Amazon Web Services ブログ
TensorFlow で行うスケーラブルなマルチノードトレーニング
お客様から、TensorFlow トレーニングのジョブを複数のノードや GPU にスケーリングすることは難しいとの声を聞きました。TensorFlow には分散トレーニングが組み込まれていますが、使用するのは難しい場合があります。最近、TensorFlow と Horovod を最適化し、AWS のお客様が TensorFlow のトレーニングジョブを複数のノードや GPU に拡張できるようにしました。これらの改善により、AWS のお客様は、15 分以内に ImageNet の ResNet-50 をトレーニングするために AWS Deep Learning AMI を使用することができます。
これを実現するため、32 個のAmazon EC2 インスタンス (それぞれ 8 GPU、合計 256 GPU) が TensorFlow で利用できます。このソリューションに必要なソフトウェアとツールは、すべて最新の Deep Learning AMI (DLAMI) に付属しているので、自分で試すことができます。 より早くトレーニングし、モデルをより速く実装し、結果を以前より速く得ることができます。 このブログの記事では、得られた結果について説明し、さらに TensorFlow で分散トレーニングを実行するための簡単で迅速な方法をご紹介ます。

図A. Deep Learning AMI 上で、Horovod を使用した、最新の最適化された TensorFlow で行う ResNet-50 ImageNet モデルトレーニングには、256 GPU で 15 分かかります。
大型モデルのトレーニングは時間がかかり、モデルが大きく複雑になればなるほど、トレーニングにかかる時間が長くなります。定期的に更新されたモデルを生成することがビジネス要件である場合、トレーニングに時間がかかり過ぎると機会を逃してしまいます。通常の対応は、問題に対してより多くの処理能力を投入することですが、深層学習では、トレーニング中の通信オーバーヘッドにより、このアプローチは実行不可能になったり非常に高価になったりします。この通信オーバーヘッドにより、効率を低下させ、スループットを大幅に低下させ、トレーニング時間を増加させてしまいます。また、必要なインフラストラクチャを設定し、必要なレベルの精度に達することも難しくなる可能性があります。 TensorFlow は分散トレーニングをネイティブにサポートしていますが、行った実験では、Horovod を組み込んだときに、スピードと正確さの両方の点で優れた結果が得られました。
Horovod は、分散トレーニングで人気の選択肢です。気候変動を分析するために 27,000 GPU の Horovod を使用した例が最近ありました。適切なツーリングがなければ、この数の GPU をオーケストレーションすることは不可能です。Horovod では、ソフトウェアの最適化と Amazon EC2 p3 インスタンスを使用して、効率損失を 15% に制限でき、訓練時間が 15 分以内に収まりました。
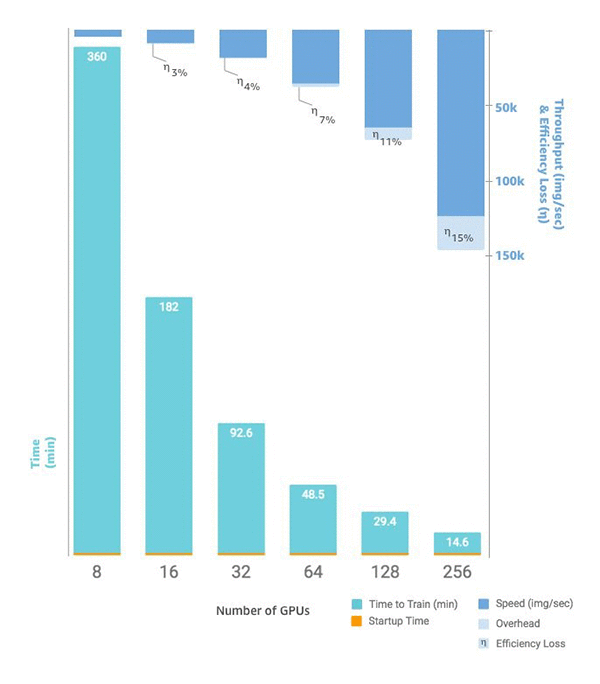
図 B. トレーニング時間、GPU 数と 1 秒あたりの画像数の比較、通信オーバヘッド、効率性。起動時間は、クラスタのサイズに関係なく一貫して 1.5 分です。
これを試すために必要なツールはすべて、最新の DLAMI に同梱されています。これには、ResNet-50 を ImageNet でトレーニングするためのサンプルスクリプトも含まれています。腕まくりをして今すぐ試してみる準備ができたら、続けて読んでください。このブログ記事の残りの部分では、EC2 p3 インスタンス、TensorFlow、Horovod を使用して 15 分以内に ImageNet の ResNet-50 をトレーニングする方法をご紹介します。
TensorFlow を使って 15 分以内に ResNet/ImageNet をトレーニングする方法
私は最初に、Deep Learning AMI (DLAMI) で Horovod with TensorFlow を試しました。Horovod を使って ImageNet を 8-GPU の EC2 インスタンスでトレーニングするためのチュートリアルを書くように求められました。Uber が自社の分散トレーニングフレームワークを「Horovod」と命名したとき、Uber が何を考えているのか疑問に思いました。 ImageNet のトレーニングは永遠に終わらず、Horovod は Harry Potter の世界の悪役か何かのように聞こえました。でもそうではありません。それを作成したのは、Uber の Alexander Sergeev です。彼は、大人数のダンサーグループが円になって同期した動きでパフォーマンスを行うロシアと東ヨーロッパのフォークダンスから、「Horovod」と名付けました。1 つの DLAMI で最大 8 GPUを使って Horovod と踊る方法を学ぶのは楽しいことがわかりました。
これは数か月前のことですが、Amazon AI の TensorFlow チームが何を考えているかをこれからご紹介します。彼らは Horovod with TensorFlow を微調整しており、DLAMI の実装ははるかに高速です。さらに重要なことに、ImageNet の ResNet-50 を 15 分以内にトレーニングするために、1 回のトレーニングで 256 GPU 以上を実行することができます。
私が DLAMI で Horovod を初めて実行したのは、p3.16xlarge EC2 インスタンスでした。このインスタンスには 8 つの Tesla V100 GPU が搭載されています。Horovod は、インスタンスの GPU すべてを使用して、1 日以上かかるトレーニングを数時間で完了できるようにすることができます。最新の DLAMI を使用したので、CUDA、TensorFlow や Horovod をインストールして設定する必要はありません。1 つのコマンドで環境を有効にしてから、別の 1 行のコマンドでトレーニングスクリプトを実行できます。
セットアップは簡単でした。トレーニングは比較的高速で、1 GPU から 8 GPU へのわずかなサブリニアスケーリングしか必要ありませんでした。8 時間以内で終わり、正確さは申し分ないものでした。トップ 1 は 75.4% で、トップ 5 は 92.6 %でした。この結果に基づいて、「Tensorflow-Horovod tutorial for the DLAMI」を書きました。
次に、複数の p3 インスタンスでは ResNet-50 をどれほど速くトレーニングできるのかと自問しました。スケーリング効率は決して 100% にならないことを知っており、結局は、より多額の費用を支払うことになるとだろうと思っていました。しかし、チームがモデルをトレーニングするのに 1 日待っていた場合、トレーニングを 15 分以内で行えれば開発者の生産性を高める上で価値があると言えるでしょう。行った実験が示すように、より高速のトレーニングの効率性の低下は最小限に抑えられるため、これは特に当てはまります。
私たちは最近、256 GPU を非常に正確に実行し、完了時間をさらに短縮するベンチマーキングを行いました。それを試してみませんか? ダンスカードに 256 スロットもあるかって? このまま読み続けてください。これを実現する方法について丁寧に説明します。
DLAMI とその TensorFlow-Horovod 環境に関する最新のアップデートでは、どの ImageNet 上でも ResNet-50 をトレーニングすることができ、リリース時に比べて約 20 % コスト削減できました。このブログ記事では、どれほど速く処理してスケーリングできるか、そして Horovod と将来ダンスするためにコストをどう削減するかをご紹介します。 準備はいいですか?
元の TensorFlow-Horovod チュートリアルでは、単一のノードの実装が示されています。1 つのインスタンスをスピンアップし、その GPU をすべて使用します。ここでは、複数のノードをスピンアップし、Horovod 設定とリンクさせて、トレーニングを実行する方法を説明します。いくつかのベンチマークを実行するので、完了までの時間を推測し、新しいノードごとに効率性の損失がどのようなものかを確認することができます。この情報を使用すると、コストを見積もり、トレーニングしたい他のモデルにこのパターンを適用することができます。
パート 1: 複数の DLAMI をスピンアップする
どう行動するかを計画するのは、この時点がうってつけです。簡単な質問を行います。
- ImageNet のコピーを入手する必要がありますか?
- 必要がある場合、
- DLAMI を今すぐスピンアップしてください。データセットをダウンロードして準備するには数時間かかることがあります。待機している間に複数のインスタンスを放置して費用がかさむのは避けたいところでしょう。DLAMI は後でもっと追加することができます。賢いのは、大きな DLAMI CPU インスタンスを使ってダウンロードと準備のステップをより速く実行してから、準備ができ次第それを DLAMI GPU インスタンスに転送してトレーニングするやり方です。また、データセットを分割し、複数のマシン間でデータセットを準備することもできます。
- 必要ない場合は、2 に進みます。
- 必要がある場合、
- Amazon S3、共有ボリューム、またはインスタンス上で既に AWS 環境にダウンロードされた ImageNet データセットはありますか?
- ある場合、
- このブログの後半で、各ノードにデータセットを配布するのに役立つ bash 関数をいくつかご紹介します。
- ない場合、
- 今は 1 つのインスタンスだけをスピンアップしてください。それを準備し、残りの部分をスピンアップし、先ほど説明した関数の 1 つを使用してデータセットを配布します。
- ある場合、
- ImageNet データセットは TensorFlow でトレーニングを行うのに前処理されていますか?
- されている場合、
- このブログのポストで紹介するすべてのことをすばやく行うことができ、わずか 4 つのインスタンスで ImageNet を約 1 時間半以内に完全にトレーニングすることもできます。
- されていない場合、
- ImageNet データセットの準備方法については、DLAMI ドキュメントに記載されている詳細な手順に従ってください。
- されている場合、
次に、1 つ以上の DLAMI をスピンアップしましょう。これを行うにはいくつかの方法がありますが、Amazon EC2 コンソールを使用します。AWS Cloud Formation テンプレートまたは AWS CLI の使用方法をすでに知っている場合は、これらのツールも使用できます。ここでの目標は、それぞれが複数の GPU を持ついくつかの同一の DLAMI を起動することです。この次のステップでは、同じリージョンとセキュリティゾーン (VPC) に 4 つの p3.16xlarge DLAMI をすべて導入します。このステップは重要です。異なるリージョンまたはセキュリティゾーンで起動したランダムインスタンスをリンクするだけでは、パフォーマンスに影響を与えてしまうからです。
EC2 コンソールでは、名前で AMI を検索できます。「deep learning (深層学習)」と検索すると、Deep Learning AMI (Ubuntu) が見つかります。[Select] ボタンをクリックします。
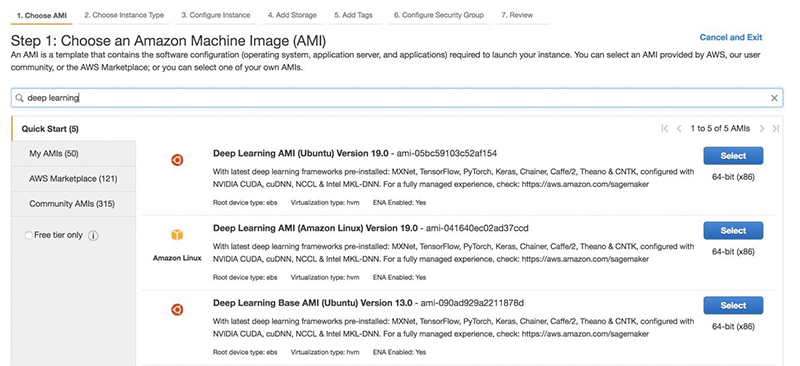
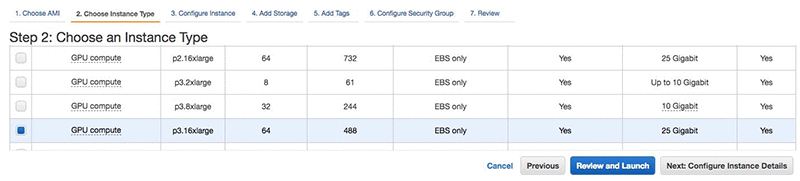
Deep Learning AMI (Ubuntu) を選択すると、インスタンスタイプを選択できます。最速のインスタンスを使用して最速のトレーニングを実現したいので、p3dn.24xl インスタンスタイプを選択します。あなたの地域でこれがまだ利用できない場合は、代わりに p3.16xlarge を選択してください。同じシステム上にある GPU が多いほど、トレーニングはより速くなります。次に [Next: Configure Instance Details] を選択します。複数の同一インスタンスを起動するオプションがあります。256 GPU のトレーニングを達成するために最大 32 のインスタンスを選択します。ただし、この例では、合計 32 GPU の 4 つのインスタンスを使用します。
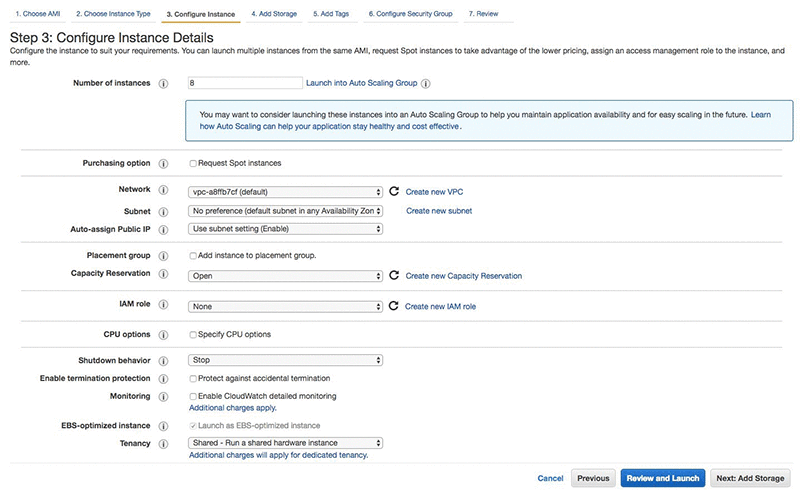
次に、インスタンスの詳細を選択します。 少なくとも 200 GB の高速ストレージを持つインスタンスを選択する必要があります。最高のパフォーマンスを得るため、10,000 IOPS を持つプロビジョンド IOPS SSDを選択しています。

タグ画面をスキップして、セキュリティグループに進むことができます。

セキュリティグループの設定ページでは、新しいグループを作成するか、既存のグループを使用できます。次に、選択内容を確認し、必要に応じて修正を加え、[Review]、[Launch] を選択します。
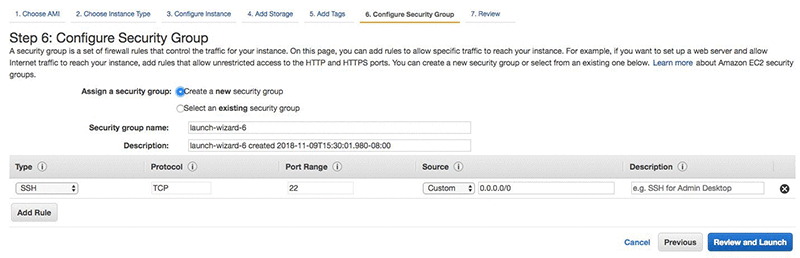
画面は次のスクリーンショットのような感じになるはずです。注意すべき重要な点は、ストレージセクション (サイズ、ボリュームタイプ、IOPS) にあります。 [Launch] を選択します。
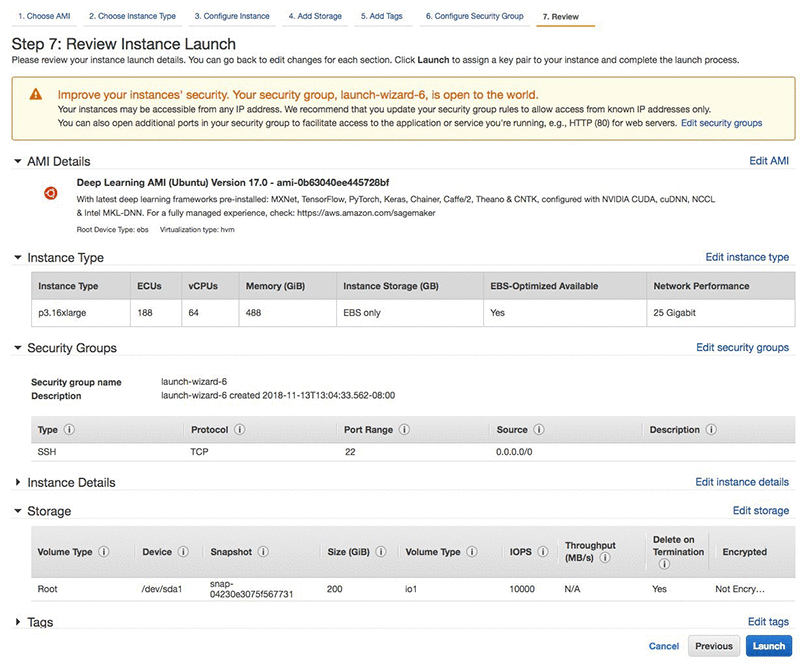
[Launch] を選択したら、キーペアを選択します。既存のキーを使用するか、新しいキーを作成します。後でこの情報が必要になるので、キーを保存した場所とキー名を書き留めておいてください。

緑色のボックスが表示されたら、[View Instances] を選択して、新しく起ち上げた DLAMI のリストを確認します。

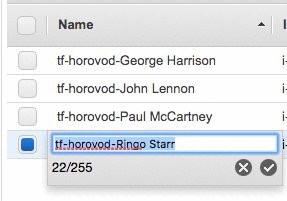
インスタンスを起動するには数分かかるので、名前を付けるのはこのタイミングが良いでしょう。
DLAMI のいずれかを選択します。コンソールで名前を変更して、どれが何だったかを忘れないようにしましょう。ノードが 8 つあるなら、白雪姫と 7 人の小人たち (Doc、Dopey、Bashful、Grumpy、Sneezy、Sleepy、Happy) と呼ぶことができます。私は 4 つしか起ち上げなかったので、John Lennon、Paul McCartney、George Harrison、Ringo Starr と名前を付けました。John Lennon をリーダーに選びました。リーダーをマスターと呼ぶ人もいますが、私は「リーダー」派です。 リーダーとメンバーがあります。
パート 2: データセットを準備する
ステップ 1.DLAMI の新しいクラスタごとに ImageNet のコピーをダウンロードする。
最速のパフォーマンスを得るには、クラスタ内の各インスタンスにデータセットのローカルコピーを持たせるのが良いでしょう。未加工のデータセットは、トレーニングする前に TensorFlow ユーティリティで前処理する必要があります。そうしなければ、トレーニングに時間がかかり、多くのベンチマークで報告されている精度レベルに達しないからです。ImageNet がない場合は、ダウンロードする必要があります。コピーを持っていても、このデータがクラスタのリージョンとセキュリティゾーン内に置く必要があり、前述の前処理が必要になります。そのため、Amazon S3 や他の場所に前処理されたコピーがあれば、それをリーダーにコピーして、パート 3 に進むことができます。
ImageNet をインスタンスの 1 つに今すぐダウンロードするか、すでにどこかに持っていれば今すぐインスタンスにコピーして先読みしてください。こうすることで、何が来るのかを知ることができます。パート 3 では、待機中に合成データセットを使用して分散トレーニングを試すことができます。
ステップ 2.トレーニングのために ImageNet ファイルを準備する。
トレーニングの前に準備の手順を踏む必要があります。これにより、すべての画像が前処理され、一貫性を持たせられ、トレーニングのスピードに合わせて最適化されます。このステップを実行しなければ、同等の速度または精度を達成することはできません。確実に、コスト増につながってしまいます。このステップを一度実行すれば、それ以降のトレーニングを実行するために再度実行する必要はありません。このボリュームを保持し、将来の DLAMI およびテストやベンチマークの実行につなげることをお勧めします。
ImageNet データセットの準備方法については、DLAMI ドキュメントに記載されている詳細な手順に従ってください。
私は ImageNet の前処理されたコピーをすでに置いていたので、セットアップとトレーニングはとても簡単だったと言わざるをえません。前処理を済ませたら、あなたもコピーを保存しておきましょう。インスタンスを終了せずにインスタンスを停止し、後でデータと一緒にインスタンスを元に戻すことができます。 また、前処理されたデータセットを S3 に保存して、後で使用するためにアーカイブすることもできます。
パート 3: 合成データによるトレーニング
ImageNet がダウンロードされるのを待つ間、合成データでセットアップを試すことができます。これにより、メンバーがお互いに対話することができるようになります。TensorFlow with Horovod はこのマルチノードモードで作業しており、最終的に ImageNet データセットのトレーニングに切り替えることができます。
次の手順に進む前に、全体の設定を見直して、各ノードが実行されていること、同じインスタンスタイプであること、同じアベイラビリティーゾーンにあることを確認してください。

コンソールでリーダーを選択し、[Actions] ボタンをクリックして、[Connect] を選択します。次のページに、接続の手順が記載されています。新しいキーを作成した場合は、chmod 400 key.pem でセキュリティ設定を調整する必要があります。これらの指示は Connect プロンプトに表示されます。しかし、ssh との接続方法の重要なバリエーションは、リーダーがメンバーにアクセスできるようにすることです。 これを行うには、キーを追加して ssh ログインをカスタマイズして、Connect プロンプトで示唆されているものと若干異なるようにします。ローカル端末とキーをダウンロードしたディレクトリから次のコマンドを実行します。「key.pem」をキーのファイル名に置き換え、 「PUBLIC_IP_ADDRESS_OF_THE_LEADER」にしてら実行してください。
接続したら、tensorflow_p36 環境をアクティブにします。
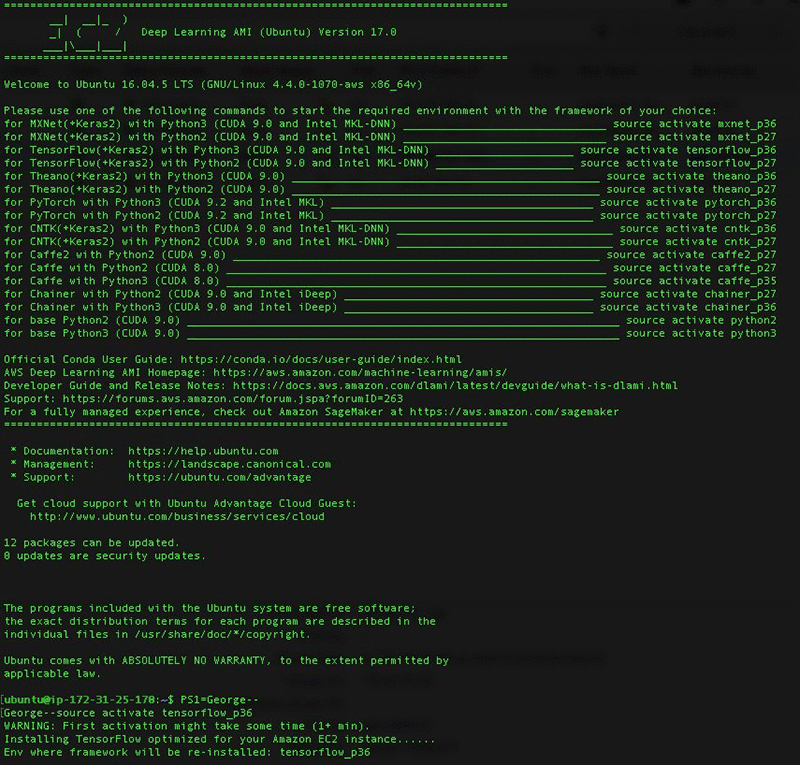
この例では、今、John Lennon を起ち上げています。ログインしたら、TensorFlow 環境を開始します。TensorFlow はインスタンスタイプに合わせて最適化されている可能性が高いため、この最初のアクティブ化にはしばらく時間がかかることがあります。
環境をアクティブにした後、Horovod に残りのバンドメンバーについて知らせなければなりません。これは、各メンバーの情報を hosts ファイルに追加することで実現します。 トレーニングスクリプトが存在する場所にディレクトリを変更します。
リーダーのホームディレクトリにあるファイルを編集するには、vim を使用します。
EC2 コンソールのメンバーの 1 つを選択すると、説明ページが開きます。[Private IP] フィールドを探し、IP アドレスをコピーしてテキストファイルに貼り付けます。各メンバーのプライベート IP アドレスを新しい行にコピーします。次に、各 IP アドレスの横に空白を追加し、テキスト slots = 8 を追加します。これは、各インスタンスが持つ GPU の数を表します。p3.16xlarge インスタンスは 8 GPU あるため、異なるインスタンスタイプを選択した場合は、インスタンスごとに実際の GPU 数を指定します。リーダーに関しては、localhost を使用することができます。そうすると、次のように表示されるでしょう。
ファイルを保存してリーダーの端末に戻ります。
これで、リーダーは各メンバーに伝達する方法がわかります。これはすべてプライベートネットワークインターフェイス上で起こります。次に、短い bash 関数を使用して、各メンバーにコマンドを送信します。 リーダーの端末のセッションでこのコマンドを実行します。
まず、他のメンバーに「StrickHostKeyChecking」を行わないように指示します。これにより、トレーニングがハングする可能性があるためです。
では、合成データでトレーニングを試してみましょう。スクリプト deep-learning-models/models/resnet/tensorflow/dlami_scripts/train_synthetic.shはデフォルトで 8 GPU になりますが、実行する GPU の数を指定することができます。この実行に使用している 4 GPU のパラメータとして 4 を渡してスクリプトを実行します。
いくつかの警告メッセージの後、Horovod が 4 GPU を使用していることを確認する次の出力が表示されます。
そして他の警告の後に、テーブルの開始といくつかのデータポイントが表示されます。1,000 バッチの作業を見たくない場合は、トレーニングを中断します。ここでは、トレーニングが平均約 3000 画像/秒であることが見て取れるので、私は 400 でトレーニングを停止します。
8 GPU を試してみましょう。
スピードが二倍より少し小さかった (3,012 に対して 5,874) ので、今度は 200 で停止しました。
これで、マルチノードトレーニングをテストする準備が整いました。最大の 32 GPU を試してみてください。
出力はこれと似たようなものになるでしょう。Horovod のサイズは 32 と表示され、約 4 倍の速度であることがわかります。この実験が完了したら、リーダーとそのメンバーとの通信能力をテストしたことになります。問題が発生した場合は、Horovod チュートリアルのドキュメントのトラブルシューティングセクションを参照してください。
パート 4: ImageNet で ResNet-50 をトレーニングする
合成データトレーニングのプロセスを見て満足し、ImageNet データセットを準備したら、用意されたデータセットをすべてのメンバーにコピーする準備が整います。
データセットがまだリーダー上にしかない場合は、この copyclust 関数を使用してデータを他のメンバーにコピーします。リーダーの端末のセッションでこのコマンドを実行します。
これで、copyclust を使用してデータセットフォルダをコピーできます。最初のパラメータは hosts ファイルで、2 番目のパラメータはリーダーのデータセットフォルダで、3 番目のパラメータは各メンバーのターゲットディレクトリです。
または、ファイルが Amazon S3 バケットにある場合は、ファイルを各メンバーに直接ダウンロードするために runclust 関数を使用します。
ここで、tmux や screen、あるいはいくつかのツールを使用してセッションを切断したり再開させたりすることについて言いたいことがあります。一度に複数のノードを管理できるツールを使用すると、時間を大幅に節約できます。けれども、このブログの範囲を超えているので、この部分は簡単に触れる程度にとどめます。選択肢は複数あり、各ステップごとに待機して各インスタンスを個別に管理したり、いくつかのパワーツールを使用したりできます。
コピーが完了したら、トレーニングを開始する準備が整います。この実行に使用している 32 GPU のパラメータとして 32 を渡して、スクリプトを実行します。セッションの切断と終了が心配な場合は、tmux などのツールを使用して、トレーニングの実行を中断してください。
次の出力は、ImageNet でトレーニングを 32 GPU で実行するときに表示されます。 32 GPU では 90~110 分かかります。
このランは完了しました! 評価ランでフォローアップします。他のメンバーにジョブを配布する必要がないほど十分すばやく実行されるため、リーダー上で実行します。以下は、評価ランの出力です。
この出力が 256 GPU でどのように見えるのか興味があれば、次の出力ブロックで確認できます。
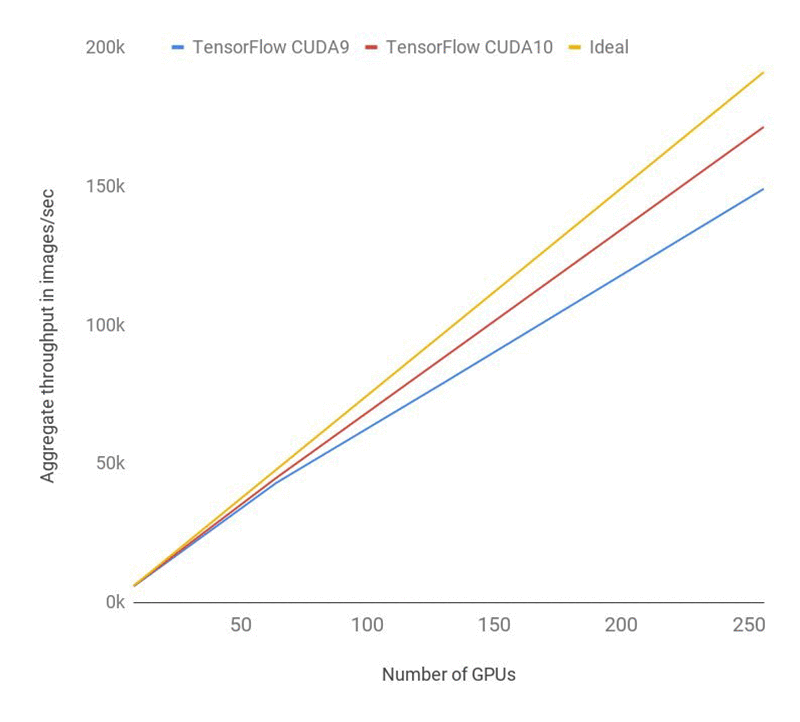
速度 (画像/秒) は 140k 以上であることがわかります。次の図は、256 GPU を使用する CUDA10 の最新のベンチマークを示しており、速度は 171k に達しています。 これにより、効率が 90% に向上します。これは TensorFlow が CUDA 10 用の公式バイナリをリリースした後 DLAMI に付いてくるので、探してみてください。 次の図は、CUDA 10 を使用した ResNet-50 トレーニングのパフォーマンスを示しています。オーバーヘッドは CUDA 9 に比べて削減されています。
結論
4 つのノードを試した今、もっと試してみたいと思いませんでしたか? 16 ノードや 32 ノードはどうでしょう? では 2 ノードはどうでしょう? スケールアップとスケールダウンして、パフォーマンスにどのような影響があるかを確認できます。エポックトレーニングの時間を比較して、完了させるための全体的なコストを見積りましょう。
注: Amazon EC2 コンソールで「more like this」機能を使用する場合は、すべての設定、特にストレージを調整する準備をしてください。「More like this」にはストレージが含まれていないので、少なくともストレージが 200 GB 以上になるように更新してください。
また、DLAMI で最新のインスタンスタイプと最適化された TensorFlow 環境を使用して別のデータセットを試し、トレーニングする速度を確認することもできます。
次回のブログでは、DLAMI のクラスタ上のスケーラブルなトレーニングに改善を加えてみます。
付録
トラブルシューティング
次のコマンドは、Horovod を試してみるときに出てきた過去のエラーを取得するのに役立ちます。
- トレーニングがクラッシュした場合、mpirun は各マシンのすべての Python プロセスをクリーンアップできないことがあります。その場合、次のジョブを開始する前に、次のようにすべてのマシンで Python プロセスを強制終了します。
- runclust hosts “pkill -9 python”
- プロセスがエラーなしで突然終了した場合は、ログフォルダを削除してみてください。
- 説明できないその他の問題が発生した場合は、ディスク容量を確認してください。スペースが足りない場合はチェックポイントとデータが満杯であるため、ログフォルダを削除してみてください。各メンバーのボリュームのサイズを大きくすることもできます。
- 最後の手段として、再起動を試みることもできます。
著者について
 Aaron Markhamは、MXNet と AWS Deep Learning AMI のプログラマーライターです。彼はワイン造りの学位を持ち、新技術に対する情熱を持っており、執筆することと教えることでそれを共有しています。深層学習テクノロジーについて語る以外に、彼はサンタクルーズのホームレスにコンピュータ技術を教えたり、サン・クエンティンでは囚人にウェブプログラミングを教えたりしています。働いたり教えたりしていない時は、山でスノーボードやハイキングを楽しんでいます。
Aaron Markhamは、MXNet と AWS Deep Learning AMI のプログラマーライターです。彼はワイン造りの学位を持ち、新技術に対する情熱を持っており、執筆することと教えることでそれを共有しています。深層学習テクノロジーについて語る以外に、彼はサンタクルーズのホームレスにコンピュータ技術を教えたり、サン・クエンティンでは囚人にウェブプログラミングを教えたりしています。働いたり教えたりしていない時は、山でスノーボードやハイキングを楽しんでいます。