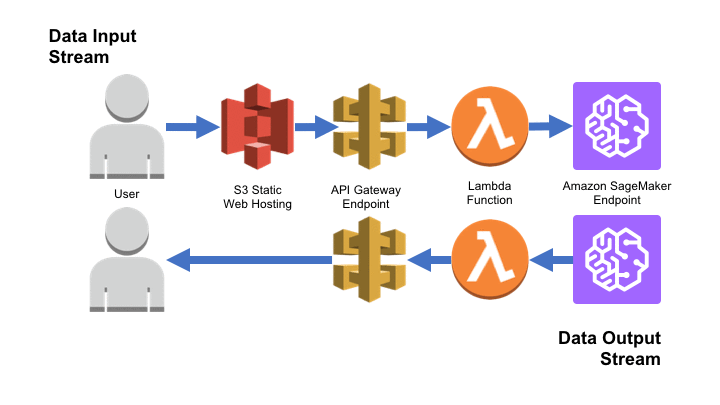
Amazon SageMaker は、AWS の本番環境に機械学習モデルを構築、トレーニング、およびデプロイするための強力なプラットフォームです。この強力なプラットフォームを Amazon Simple Storage Service (S3)、Amazon API Gateway、および AWS Lambda のサーバレス機能と組み合わせることで、Amazon SageMaker エンドポイントを、様々なソースから新しい入力データを受け入れて、その推論の結果をエンドユーザに提示する Web アプリケーションへと変換できるようになりました。
このブログ記事では、有名な Iris データセットモデルを使って、簡単な SageMaker モデルを生成し、それを Amazon SageMaker エンドポイントとしてデプロイします。次に、Chalice パッケージを使用して、API Gateway エンドポイントを作成し、SageMaker エンドポイントを呼び出す Lambda 関数をトリガーし、独自の予測を行います。最後に、アプリケーションのユーザーインターフェイスとして機能させるために、Amazon S3 で静的 HTML フォームを生成します。最終的に製品は、新しいユーザーデータを受け入れ、そのデータに基づいてオンデマンド予測を生成し、ユーザーのブラウザに戻ることができるシンプルな Web アプリケーションとなります。
これは AWS Lambda アーキテクチャバージョンで、SageMaker のドキュメントが提案するアーキテクチャと類似していますが、全てのユースケースに対して最適なアーキテクチャではない可能性があります。レイテンシーが懸念される場合は、データ変換を SageMaker エンドポイントでホストした Docker コンテナに直接組み込むことが合理的です。けれども、API Gateway と Lambda の導入は、複数の潜在的なフロントエンドおよび / またはデータソースが 1 つのエンドポイントとやり取りしているような複雑なアプリケーションを使用している場合に最適なのです。このブログ記事を参考に、デモ、コンセプト検証 (PoC)、プロトタイプを始めるとよいでしょう。ただし、本番アーキテクチャはこれらの例と大きく異なる場合があることを留意ください。
Amazon SageMaker にモデルをデプロイする
機械学習アプリケーションを構築するための最初のステップは、モデルのデプロイです。フロントエンドに効率的にアクセスするため、SageMaker の全てのノートブックインスタンスで利用可能なサンプルノートブック scikit_bring_your_own.ipynb に基づいて、パブリック Docker イメージから Amazon SageMaker に事前に構築、トレーニングしてあるモデルをデプロイします。どのようにこの画像を作るか興味があれば、このノートブックをぜひ読んでみてください。サーバレスフロントエンドにだけ興味があるのなら、以下の手順に従って、SageMaker エンドポイントにあらかじめ構築してあるモデルを設定します。
モデルの作成
AWS マネジメントコンソール上で、Services を選択し、そして Machine Learning にある Amazon SageMaker を選択します。全てが同じリージョンにあることを確認するには、右上隅にある米国東部 (バージニア北部) をリージョンとして選択してください。次に、Resources にある Models を選択します。次に Create model ボタンを選択します。

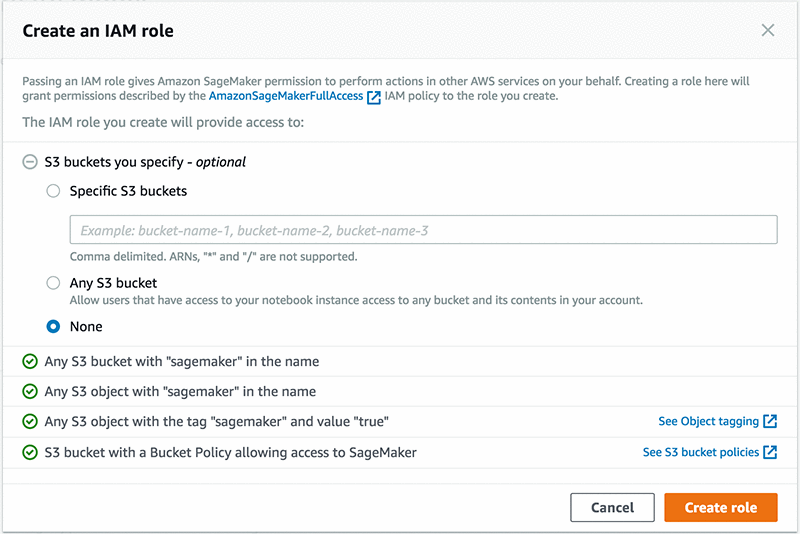
この例では、Model nameを decision-trees にセットしています。次に、IAM role にある Create a new role を選択します。
このロールは Amazon S3 への特別なアクセスを必要としません。ですので None (指定した Amazon S3 バケット内にあります) が選択できます。次に Create role を選択します。モデルを構築したりトレーニングしている場合は、これらの権限が必要ですが、ここではあらかじめ構築したモデルを使用しているため必要ではありません。
そして、Primary container のための次の値を入力します。
推論コード画像の場所: 305705277353.dkr.ecr.us-east-1.amazonaws.com/decision-trees-sample:latest
モデルアーティファクトの場所: s3://aws-machine-learning-blog/artifacts/decision-trees/model.tar.gz
これらは、この例で使用するために事前に構築してあるモデルおよび Docker コンテナのある場所にあります。Create model を選択します。これで、Amazon SageMaker は推論を行う方法、および特定のモデルを見つける場所を知ることができます。次回は、ご自身のモデルを使用してください。
エンドポイント構成を作成する
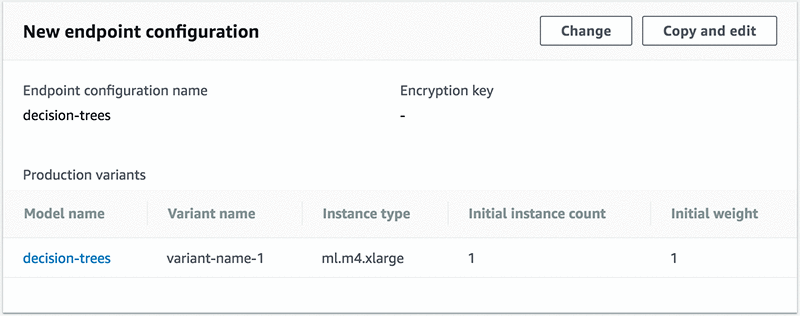
Amazon SageMaker コンソールの左側のナビゲーションペインの Inference にある Endpoint configuration を選択し、次に Create endpoint configuration を選択します。Endpoint configuration name を “decision-trees” と名付け、次に Add model を選択します。これは New endpoint configuration ブロックの一番下にあります。
新しい Add model ダイアログボックスで、前のステップで作成した decision-trees モデルを選択し、次に Save を選択します。
新しいエンドポイント構成は、次のようになります。

Create endpoint configuration を選択します。エンドポイント構成が、前のセクションより、使用するモデルとインスタンスの種類、およびエンドポイントを初期化するインスタンスの数を Amazon SageMaker に知らせます。次のセクションでは、インスタンスをスピンアップする実際のエンドポイントを作成します。
エンドポイントの作成
SageMaker コンソールの左側のナビゲーションペインで、Inference にある Endpoints を選択します。Create endpoint を選択します。Endpoint name に “decision-trees” を入力します。Attach endpoint configuration にある Use an existing endpoint configuration はデフォルト値にしておきます。
Endpoint configuration にある前のステップで作成した decision-trees エンドポイントを選択して、次に Select endpoint configuration を選択します。すると、以下のような結果となるはずです。
今度は Create endpoint を選択します。
Iris データセットに基づいた、あらかじめ構築してある Scikit モデルがデプロイできました。これで、エンドポイントのためのサーバーレスフロントエンドの構築に進むことができます。
警告: SageMaker エンドポイントを実行したままにすると費用がかかることをお忘れなく。学習経験としてこのブログを読んでいる場合は、終了時に必ずエンドポイントを削除してください。そうすれば、追加料金は発生しません。
Chalice を使用して、サーバーレス API アクションを作成する
これで SageMaker エンドポイントが利用できるようになったので、エンドユーザーに配信できる結果を生成するため、エンドポイントにアクセスできる API アクションを作成する必要があります。このブログ記事では、Chalice フレームワークを使用して、API Gateway に Flask のような単純なアプリケーションをデプロイし、SageMaker エンドポイントとやりとりする Lambda 関数をトリガーします。
Chalice は AWS のサーバレスマイクロフレームワークです。Amazon API Gateway と AWS Lambda を使用するアプリケーションをすばやく作成しデプロイします。現在のエンドポイントは CSV 形式での入力を見込んでいるので、HTML 形式のデータをエンドポイントが予期している CSV ファイルに変換するためにいくつかの前処理が必要なのです。Chalice だと、独自の Lambda 機能を構築するのに比べ、迅速かつ効率的にこれを行うことができます。
Chalice のメリットとデメリットについて知りたいことがあれば、Chalice GitHub リポジトリを参考にしてください。
開発環境
一貫性のある環境を実現するためにも、Amazon EC2 インスタンスを開発環境で使ってみましょう。AWS マネジメントコンソールで Services を選択し、次に Compute にある EC2 を選択します。 次に Launch Instance を選択します。 Amazon Linux AMI には必要な開発ツールのほとんどが付属しているので、開発者にとってやりやすい環境であるはずです。次に Select を選択します。

リソースを集中的に使うことはありませんので、t2.micro を選択し、次に Review and Launch を選択します。最後に Launch ボタンをもう一度押します。
すると Select an existing key pair or create a new key pair と促されます。インスタンスへの接続が最も便利な方法を、選択してください。EC2 インスタンスへの接続に不慣れであれば、Connect to Your Linux Instance にあるドキュメントの指示を参照してください。
インスタンスに接続する前に、インスタンスにいくつかの権限を与える必要があります。そうすれば、Chalice アプリケーションをデプロイするために認証情報を使用する必要はなくなります。AWS マネジメントコンソールで Services のページに行き、次に Security, Identity & Compliance にある IAM を選択します。左に表示されている Roles を選択し、次に Create role を選択します。
Select type of trusted entity を実行するため、AWS Service を、次に EC2 を選択します。Choose the service that will use this role にある EC2 を選択します (これで EC2 インスタンスがお客様の代わりに AWS サービスを呼び出すことを許可します)。Next: Permissions を選択します。
この画面では次の権限を選択します。AmazonAPIGatewayAdministrator、AWSLambdaFullAccess、AmazonS3FullAccess および IAMFullAccess。これは Next: Review を選択する前に行ってください。
Role name を実行するために、chalice-dev と打ち込み、「EC2 インスタンスが Chalice アプリケーションをデプロイできるようにする」といったような説明を入力してください。Create role を選択します。
今度は、EC2 インスタンスの実行に、新しいロールを取り付ける必要があります。 EC2 コンソールに戻るため Services を選択し、次に Compute の EC2 を選択します。Running instances を選択します。 以前に起動したインスタンスを選択し、Action を選び、Instance Settings、次に Attach/Replace IAM role を選択します。
IAM role の “chalice-dev” を選択してから Apply を選択します。
これで、EC2 インスタンスに接続できました。
Chalice をセットアップする
EC2 インスタンスに接続したら、Chalice と AWS SDK for Python (Boto3) をインストールする必要があります。以下のコマンドを実行します。
アプリケーションがモデルと同じリージョンにデプロイしていることを確認するために、次のコマンドで環境変数を設定します。
Chalice をインストールしたら、新しい Chalice プロジェクトを作成します。サンプルアプリケーションをダウンロードし、プロジェクトディレクトリに変更しましょう。次のコマンドで、これを行うことができます:
このパッケージの app.py ファイルは、以前にデプロイした事前に構築しているモデルとやりとりができるように特別に設計されています。また、Chalice にフロントエンドに必要な依存関係を知らせるための requirements.txt ファイルと、ポリシーのアクセス許可を管理するのに役立つ “.chalice” フォルダ内にある追加の隠し設定ファイルもダウンロードしました。
簡単にソースをチェックして、このアプリケーションがどんなものか見てみましょう。以下のコマンドを実行します。
次回、これらのファイルをご自身のモデルに変更し、使用してくださって構いません。
必要な Chalice プロジェクトファイルがすでにあるので、アプリケーションをデプロイできます。これを行うには、端末から次のコマンドを実行します。
これが完了すると、Chalice エンドポイントの URI を返します。Rest API URL を後のために保存します。これはフロントエンド用の HTML ファイルに入れておく必要があるからです。
これで、SageMaker エンドポイントと通信できる API Gateway エンドポイントに接続した Lambda 関数をデプロイしたことになります。次に必要なのは、API Gateway にデータを送るための HTML フロントエンドだけです。ユーザーがフロントエンドアプリケーションを使用してリクエストを送信すると、それは API Gateway に行きます。これで Lambda 関数が起動します。この関数は Chalice アプリケーションに含まれる app.py ファイルに基づいて実行され、作成した SageMaker エンドポイントにデータを送信します。 必要な前処理は、custom app.py ファイルで実行できます。
HTML ユーザーインターフェイスを生成する
SageMaker でホストしたモデルと、エンドポイントとやりとりするための API Gateway インターフェイスができました。しかし、ユーザーが新しいデータをモデルに送信してライブ予測を生成できるようにするための、適切なユーザーインターフェイスがまだありません。幸いにも必要なのは、Chalice アプリケーションのエンドポイントにデータを POST するシンプルな HTML フォームのみです。
Amazon S3 はこの操作を簡単にします。
コマンドラインツールを使って、Amazon S3 でウェブサイトバケットを作成してみましょう。バケット名を選択し、次のコマンドを実行します。
次に、フロントエンドとして機能するためのサンプル HTML ファイルをバケットにアップロードする必要があります。サンプル HTML ファイルをダウンロードし、目的に合うように編集しましょう。ここの Chalice エンドポイントは、上記で deploy コマンドから保存した URI です。
index.html を見てみましょう。
このファイルの重要なところは、API Gateway エンドポイントを指すフォーム上でのアクションです。これにより、HTML ファイルはアップロードしたファイルを Lambda 関数に POST することができ、SageMaker エンドポイントと通信が可能となります。
HTML フロントエンドを作成したので、今度は、Amazon S3 ウェブサイトにアップロードする必要があります。以下のコマンドを実行します。
新しいユーザーインターフェイスは、次のような URL で利用可能となります: http://<bucket_name> .s3.amazonaws.com / index.html
まとめ
おめでとうございます! これで、Amazon SageMaker 上で構築、トレーニング、およびホストしたモデル用に、完全に機能するサーバーレスフロントエンドアプリケーションが完成しました。 このアドレスを使用すると、ユーザーがモデルに新しいデータを送信し、ライブ予測をオンザフライで作成できます。
ユーザーは、POST メソッドを使用してフォームデータを API Gateway に転送する Amazon S3 から静的 HTML ページにアクセスします。これで Amazon SageMaker が期待するフォーマットにデータを変換する Lambda 関数をトリガーします。その後、Amazon SageMaker はこの入力を受け取り、事前にトレーニングしたモデルを使って実行し、新しい予測を生成して AWS Lambda に返します。そして AWS Lambda が結果をユーザーに表示します。
これで、プロトタイピング、簡易デモ、小規模なデプロイメントではうまくいきますが、本番環境ではより安定したフレームワークを推奨します。これを行うには、サーバーレスアプローチは見送り、常時稼働のデプロイメント環境用の AWS Elastic Beanstalk フロントエンドを開発します。あるいは、完全にサーバーレスにすることも可能です。サーバーレス化するには、SageMaker エンドポイントの内容を Lambda 関数の中に実装する必要があります。このプロセスは ML フレームワークから ML フレームワークまで様々であり、このブログ記事の範囲外です。どの方法を選ぶかは、ご自分の製品ニーズ次第です。
もしこのアプリケーションを継続的に実行するつもりでないのであれば、Amazon S3 および Amazon SageMaker で使用した様々なリソースを、必ずクリーンアップするようにしてください。特に、エンドポイントを削除していること、およびアプリケーションを使用するよう変更されていないことを確認してください。
この広汎な構造を自由に利用して、Amazon SageMaker と AWS をベースに、より複雑でおもしろい独自のアプリケーションを作成してみてください。
参考文献
Dua, D. and Karra Taniskidou, E. (2017). UCI Machine Learning Repository. Irvine, CA: University of California, School of Information and Computer Science.
今回のブログ投稿者について
 Thomas Hughes は AWS プロフェッショナルサービスのデータサイエンティストです。カリフォルニア大学サンタバーバラ校で博士号を取得し、社会科学、教育、および宣伝広告における問題にチャレンジしてきました。現在、機械学習モデルを複雑なアプリケーションに組み込むためのベストプラクティスに取り組んでいます。
Thomas Hughes は AWS プロフェッショナルサービスのデータサイエンティストです。カリフォルニア大学サンタバーバラ校で博士号を取得し、社会科学、教育、および宣伝広告における問題にチャレンジしてきました。現在、機械学習モデルを複雑なアプリケーションに組み込むためのベストプラクティスに取り組んでいます。