Amazon Web Services ブログ
機械学習と感度分析を組み合わせてビジネス戦略を開発する
機械学習 (ML) は、意思決定を支援するために無数の企業で日常的に使用されています。ただし、ほとんどの場合、ML システムによる予測とビジネス上の決定には、判断を下すために人間のユーザーの直感がまだ必要です。
この記事では、ML を感度分析と組み合わせて、データ駆動型のビジネス戦略を開発する方法を示します。この記事では、顧客の解約 (つまり、競合他社への顧客の離反) に焦点を当て、ML ベースの分析を使用するときにしばしば発生する問題を取り上げます。これらの問題には、不完全で不均衡なデータの処理、戦略的オプションの導出、およびそれらのオプションの潜在的な影響の定量的評価に関する困難が含まれます。
具体的には、ML を使用して解約する可能性の高い顧客を特定し、機能の重要性とシナリオ分析を組み合わせて定量的および定性的な推奨事項を導き出します。次に、組織はその結果を使用して、将来の解約を減らすための適切な戦略的および戦術的決定を下すことができます。このユースケースは、以下のように、データサイエンスを実践する際に発生するいくつかの一般的な問題を示しています。
- 低い信号と雑音比と、特徴と解約率の間の明確な相関関係の欠如
- 非常に不均衡なデータセット (データセット内の顧客の 90% が解約しない)
- 確率論的な予測と調整を使用した、解約問題への過剰投資のリスクを最小限に抑える意思決定メカニズムの特定
エンドツーエンドの実装コードは、Amazon SageMaker で利用でき、Amazon EC2 でスタンドアロンとして利用できます。
このユースケースでは、さまざまなタイプの製品を提供する架空の会社を考えます。その会社の 2 つの主要な製品を製品 A と製品 B と呼びます。会社の製品と顧客に関して部分的な情報しか持っていません。同社は最近、競合他社への顧客離反 (解約とも) が増加している様を見ています。データセットには、数か月にわたって収集およびソートされた数千の顧客の多様な属性に関する情報が含まれています。これらの顧客の一部は解約しており、一部はそのままです。特定の顧客のリストを使用して、個人が解約する確率を予測します。このプロセス中、次のいくつかの質問に対して回答しようと思います。顧客離れの信頼できる予測モデルは作成できるのか? 顧客が解約する可能性を説明する変数は何か? 会社は解約を減らすためにどのような戦略を実行できるか?
この記事では、ML モデルを使用して解約削減戦略を策定するための次の手順について説明します。
データの探索と新機能のエンジニアリング
最初に、個々の入力機能と解約ラベルの間の単純な相関関係と関連性を調べて、顧客データを探索する方法を説明します。また、機能自体の間の関連付け (相互相関、または共分散と呼ばれる) も調べます。これにより、アルゴリズムの決定、特に、どの機能を派生、変更、または削除するかを決定できます。
ML モデルのアンサンブルの開発
次に、自動機能選択を含むいくつかの ML アルゴリズムを構築し、複数のモデルを組み合わせてパフォーマンスを向上させます。
ML モデルのパフォーマンスの評価と改善
3 番目のセクションでは、開発したさまざまなモデルのパフォーマンスをテストします。そこから、解約する顧客の数を過大評価するリスクを最小限に抑える意思決定メカニズムを特定します。
ビジネス戦略設計への ML モデルの適用
最後に、4 番目のセクションでは、ML の結果を使用して、顧客の解約に影響する要因を理解し、戦略的オプションを導き出し、解約率に対するこれらのオプションの影響を定量的に評価します。そのためには、感度分析を実行します。この分析では、実際の生活で制御できるいくつかの要因 (割引率など) を変更し、この制御要因のさまざまな値で予想される解約の減少を予測します。すべての予測は、セクション 3 で特定した最適な ML モデルを使用して実行されます。
データの探索と新機能のエンジニアリング
ML モデルの開発中にしばしば問題を引き起こす重大な問題には、入力データ内の共線性および低分散の特徴の存在、外れ値の存在、および欠損データ (欠損した特徴と一部の特徴の欠損値) が含まれます。このセクションでは、Amazon SageMaker を使用して Python 3.4 でこれらの各問題を処理する方法について説明します。(Deep Learning AMI を使用して Amazon EC2 インスタンスのスタンドアロンコードも評価しました。どちらも利用可能です)。
この種類のタイムスタンプ付きデータには、特定のメトリクス内の重要なパターンが含まれる場合があります。これらのメトリクスを毎日、毎週、毎月のセグメントに集約し、メトリクスの動的な性質を説明する新しい機能を開発できました。(詳細については、付属のノートブックを参照してください)。
次に、元の機能と新しい機能の両方の個々の機能間の単純な 1 対 1 (別名限界) 相関および関連付けの測定値を見ていきます。また、機能と解約ラベルの間の相関関係も調べます。(下図を参照してください)。
次の表に示すように、解約ラベルが変更されても大幅に変更されない低分散機能は、限界相関とハミング距離/ジャッカード距離を使用して処理できます。ハミング/ジャッカード距離は、バイナリ結果のために特別に設計された類似性の測定値です。これらの測定値は、各機能が解約を示す可能性の程度についての見通しを提供します。
予測しようとしているものに関係なく、あまり変化しない傾向があるため、低分散の特徴を削除することをお勧めします。その結果、それらの存在は分析に役立ちそうになく、実際に学習プロセスの効率を低下させる可能性があります。
次のテーブルは、特徴と解約の間の上位相関とバイナリ非類似度を示しています。48 個の元の機能と派生機能のうち、上位の機能のみが表示されます。Filtered 列には、外れ値と欠損値のデータをフィルター処理したときに得られた結果が含まれています。
| 解約とのピアソン相関 | ||
| 機能 | オリジナル | フィルター済み |
| マージン | 0.06 | 0.1 |
| 予測製品 A | 0.03 | 0.04 |
| 料金 | 0.03 | 0.04 |
| $value 割引 | 0.01 | 0.01 |
| 現在のサブスクリプション | 0.01 | 0.03 |
| 予測製品 B | 0.01 | 0.01 |
| 製品数 | -0.02 | -0.02 |
| カスタマーロイヤルティ | -0.07 | -0.07 |
| 解約とのバイナリ非類似性 | ||
| 機能 | ハミング | ジャッカード |
| 販売チャネル 1 | 0.15 | 0.97 |
| 販売チャネル 2 | 0.21 | 0.96 |
| 販売チャネル 3 | 0.45 | 0.89 |
上記の表からわかる重要なポイントは、3 つの販売チャネルが解約と逆相関しているように見えることと、解約とのほとんどの限界相関が非常に小さいことです (≤0.1)。外れ値と欠損値にフィルターを適用すると、統計的有意性が向上した限界相関が生じます。前の表の右の列は、この効果を示しています。
共線性の機能の問題は、次の図に示すように、すべての機能間の共分散行列を計算することで対処できます。この行列は、一部の機能が持つ冗長性の量に関する新しい視点を提供します。バイアスを作成し、より多くの計算を必要とするため、冗長な機能を削除することをお勧めします。これも学習プロセスの効率を低下させます。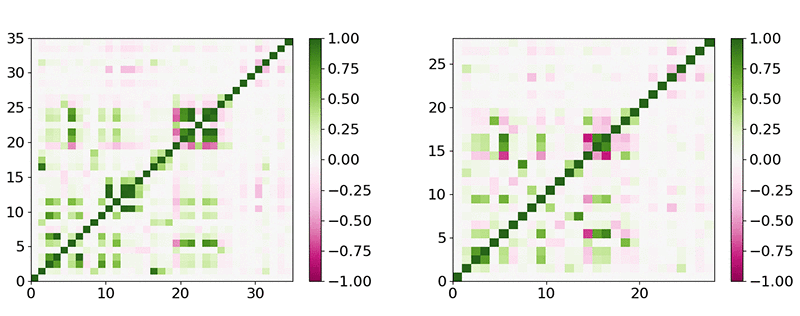
前の図の左のグラフは、料金や予測されるメトリクスなどの一部の機能が、ρ > 0.95 で共線的であることを示しています。前の図の右のグラフが示すように、次のセクションで説明する ML モデルを設計したときに、それぞれ 1 つだけを保持し、約 40 の機能を残しました。
データの欠損や異常値の問題は、記録されたデータ値の一部が欠損している場合や、サンプル全体で標準偏差の 3 倍を超える場合に観測値 (顧客) を削除するなど、経験則を当てはめることで対処することがよくあります。
欠損データは頻繁に懸念されるため、観測値を削除する代わりに、サンプルまたは母集団全体の平均値または中央値で欠損値を代入することができます。それがここでやったことです。欠損値を各機能の中央値に置き換えたのです。ただし、データの 40% 以上が欠落している機能を除きます。その場合は機能全体を削除しました。読者は、欠損データを代入するためのより高度なベストプラクティスアプローチは、教師あり学習モデルをトレーニングして他の機能に基づいて代入することですが、これには非常に大きな労力が必要になる可能性があるため、ここでは説明しません。データで異常値に遭遇したとき、平均から 6 標準偏差を超える値を持つ顧客を削除しました。合計で、16096 個の観測のうち 140 個 (< 1%) の観測を削除しました。
ML モデルのアンサンブルの開発
このセクションでは、複数の ML モデルを開発および組み合わせて、複数の ML アルゴリズムの能力を活用します。次のフローチャートに示すように、解約ラベルの分布が非常に不均衡であっても、アンサンブルモデリングを使用すると、データセット全体からの情報を使用することもできます。
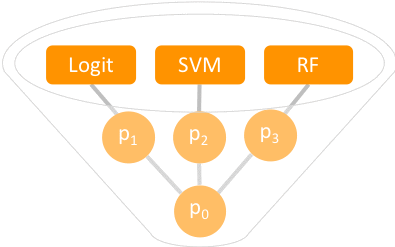
予測確率
p0 = (p1 + p2 + p3) / 3
低分散機能を削除することがお勧めであるため、迅速かつ簡単な分散フィルターを適用して、機能スペースを最も重要な機能にさらに制限しました。このフィルターは、95% を超える顧客に差異を表示しない機能を削除します。限界効果とは対照的に、顧客の解約に対する複合効果に基づいて機能をフィルタリングするために、段階的回帰によるグリッド検索を使用して ML ベースの機能選択を実行しました。詳細については、次のセクションをご覧ください。
ML モデルを実装する前に、データを 2 つのグループにランダムに分割し、30% のテストセットを保持しました。次のセクションで説明するように、70%/30% 分割に加えて 10 倍の交差検証も使用しました。K-folding は、K の評価でパフォーマンスを平均化する反復サイクルです。各テストは、データの個別の K% ホールドアウトセットでテストします。
ロジスティック回帰、サポートベクターマシン、およびランダムフォレストの 3 つの ML アルゴリズムは個別にトレーニングされ、前のフローチャートに示すようにアンサンブルに結合されました。アンサンブルアプローチは、文献では soft-voting と呼ばれます。これは、異なるモデルの平均確率を取得し、それを使用して顧客の解約を分類するためです (前のフローチャートでも表示)。
解約した顧客は、データのわずか 10% にすぎません。したがって、データセットは不均衡です。クラスの不均衡に対処する 2 つのアプローチをテストしました。
- 最初の最も簡単なアプローチでは、トレーニングは、まれなクラス (変化した顧客) のサイズに合わせて、豊富なクラス (解約しなかった顧客) のランダムサンプリングに基づいています。
- 2 番目のアプローチ (次のチャートに示す) では、豊富なクラスの 9 つのランダムサンプル (置換なし) と各モデルのまれなクラスの完全なサンプルを使用して、9 つのモデルのアンサンブルに基づいてトレーニングを行いました。クラスの不均衡が約 1 から 9 であるため、9 倍を選択しました (次の図のヒストグラムに示すように)。したがって、1〜9 は、豊富なクラスのすべてまたはほぼすべてのデータを使用するために必要なサンプリング量です。このアプローチはより複雑ですが、利用可能なすべての情報を使用して、一般化を改善します。次のセクションでその有効性を評価します。

両方のアプローチについて、実世界の状況を考慮してクラスの不均衡が維持されるテストセットでパフォーマンスが評価されます。
ML モデルのパフォーマンスの評価と改善
このセクションでは、前のセクションで開発したさまざまなモデルのパフォーマンスをテストします。次に、解約する可能性のある顧客の数を過大評価するリスク (誤検知率と呼ばれる) を最小限に抑える意思決定メカニズムを特定します。
いわゆるレシーバー-オペレーター特性 (ROC) 曲線は、分割表を補完するために ML パフォーマンス評価でよく使用されます。ROC 曲線は、正のクラスと負のクラスを推測するために確率しきい値を変更するときに、精度が不変の尺度を提供します (このプロジェクトでは、それぞれ解約ありと解約なし)。これには、フォールアウトとも呼ばれる偽陽性に対するすべての正確な陽性予測 (真陽性) のプロットが含まれます。次の表を参照してください。
異なる ML モデルによって予測される確率は、デフォルトでは、p > 0.5 の値が 1 つのクラスに対応し、p < 0.5 の値が他のクラスに対応するように調整されます。このしきい値は、1 つのクラスの誤分類されたインスタンスを最小限に抑えるために微調整できるハイパーパラメータです。これは、他の分類ミスの増加を犠牲にしており、異なるパフォーマンス測定の正確性と精度に影響を与える可能性があります。対照的に、ROC 曲線の下の領域は、パフォーマンスの不変尺度です。どのしきい値でも同じままです。
次の表は、まれなクラス (ベースライン) と学習者の 9 倍アンサンブルのランダムサンプリングを使用した、さまざまな ML モデルのパフォーマンスを示しています。ランダムフォレストのパフォーマンスが最高であり、さらに ROC AUC スコアが 0.68 で、9 倍アンサンブルの一般化が優れていることがわかります。このモデルは最高のパフォーマンスを発揮します。
| パフォーマンス測定値 | ||||
| アルゴリズム | 精度 | Brier | ROC | |
| Logit | 56% | 0.24 | 0.64 | |
| 段階的 | 56% | 0.24 | 0.64 | |
| SVM | 57% | 0.24 | 0.63 | |
| RF | 65% | 0.24 | 0.67 | |
| アンサンブル | 61% | 0.23 | 0.66 | |
| 9-Logit アンサンブル | 55% | 0.26 | 0.64 | |
| 9-SVM アンサンブル | 61% | 0.25 | 0.63 | |
| 9-RF アンサンブル | 70% | 0.24 | 0.68 | |
| 9-Ensemble アンサンブル | 61% | 0.25 | 0.65 | |
次のグラフは、全体的なベストラーナー (ランダムフォレストラーナーの 9 倍アンサンブル) のパフォーマンスと、精度とフォールアウトの最適化を示しています。0.5 の確率しきい値を使用する場合、最高のパフォーマンスを発揮する顧客は、解約する可能性のある顧客の 69% を予測できますが、42% から大幅に減少します。
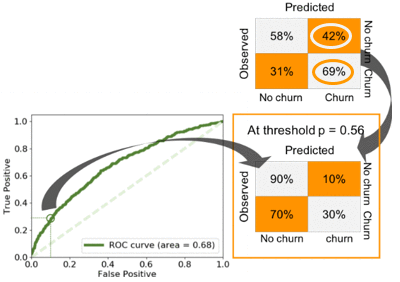
ROC 曲線を見ると、同じモデルで解約する顧客の 30% を予測でき、フォールアウトは 10% に最小化されていることがわかります。グリッド検索を使用して、しきい値が p = 0.56 であることがわかりました。解約する顧客の数を過大評価するリスクを最小限に抑えたい場合 (たとえば、これらの顧客を維持しようとする試みが高額になる可能性があるため)、このモデルを使用したいと思うかもしれません。
ビジネス戦略設計への ML モデルの適用
このセクションでは、私が開発した ML モデルを使用して、顧客の解約に影響を与える要因をよりよく理解し、解約を減らすための戦略的オプションを導き出し、それらのオプションのデプロイが解約率に与える定量的な影響を評価します。
段階的ロジスティック回帰を使用して、解約に対する複合効果を考慮に入れながら、機能の重要性を評価しました。次のグラフに示すように、回帰により 12 の主要な機能が特定されます。これらの 12 の機能を回帰モデルに含めると、予測スコアが最高になります。
これらの 12 の要因のうち、純利益率、製品 A と製品 B の購入予測、および複数製品の顧客を示すインデックスは、解約を引き起こす傾向が最も大きい機能です。解約率を削減する傾向があった要因には、3 つの販売チャネル、1 つのマーケティングキャンペーン、割引の価値、全体的なサブスクリプション、顧客の忠誠心、購入した製品の総数が含まれます。
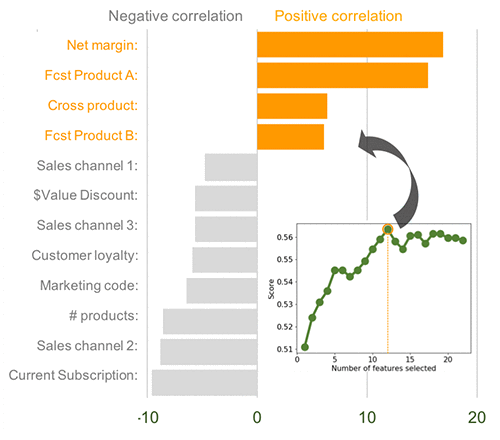
したがって、解約の傾向が最も高い顧客に割引を提供することは、シンプルで効果的な戦略のようです。製品 A と 製品 B 以外の製品、販売チャネル 1〜3、マーケティングキャンペーン、および長期契約間の相乗効果を高めるなど、他の戦略的手段も特定されています。データによると、これらのレバーを引くと、顧客離れが減少する可能性が高くなります。
最後に、感度分析を使用しました。ML モデルが解約する可能性があると特定した顧客に最大 40% の割引を適用し、モデルを再実行して、割引を組み込んだ後も解約すると予測される顧客の数を評価しました。
フォールアウトを 10% に最小化するためにモデルを p しきい値 0.6 に設定すると、この記事の分析では、20% の割引により解約が 25% 減少すると予測しています。このしきい値での真陽性率は約 30% であるため、この分析は 20% の割引アプローチにより解約の少なくとも 8% を排除できることを示しています。詳細については、次のグラフを参照してください。割引戦略は、顧客の解約を経験している組織が問題を軽減するために検討する可能性のある簡単な最初のステップです。

まとめ
この記事では、次の方法を示しました。
- データの探索と新しい機能の導出により、データの欠損と低い信号と雑音比に起因する問題を最小限に抑えます。
- ML モデルのアンサンブルを設計して、非常に不均衡なデータセットを処理します。
- 最適なモデルを選択し、意思決定のしきい値を調整して、精度を最大化し、フォールアウトを最小限に抑えます。
- 結果を使用して戦略的オプションを導き出し、解約率への影響を定量的に評価します。
この特定の使用例では、フォールアウトを 10% に制限しながら、解約する可能性が高い顧客の 30% を識別できるモデルを開発しました。この研究は、より多くの顧客を維持するために、サービスと販売チャネル間の相乗効果の構築に基づいて、割引を提供する短期戦略を展開し、長期戦略を制定する有効性をサポートします。
このブログ記事で説明されているデータと洞察を生成するコードを実行したい場合は、ノートブックと関連データファイルをダウンロードし、各セルを一度に 1 つずつ実行してください。
著者について
 Jeremy David Curuksu は、Amazon Machine Learning Solutions Lab (AWS) の AI-ML のデータサイエンティスト兼コンサルタントです。応用数学で修士号と博士号を取得し、スイス連邦工科大学ローザンヌ校 (スイス) とマサチューセッツ工科大学 (米国) でリサーチサイエンティストを務めました。科学に関する審査を受けた論文の著作が数多くあり、彼の『 Data Driven 』という著作では、データサイエンスの新時代における経営コンサルティングを紹介しています。
Jeremy David Curuksu は、Amazon Machine Learning Solutions Lab (AWS) の AI-ML のデータサイエンティスト兼コンサルタントです。応用数学で修士号と博士号を取得し、スイス連邦工科大学ローザンヌ校 (スイス) とマサチューセッツ工科大学 (米国) でリサーチサイエンティストを務めました。科学に関する審査を受けた論文の著作が数多くあり、彼の『 Data Driven 』という著作では、データサイエンスの新時代における経営コンサルティングを紹介しています。