Amazon Web Services ブログ
Amazon SageMaker と Apache Airflow でエンドツーエンドの機械学習ワークフローを構築する
機械学習 (ML) ワークフローは、データの収集と変換を可能にすることによって、一連の ML タスクを調整して自動化します。続いて、成果を達成する ML モデルのトレーニング、テスト、および評価が行われます。たとえば、Amazon SageMaker でモデルをトレーニングし、そのモデルを本番環境にデプロイして推論呼び出しを行う前に、Amazon Athena でクエリを実行するか、AWS Glue でデータ集約の準備を行うことがあります。これらのタスクを自動化し、複数のサービスにわたって調整を行うことで、繰り返し可能で再現可能な ML ワークフローを構築することができます。これらのワークフローは、データエンジニアとデータサイエンティストの間で共有できます。
概要
ML ワークフローは、モデルの精度を向上させ、より良い結果を得るために、循環的かつ反復的なタスクで構成されています。私たちは、最近、Amazon SageMaker との新しい統合を発表しました。統合により、これらのワークフローを構築および管理できます。
- AWS Step Functions は、エンドツーエンドのワークフローで Amazon SageMaker 関連のタスクを自動化および調整します。 Amazon S3 への公開データセットの自動化、Amazon SageMaker でデータの ML モデルのトレーニング、予測にモデルのデプロイすることができます。AWS Step Functions は、Amazon SageMaker およびその他のジョブが成功または失敗するまでモニタリングし、ワークフローの次のステップへ移行するか、ジョブを再試行します。それには内蔵エラー処理、パラメータ渡し、状態管理、実行中のMLワークフローの監視可能なビジュアルコンソールが含まれています。
- 現在、多くのお客様が Apache Airflow を使用しています。これは、複数ステージにわたるワークフローの作成、スケジューリング、およびモニタリングを行うための一般的なオープンソースフレームワークです。この統合により、モデルのトレーニング、ハイパーパラメータの調整、モデルのデプロイメント、バッチ変換など、複数の Amazon SageMaker 演算子が Airflow を利用できます。これにより、同じ調整ツールを使用して、Amazon SageMaker で実行されているタスクで ML ワークフローを管理できます。
このブログ記事では、Amazon Sagemaker と Apache Airflow を使用して ML ワークフローを構築および管理する方法について説明しています。類似動画に対する顧客の過去の評価、他に類似した顧客の行動に基づいて、特定の動画に対する顧客の評価を予測する推奨システムを構築します。Amazon のお客様から 160,000 件以上のデジタルビデオに対する 200 万以上の過去の星評価を使用しています。このデータセットについての詳細は、AWS Open Data ページからご覧ください。
高レベルのソリューション
まず、データの調査、データの変換、データ上のモデルのトレーニングから始めます。Amazon SageMaker のマネージド型トレーニングクラスターを使用して、ML モデルに適合させます。その後、テストデータセットのバッチ予測を実行するためにエンドポイントにデプロイします。これらすべてのタスクは、Apache Airflow と Amazon SageMaker との統合によって調整および自動化できるワークフローに組み込まれます。
次の図は、推奨システムを構築するために実装する ML のワークフローを示しています。

このワークフローは以下のタスクを実行します。
- データの前処理: Amazon S3 からデータを抽出および前処理して、トレーニングデータを準備します。
- トレーニングデータの準備: 推奨システムを構築するには、Amazon SageMaker の組み込みアルゴリズムである因数分解機を使用します。このアルゴリズムは、Float32 テンソルを使用した recordIO-protobuf 形式のトレーニングデータのみを想定しています。このタスクでは、前処理されたデータは RecordIO Protobuf 形式に変換されます。
- モデルのトレーニング: Amazon SageMaker の組み込み因数分解機モデルをトレーニングデータでトレーニングし、モデルアーティファクトを生成します。トレーニングジョブは、Airflow Amazon SageMaker の演算子によって開始されます。
- モデルのハイパーパラメータの調整: 最良のモデルを見つけるために、因子分解機のハイパーパラメータを調整する条件付き/任意タスク。ハイパーパラメータ調整ジョブは、Amazon SageMaker Airflow 演算子によって開始されます。
- バッチ推論: トレーニング済みモデルを使用して、Airflow Amazon SageMaker 演算子で Amazon S3 に保存されているテストデータセットの推論を取得します。
注意: このブログ記事で参照されているスクリプト、テンプレート、ノートブックの GitHub リポジトリを複製できます。
Airflow の概念と設定
ソリューションを実装する前に、Airflow の概念についての理解を深めましょう。すでに Airflow の概念に精通している場合は、「Amazon SageMaker の Airflow 演算子」セクションにスキップしてください。
Apache Airflow は、ワークフローとデータ処理パイプラインを調整するためのオープンソースツールです。Airflow を使用すると、Python を用いたプログラムでデータパイプラインを構成、スケジュール、およびモニタリングして、従来のワークフロー管理ライフサイクルのすべてのステージを定義できます。
Airflow 用語体系
- DAG (Directed Acyclic Graph): DAG は、Python でパイプラインを定義することによってワークフローを実行する方法、つまりコードとしての設定について説明します。パイプラインは、独立して実行できるタスクにパイプラインを分割することによって、有向非循環グラフとして設計されています。その後、これらのタスクはグラフとして論理的に結合されます。
- 演算子: 演算子は、パイプラインの単一タスクを記述する DAG 内のアトミックコンポーネントです。DAG の実行時に、そのタスクで行う動作を決定します。Airflow は、一般的なタスクに演算子を提供します。これは拡張可能であるため、カスタム演算子を定義できます。Airflow Amazon SageMaker 演算子は、Airflow と Amazon SageMaker を統合するために AWS が提供したこれらのカスタム演算子の 1 つです。
- タスク: 演算子がインスタンス化された後は「タスク」と呼ばれます。
- タスクインスタンス: タスクインスタンスは、DAG、タスク、およびある一時点にを特徴とするタスク固有の実行を表します。
- スケジューリング: DAG とタスクはオンデマンドで実行することも、DAG でクーロン式として定義された特定頻度で実行するようにスケジュールすることもできます。
Airflow アーキテクチャ
次の図は、Airflow アーキテクチャの一般的なコンポーネントを示しています。
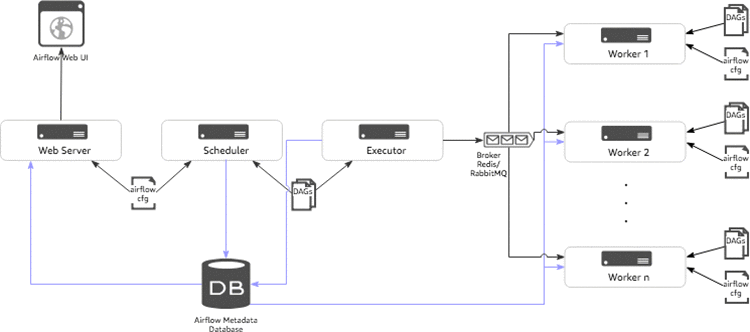
- スケジューラ: スケジューラは、DAG とタスクをモニタリングし、依存関係が満たされたタスクインスタンスをトリガーする永続的なサービスです。スケジューラは、Airflow 設定で定義されたエグゼキュータを呼び出す責任があります。
- エグゼキュータ: エグゼキュータは、タスクインスタンスを実行するためのメカニズムです。Airflow にはデフォルトでさまざまな種類のエグゼキュータが用意されており、Kubernetes エグゼキュータなどのカスタムエグゼキュータを定義できます。
- ブローカー: ブローカーはメッセージ (実行されるタスクのリクエスト) をキューに入力して、エグゼキュータとワーカーの間のコミュニケーターとして機能します。
- ワーカー: タスクが実行され、タスクの結果を返す実際のノード。
- ウェブサーバー: Airflow UI をレンダリングするためのウェブサーバー。
- 構成ファイル: 使用するエグゼキュータ、airflow メタデータのデータベース接続、DAG、リポジトリ場所などの設定を構成します。同時実行や並列性の制限なども定義できます。
- メタデータのデータベース: DAG、DAG 実行、タスク、変数、および接続に関連するすべてのメタデータを格納するためのデータベース。
Airflow Amazon SageMaker 演算子
Amazon SageMaker 演算子は、Airflow が Amazon SageMaker と対話して次の ML タスクを実行できるようにする、Airflow インストールで使用可能なカスタム演算子です。
- SageMakerTrainingOperator: Amazon SageMaker トレーニングジョブを作成します。
- SageMakerTuningOperator: AmazonSageMaker ハイパーパラメータ調整ジョブを作成します。
- SageMakerTransformOperator: Amazon SageMaker バッチ変換ジョブを作成します。
- SageMakerModelOperator: Amazon SageMaker モデルを作成します。
- SageMakerEndpointConfigOperator: Amazon SageMaker エンドポイント設定を作成します。
- SageMakerEndpointOperator: 推論呼び出しを行うための Amazon SageMaker エンドポイントを作成します。
このブログ記事の「機械学習ワークフローの構築」セクションで、演算子の使用方法を確認します。
Airflow 設定
スケジューラ、ワーカー、およびウェブサーバーを単一のインスタンスで実行する単純な Airflow アーキテクチャを設定します。通常、本番ワークロードではこの設定を使用しません。このブログ記事では、AWS CloudFormation を使用してコンポーネントの作成に必要な AWS サービスを起動します。次の図は、デプロイされるアーキテクチャの構成を示します。

このスタックには、次のものが含まれます。
- Airflow コンポーネントを設定するための Amazon Elastic Compute Cloud (EC2)。
- Airflow メタデータのデータベースをホストする Amazon Relational Database Service (RDS) Postgres インスタンス。
- Amazon SageMaker モデルのアーティファクト、出力、および ML ワークフロー付き Airflow DAG を格納するための Amazon Simple Storage Service (S3) バケット。テンプレートは S3 バケット名の入力を求めます。
- Airflow コンポーネントがメタデータのデータベース、S3 バケット、および Amazon SageMaker と対話できるようにするための AWS Identity and Access Management (IAM) ロールと Amazon EC2 セキュリティグループ。
この CloudFormation スクリプトを実行するための前提条件は、たとえば、トラブルシューティングやカスタム演算子の追加を行う場合、Airflow を管理するためにログインするように Amazon EC2 キーペアを設定することです。
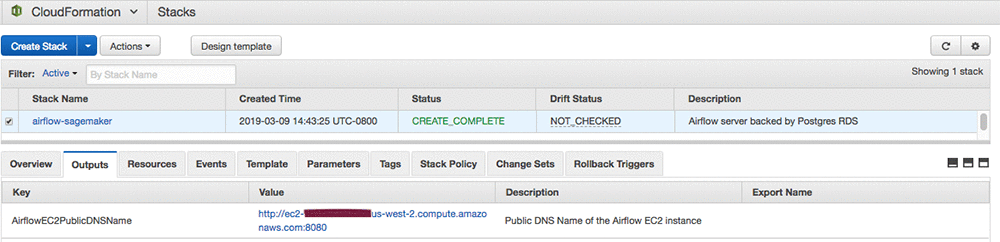
![]()
CloudFormation スタックがリソースを作成するまで最大 10 分かかることがあります。リソースの作成が完了したら、Airflow ウェブ UI にログインできるはずです。Airflow ウェブサーバーは、デフォルトでポート 8080 で動作します。Airflow のウェブ UI を表示するには、ブラウザを開き http://ec2-public-dns-name:8080 と入力します。EC2 インスタンスのパブリック DNS 名は、AWS CloudFormation コンソールの CloudFormation スタックの [出力] タブにあります。
機械学習のワークフローの構築
このセクションでは、Amazon SageMaker 演算子を含む Airflow 演算子を使用して推薦を作成する ML ワークフローを作成します。 手引きとなる Jupyter ノートブックをダウンロードして、ML ワークフローで使用される個々のタスクを確認することができます。ここでは最も重要な部分を強調します。

データの前処理
- 前述のように、このデータセットには、Amazon のお客様から 160,000 件以上のデジタルビデオに対する 200 万以上の評価が含まれています。データセットの詳細についてはこちらをご覧ください。
- データセットを分析した結果、5 件以上のビデオを評価したお客様は約 5% のみで、9 人以上のお客様が評価したビデオは 25% にすぎません。レコードをフィルタリングして、このロングテールをクリーンします。
- クリーンアップ後、各顧客とビデオに、評価行列の行と列を示す独自の順次インデックスを指定して、データをスパース形式に変換します。次のタスクでピックアップして処理するために、このクリーンされたデータを S3 バケットに格納します。
- Airflow DAG の次の
PythonOperatorスニペットは、前処理関数を呼び出します。
注意: このブログ記事では、データ前処理タスクは Pandas パッケージを使用して Python で実行されます。タスクは Airflow ワーカーノードで実行されます。大規模なデータセットを取り扱う場合は、このタスクを AWS Glue または Amazon EMR で実行されているコードに置き換えることができます。
データ準備
- 私たちは Amazon SageMaker の 因数分解機 (FM) 実装を使用して、推奨システムを構築しています。アルゴリズムは、recordIO protobuf 形式の Float32 テンソルを想定しています。クリーンされたデータセットはディスク上の Pandas DataFrame です。
- データ準備の一環として、Pandas DataFrame は、顧客とビデオでワンホットエンコードされた特徴ベクトルを持つスパース行列に変換されます。したがって、データセット内の各サンプルは、顧客とビデオの 2 つの値のみが 1 に設定された広いブール値ベクトルになります。
顧客 1 顧客 2 … 顧客 N ビデオ 1 ビデオ 2 … ビデオ m 1 0 … 0 0 1 … 0 - データ準備タスクでは、次のステップが実行されます。
- クリーン済みのデータセットをトレーニングデータセットとテストデータセットに分割します。
- ワンホットエンコードされた特徴ベクトル (顧客 + ビデオ) と星評価を持つラベルベクトルを使用してスパース行列を作成します。
- 両方のセットを protobuf エンコードファイルに変換します。
- モデルをトレーニングするために、準備したファイルを Amazon S3 バケットにコピーします。
- Airflow DAG の次の
PythonOperatorスニペットは、データ準備関数を呼び出します。
モデルのトレーニングと調整
- Airflow Amazon SageMaker 演算子を使用してトレーニングジョブを開始することで、Amazon SageMaker 因数分解機のアルゴリズムをトレーニングします。モデルをトレーニングする方法にはいくつかがあります。
SageMakerTrainingOperatorを使用して、正常に機能することが分かっているハイパーパラメータをデータに設定してトレーニングジョブを実行します。SageMakerTuningOperatorを使用してハイパーパラメータ調整ジョブを実行し、データセット上のさまざまなハイパーパラメータをテストする多数のジョブを実行して最良のモデルを見つけます。
- 最良のモデルを見つけるために、トレーニングジョブを直接実行するか、ハイパーパラメータ調整ジョブを実行するかを決定する条件付きタスクを Airflow DAG に作成できます。これらのタスクは同期モードまたは非同期モードで実行できます。
- トレーニングジョブまたは調整ジョブの進行状況は、Airflow タスクインスタンスログでモニタリングできます。
モデルの推論
- Airflow
SageMakerTransformOperatorを使用して、テストデータセットに対してバッチ推論を実行してモデルのパフォーマンスを評価する Amazon SageMaker バッチ変換ジョブを作成します。 - 本番環境にモデルをデプロイする前に、実際の顧客評価と予測された顧客評価を比較してモデルのパフォーマンスを検証するタスクを追加することで、ML ワークフローをさらに拡張できます。
次のセクションでは、これらすべてのタスクをまとめて Airflow DAG で ML ワークフローを形成する方法について説明します。
すべてをまとめる
Airflow DAG は、これまで説明してきたすべてのタスクを ML ワークフローとして統合しています。Airflow DAG は、個々のタスクを Airflow 演算子で表現し、タスクの依存関係を設定し、それらのタスクを DAG に関連付けて、オンデマンドまたはスケジュールされた間隔で実行する Python スクリプトです。Airflow DAG スクリプトは次のセクションに分かれています。
- スケジュール間隔、同時実行などのパラメータを使用して DAG を設定します。
- Amazon SageMaker Python SDK for Airflow を使用して、各演算子のトレーニング、調整、および推論設定をセットアップする
- トリガールールを定義し、それらを DAG オブジェクトに関連付ける Airflow 演算子を使用して個々のタスクを作成します。これらの個々のタスクを定義するには、前のセクションを参照してください。
- タスクの依存関係を指定します。
DAG の準備ができたら、CI/CD パイプラインを使用して DAG をAirflow DAG リポジトリにデプロイします。Airflow 設定で概説した設定に従った場合、Airflow コンポーネントをインストールするためにデプロイされた CloudFormation スタックは、推奨システムを構築するための ML ワークフローを持つ Airflow インスタンスのリポジトリに Airflow DAG を追加します。ここから Airflow DAG コードをダウンロードしてください。

DAG をオンデマンドまたはスケジュールでトリガーした後は、ツリービュー、グラフビュー、ガントチャート、タスクインスタンスログなど、さまざまな方法で DAG をモニタリングできます。Airflow DAG を作成およびモニタリングする方法については、Airflow のドキュメントを参照してください。
クリーンアップ
最後のステップでは、リソースをクリーンアップします。
AWS アカウントでの不要な請求を避けるために、次のステップを実行します。
- 実験が終わったらスタックを削除して、Airflow で CloudFormation スタックによって作成されたすべてのリソースを破棄します。スタックを削除するには、ここに記載されたステップに従ってください。
- AWS CloudFormation は、空ではない Amazon S3 バケットを削除できないため、CloudFormation スタックによって作成された S3 バケットを手動で削除する必要があります。
結論
このブログ記事では、ML ワークフローの構築にかなりの準備が必要であることをお見せしました。しかし、この構築は、実験の速度、エンジニアリングの生産性、および繰り返し行われる ML タスクのメンテナンスを改善する場合に役立ちます。Airflow Amazon SageMaker 演算子は、ML ワークフローを構築し、Amazon SageMaker と統合するための便利な方法を提供します。
特徴エンジニアリング、トレーニングモデルのアンサンブル作成、並列トレーニングジョブの作成、およびデータ分布の変化に適応するためのモデルの再トレーニングなど、ML のワークフローに適したタスクで Airflow DAG をカスタマイズすることで、ワークフローを拡張できます。
参考文献
- Airflow Amazon SageMaker 演算子の詳細については、Amazon SageMaker SDK のドキュメントと Airflow のドキュメントを参照してください。
- このブログ記事で使用されている因数分解機アルゴリズムについては、Amazon SageMaker のドキュメントを参照してください。
- このブログ記事で参照されているリソース (Jupyter ノートブック、CloudFormation テンプレート、および Airflow DAG コード) は GitHub リポジトリからダウンロードできます。
ご質問またはご提案については、以下のコメント欄をご利用ください。
著者について
 Rajesh Thallam は、AWS のプロフェッショナルサービスアーキテクトであり、お客様が AWS でビッグデータと Machine Learning のワークロードを実行できるように支援しています。空き時間には、家族と過ごしたり、旅行に行ったり、テクノロジーを日常生活に取り入れる方法を模索しています。彼は、このブログ記事の作成を手伝ってくれた同僚の David Ping と Shreyas Subramanian に感謝の言葉を告げていました。
Rajesh Thallam は、AWS のプロフェッショナルサービスアーキテクトであり、お客様が AWS でビッグデータと Machine Learning のワークロードを実行できるように支援しています。空き時間には、家族と過ごしたり、旅行に行ったり、テクノロジーを日常生活に取り入れる方法を模索しています。彼は、このブログ記事の作成を手伝ってくれた同僚の David Ping と Shreyas Subramanian に感謝の言葉を告げていました。