Amazon Web Services ブログ
Amazon SageMaker を使用して、間違いの経済的コストが不均等なモデルをトレーニングする
多くの企業は、機械学習 (ML) に取り組んで、顧客やビジネスに対する成果を向上させています。そのために、「ビッグデータ」に基づいて構築された ML モデルの力を活用して、パターンを特定し、相関関係を見つけ出しています。次に、新しいインスタンスに関するデータに基づいて、適切なアプローチを特定したり、可能性のある結果を予測したりすることができます。ただし、ML モデルは実世界の近似なので、こうした予測の一部が誤っている可能性もあります。
一部のアプリケーションでは、すべてのタイプの予測の間違いの影響が実際には同等です。他のアプリケーションでは、ある種の間違いは、別の間違いよりもはるかに高価または重大になります – ドル、時間、または何か他の単位で絶対的または相対的に測定されます。例えば、医学的推定によって誰かが乳癌に罹っていないと予測して実際には罹っていたとすると (偽陰性の間違い)、逆の間違いよりもはるかに大きなコストまたは結果が生じるでしょう。偽陰性の間違いを十分に減らして補えるなら、より多くの偽陽性の誤りを許容することも可能かもしれません。
このブログ記事では、トレードオフの透明性を高めながら、望ましくない間違いを減らすという目標で、間違いのコストが不均等であるアプリケーションに対処します。異なる種類の誤分類のコストが非常に異なるバイナリ分類問題について、Amazon SageMaker のモデルをトレーニングする方法を紹介します。このトレードオフを調べるために、非対称の誤分類コストを組み込んだカスタム損失関数 (モデルがどの程度うまく予測を行っているかを評価するメトリクス) を書く方法を示します。そして、その損失関数を使って、Amazon SageMaker Build Your Own Model をトレーニングする方法を示します。さらに、モデルによる間違いの評価方法と、異なる相対コストでトレーニングされたモデルを比較する方法を示し、全体として最良の経済的成果を持つモデルを特定できるようにします。
このアプローチの利点は、ML モデルの成果と間違いと意思決定のためのビジネスの枠組みを明示的にリンク付けできることです。このアプローチでは、予測に基づいて対処するべき具体的な行動に基づいて、ビジネスがコストマトリクスを明示的に提示する必要があります。そうすることで、ビジネスはモデル予測の経済的帰結を全体的なプロセス、予測に基づいて対処した行動、それらに関連するコストで評価することができます。この評価プロセスは、モデルの分類結果を単純に評価するだけではありません。このアプローチは、ビジネスにおける挑戦的な議論を促し、オープンな議論と合意のためにさまざまな暗黙の意思決定や評価を明らかにすることができます。
背景とソリューションの概要
モデルのトレーニングは常に間違いを最小限に抑えることを目指していますが、ほとんどのモデルは、すべてのタイプの間違いが等しいと想定してトレーニングされています。しかし、種類が異なる間違いのコストが等しくないことが分かったらどうなるでしょうか? たとえば、UCI の乳癌診断データセットでトレーニングされたサンプルモデルを取り上げましょう。1 明らかに、偽陽性の予測 (乳癌ではないのに、乳癌であると予測する) は、偽陰性の予測 (乳癌であるのに、乳癌でないと予測する) とは非常に異なる結果をもたらすでしょう。最初のケースでは、追加スクリーニングが行われます。2 番目のケースでは、発見される前に癌が進行してしまう可能性があります。こうした結果を定量化するために、しばしば結果を相対コストの観点から議論し、トレードオフが可能になります。偽陰性や偽陽性の予測の正確なコストがどうあるべきかを議論することはできますが、少なくともすべてが同じではないことに全員が同意すると確信しています – ML モデルは一般にすべてが同じであるかのようにトレーニングされますが。
カスタムのコスト関数を使用してモデルを評価し、モデルが行っている間違いの経済的影響を確認することができます (効用解析)。Elkan2 は、モデルの結果にコスト関数を適用することで、標準的なベイジアンおよび意思決定木の学習方法で使用される場合の不均衡なサンプルを補正することができると示しました (例: より少ない債務不履行、大量の債務返済のサンプル)。また、カスタム関数を使用して、この同じ補正を実行することもできます。
モデルでは、カスタムの損失関数を使用して、トレーニング中にさまざまなタイプの間違いのコストをモデルに提供することで、コストの差異を反映した方法でモデルに予測を「シフト」させることもできます。たとえば、前述の乳癌の例では、モデルが行う偽陰性の間違いを少なくしたいと考えており、その目的を達成するために偽陽性をより多く受け入れる意思があります。さらに言うなら、偽陰性を少なくするためには、いくつかの「正しい」予測をあきらめても構わないかもしれません。少なくとも、ここではトレードオフを理解したいと考えます。この例では、医療業界のコストを使用します。3,4
さらに、多くの場合、モデルの予測は「ほぼ」として予測されていることを理解したいと思います。たとえば、バイナリモデルでは、スコアを「True」または「False」として分類するためにカットオフ (例、0.5) を使用します。 実際に、どのくらいのケースがカットオフに非常に近いでしょうか? スコアが 0.499999 だったので、偽陰性はそのように分類されたのでしょうか? こうした詳細は、混同行列または AUC 評価の通常の表現では見られません。こうした質問に取り組むために、特定の閾値に依存することなくこれらの詳細を調べることができる、モデル予測の斬新でグラフィカルな表現を開発しました。
実際に、特定の種類の間違いを回避するようにトレーニングされたモデルが、間違いの差別化に特化し始める可能性が高いケースがあります。街路から見える標識の誤認識がすべて同じであると信じるようにトレーニングされたニューラルネットワークを想像してみてください。 5 それでは、一時停止標識を速度制限 45 mph の標識として誤って認識することは、2 つの制限速度標識を混同するよりもはるかに悪い間違いであるというトレーニングを受けたニューラルネットワークを想像してみましょう。ニューラルネットワークが異なる特徴を認識し始めると予想することは合理的です。これは有望な研究の方向であると確信しています。
Amazon SageMaker を使用してモデルを構築し、ホストします。Amazon SageMaker は、開発者やデータサイエンティストがあらゆる規模の機械学習モデルを短期間で簡単に構築、トレーニング、デプロイできるようにする完全マネージド型プラットフォームです。Amazon SageMaker ノートブックインスタンスでホストされている Jupyter ノートブックでモデルを作成および分析し、「Bring Your Own Model」機能を使用して、オンライン予測用のエンドポイントを構築およびデプロイします。
「コスト関数」および「損失関数」という用語は、しばしば交換可能として使用されますが、この記事ではそれらを区別しており、それぞれの例を以下に示します。
- 「損失関数」は、モデルをトレーニングするために使用します。ここでは、さまざまな種類の間違いに対して異なる重みを指定します。間違いの重みが相対的であることは、ここで最も重要です。
- 「コスト関数」は、モデルの経済的影響を評価するために使用します。コスト関数については、正しい予測のコスト (または値) と間違いのコストを指定することができます。ここでは、ドル単位のコストを使用するのが最も適切です。
この区別により、モデルの振る舞いをさらに精緻化したり、異なる構成要素による影響の違いを反映させることができます。このモデルでは、両方の関数に対して同じコストセット (品質調整済み耐用年数、QALY) を使用しますが、たとえば、損失関数に相対 QALY を使用し、コスト関数には処理するコストを使用することもできます。
この問題を、次の 3 つの部分に分けます。
- 「カスタム損失関数の定義」では、異なる間違いに不均等に重みを付けるカスタム損失関数を構築する方法を示します。予測の間違いの相対的なコストは、実行時にハイパーパラメータとして提供され、モデル上の異なる重み付けの影響を調べて比較することを可能にします。すべての間違いが等しいと想定するようにトレーニングされた「バニラ」モデルを評価するために、カスタムコスト関数を構築しその使用を実証します。
- 「モデルのトレーニング」では、カスタム損失機能を使用してモデルをトレーニングする方法を示します。UCI の乳癌診断データセットを使用するサンプルノートブックをエミュレートし、拡張します。
- 「結果の分析」では、モデルを比較して予測値の分布を閾値と比較してより良く理解する方法を示します。特定の種類の間違いを避けるようにモデルをトレーニングすることで、モデルが肯定的予測と否定的予測をより効果的に区別するように、分布に影響を与えることを確認します。
私たちは独自のモデルを構築しており、Amazon SageMaker の組み込みアルゴリズムを使用していません。つまり、Amazon Elastic Container Registry (Amazon ECR) で使用可能なコンテナのイメージによって Docker コンテナにパッケージ化されている限り、Amazon SageMaker のカスタムモデルをトレーニングする機能を利用できることを意味しています。Amazon SageMaker でカスタムモデルをトレーニングする方法の詳細については、この記事またはさまざまな利用可能なサンプルノートブックを参照してください。
設定
この例を自分の AWS アカウントで実行するために必要な環境を設定するには、まず以前に公開されたブログ記事にあるステップ 0 および 1 に従って、Amazon SageMaker インスタンスを設定、AmazonEC2ContainerRegistryFullAccess ポリシーを SageMakerExecutionRole に追加します。次に、ステップ 2 にあるように、ターミナルを開いて GitHub リポジトリ (https://github.com/aws-samples/amazon-sagemaker-custom-loss-function) を Amazon SageMaker ノートブックインスタンスに複製します。
このリポジトリには、このブログ記事で実行するアルゴリズムの Docker イメージを構築して使用するのに必要なすべてのコンポーネントを持つ 「container」という名前のディレクトリが含まれています。この Amazon SageMaker サンプルノートブックに、個々のコンポーネントの詳細が記載されています。ここでの目的のために、最も関連性が高く、ワークロードを実行するためのすべての情報を含む 2 つのファイルがあります。
- このファイルは、Docker コンテナイメージを構築する方法について説明しています。ここで、コードの依存関係 (Python などの使用する言語等)、コードに必要なパッケージ (TensorFlow など) 、その他を定義することができます。詳細は、こちらをご覧ください。
- custom_loss/train。このファイルは、Amazon SageMaker がトレーニングのためにコンテナを実行するときに実行されます。バイナリ分類子モデル、モデルをトレーニングするために使用するカスタム損失関数、Keras トレーニングジョブを定義する Python コードが含まれています。このコードについては後で詳しく説明します。
その後、ノートブックはライブラリのインポート、ヘルパー機能の作成、乳癌データセットのインポート、その標準化などを行い、トレーニングとテストのセットを Amazon SageMaker トレーニングで後で使用するために Amazon S3 にエクスポートします。
カスタム損失関数の定義
ここで、偽陰性の間違いとは異なる重みを偽陽性の間違いに付与する損失関数を構築します。これを行うために、Keras でバイナリ分類子を構築して、ユーザ定義の損失機能に対応する Keras の機能を使用します。
Keras で損失関数を構築するために、モデルの予測と基本となる真理を引数とし、スカラー値を返す Python 関数を定義します。このカスタム関数では、偽陰性の間違い (fn_cost) と偽陽性の間違い (fp_cost) に関連するコストを入力します。内部的には、損失関数は Keras バックエンド関数を使用して計算を実行する必要があることに注意してください。
以下の関数は、単一の予測の損失を、予測の基本となる真理のクラスと、そのクラスからの観測値の誤分類に関連するコストで重み付けされた予測値との差として定義しています。総損失は、これらの損失のすべての加重されていない平均です。これは比較的シンプルな損失関数ですが、この基盤を基にして、より複雑で状況特有のメリットとコストの構造を構築し、モデルをトレーニングするために使用することができます。
モデルのトレーニング
ここでは Amazon SageMaker を使用してカスタムモデルをトレーニングしているため、モデルの構築とトレーニングに関するすべてのコードは、Amazon ECR に保存されている Docker コンテナイメージにあります。ここに示すコードは、Docker コンテナイメージに含まれているコードの例です。
実際のモデルコード (および前述のコピーをミラーリングするカスタム損失関数)、ならびに Docker コンテナイメージを作成して Amazon ECR にプッシュするために必要なすべてのファイルは、このブログポストに関連付けられたリポジトリにあります。
3 つのモデルを構築して訓練するので、Keras の組み込み損失関数とカスタム損失関数を使用してさまざまなモデルの予測を比較することができます。腫瘍が悪性である確率を予測するバイナリ分類子モデルを使用します。
3 つのモデルは次のとおりです。
- Keras の組み込みバイナリクロスエントロピー損失を使用して、偽陰性と偽陽性の間違いの重みが等しいバイナリ分類子モデル。
- 偽陰性の間違いに偽陽性の間違いの 5 倍の重み付けをして、前に定義したカスタム損失関数を使用するバイナリ分類子モデル。
- 偽陰性の間違いに偽陽性の間違いの 200 倍の重み付けをして、前に定義したカスタム損失関数を使用するバイナリ分類子モデル。
最後のモデルの損失関数で使用したコストは、医学文献に基づいています。3、4 スクリーニングのコストは、QALY で測定されます。QALY が 1 であるとは、完全に健康な 1 年間の生活 (1 年間 × 1.0 の健康) と定義されています。たとえば、ある個人が半分の健康状態、すなわち完全な健康状態の 0.5 である場合、その個人の 1 年間の生活は 0.5 QALY (1 年間 × 0.5 の健康) に等しくなります。その個人の 2 年間の生活は、1 QALY (2 年間 × 0.5 の健康) に相当します。
| 結果 | QALY |
| 真陰性 | 0 |
| 偽陽性 | -0.01288 |
| 真陽性 | -0.3528 |
| 偽陰性 | -2.52 |
ここで、真陰性の結果は、コストのベースラインとして評価されます。つまり、表の他のすべてのコストは、乳癌ではなくテストが陰性である患者との相対で測定されます。乳癌でありテストが陰性である女性はベースラインに対して QALY を 2.52 失い、乳癌ではなくテストが陽性である女性はベースラインに対して QALY を 0.0128767 (または約 4.7 日) を失うことになります。QALY の推定経済価値は、100,000 USD です。したがって、これらの値は QALY でのコストに 100,000 USD を掛けてドル単位のコストに換算することもできます。これらの値から、偽陰性の間違いは偽陽性の間違いより約 200 倍高価であることになります。こうしたコストの詳細については、冒頭の医学文献を参照してください。
中間のモデルでの 5 という値は、デモンストレーションの目的で選択したものです。
これらのコストを手に入れると、モデルを推定することができます。Keras のモデルのパラメータを推定することは、次の 3 つのステップからなるプロセスです。
- モデルを定義する。
- モデルをコンパイルする。
- モデルをトレーニングする。
モデルのアーキテクチャの定義
まず、モデルの構造を定義します。この場合、モデルは単一レイヤー内の単一ノードで構成されます。つまり、以下のそれぞれのモデルごとに、フィーチャの線形結合を取り、その線形結合を 0 から 1 の間の値を出力するシグモイド関数に渡す、単一ユニットの単一の高密度レイヤーを追加します。コードの実際に実行可能なバージョンは Docker コンテナにありますが、説明の目的でここに示します。後のステップで相対的な重みを提示します。
モデルのコンパイル
次に、モデルをコンパイルしましょう。モデルをコンパイルすることは、学習プロセスを構成することを意味します。モデルをトレーニングするために使用する最適化アルゴリズムと損失関数を指定する必要があります。
これは、カスタム損失関数と相対的な重みをモデルのトレーニングプロセスに組み込むステップです。
モデルのトレーニング
これで、モデルをトレーニングする準備ができました。これを行うには、fit メソッドを呼び出し、トレーニングデータ、エポック数、バッチサイズを指定します。組み込みまたはカスタムのどちらの損失関数を使用する場合でも、このステップのコードは同じです。
Docker イメージの構築
次に、カスタム損失関数とモデルコードを含む Docker イメージを構築し、イメージを Amazon Elastic Container Registry (ECR) にプッシュするシェルスクリプト (build_and_push.sh) を実行します。このノートブックの先頭で定義されている 「image_name」は、このイメージを含む ECR のリポジトリに割り当てられる名前です。
前述のとおり、Docker コンテナのモデル定義とトレーニングコードをパッケージ化し、Amazon SageMaker の bring-your-own-model トレーニング機能を使用してモデルのパラメータを推定し、バイナリ分類子の実際のトレーニングを実行します。
次のコードブロックは、分類子の 3 つのバージョンをトレーニングします。
- 1 つは、Keras の組み込み
binary_cross-entropy損失関数をもつもの。 - 1 つは、偽陰性を偽陽性の 5 倍に加重するカスタム損失関数をもつもの。
- 1 つは、偽陰性を偽陽性の 200 倍に加重するカスタム損失関数をもつもの。
まず、組み込み損失関数、つまり Keras のバイナリクロスエントロピー損失関数の Amazon SageMaker トレーニングジョブを作成して実行します。loss_function_type セットを builtin に渡すと、Amazon SageMaker は、Keras のバイナリクロスエントロピー損失関数を使用することを認識します。次に、カスタムの 5:1 損失関数、つまり偽陰性が偽陽性より 5 倍高価であるカスタム損失の Amazon SageMaker トレーニングジョブを作成して実行します。loss_function_type をカスタムに、fn_cost を 5 に、fp_cost を 1 に、それぞれ設定すると、Amazon SageMaker は、指定された誤分類コストでカスタム損失関数を使用することを認識します。
最後に、fn_cost を 200 に、fp_cost を 1 に設定して、医療モデルを同じ方法で作成、実行します。
モデルをトレーニングした後、Amazon SageMaker はトレーニングしたモデルの成果物を、トレーニングジョブの output_path パラメータで指定される Amazon S3 バケットにアップロードします。S3 からモデル成果物を読み込み、3 つのモデルの変形すべてで予測を行い、結果を比較します。
結果の分析
一般に成果が高いモデルで求めている特徴は何でしょうか?
- 少数の偽陰性、すなわち良性と分類される少数の悪性腫瘍が存在するはずです。
- 予測は、基本となる真理値の近くで密接に集中するはずです。つまり、予測は 0 から 1 の周りに密接に集中するはずです。
使用するデータセットが小さい (569 インスタンス) このノートブックを再実行すると、テストセットがさらに小さく (143 インスタンス) なることを忘れないでください。このため、モデルの予測の正確な分布と予測の間違いは、サンプリング誤差のために実行ごとに異なる場合があります。それにもかかわらず、モデルの実行によって次の一般的な結果が得られます。
精度と ROC 曲線
まず、モデルの従来の評価を示します。
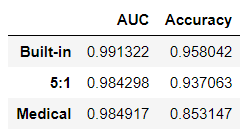
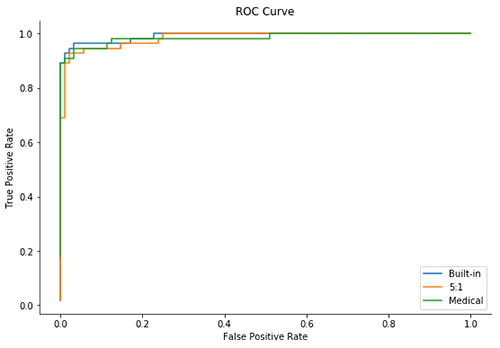
これらの従来の評価によって、2 つのカスタム損失関数モデルは組み込み損失関数 (小さなマージン) とは同様に機能しません。
ただし、精度は、これらのモデルの品質を判断する上でそれほど重要ではありません。実際に、「最良」のモデルで精度が最も低くなる可能性があります。なぜなら、偽陰性の数を十分に減らせる限り、偽陽性の数を増やすことができるからです。
これらの 3 つのモデルの ROC 曲線および AUC スコアを見ると、すべてのモデルがこれらの測定値に従って非常に類似しているように見えます。ただし、これらのメトリクスはどちらも予測されたスコアが [0, 1] の間隔でどのように分布するかを示していないため、これらの予測がどこに集中しているかを判断することはできません。
分類レポート
これら 3 つのモデルを移動するにつれて、偽陰性のコストが増加していることに留意してください。これは、それぞれの連続モデルにおいて偽陰性の数が減少する可能性があることを意味しています。
これは、こうした分類レポートの値について何を示唆しているでしょうか? それは、陰性のクラス (良性) がより高い精度を有するべきであり、陽性のクラス (悪性) がより高いリコールを有するべきであることを意味します。(予測 = tp / (tp + fp)、リコール = tp / (tp + fn) であることを覚えておいてください。)
私たちの分類の問題では、腫瘍を良性または悪性であると分類していることを覚えておいてください。前に引用した医学文献で報告されたコストによると、偽陰性は偽陽性よりもはるかに高価です。そのため、すべての悪性腫瘍をそのように分類し、偽陽性の予測が増えることには悩まないことにします (ある点まで)。したがって、陰性のクラス (良性) については精度が高いことがより重要であり、陽性のクラス (悪性) についてはリコールが高いことをより重視します。
組み込み損失関数
| 精度 | リコール | f1-スコア | サポート | |
| 0 | 0.95 | 0.99 | 0.97 | 88 |
| 1 | 0.98 | 0.91 | 0.94 | 55 |
| 平均/合計 | 0.96 | 0.96 | 0.96 | 143 |
5:1 カスタム損失関数
| 精度 | リコール | f1-スコア | サポート | |
| 0 | 0.96 | 0.93 | 0.95 | 88 |
| 1 | 0.90 | 0.95 | 0.92 | 55 |
| 平均/合計 | 0.94 | 0.94 | 0.94 | 143 |
医療カスタム損失関数
| 精度 | リコール | f1-スコア | サポート | |
| 0 | 0.99 | 0.77 | 0.87 | 88 |
| 1 | 0.73 | 0.98 | 0.84 | 55 |
| 平均/合計 | 0.89 | 0.85 | 0.86 | 143 |
これらの分類レポートは、私たちが目標を達成したことを示しています。つまり、医療モデルが良性で最高の精度を持ち、悪性でリコールが最高となっているからです。
これが意味することは、医療モデルを使用する場合、悪性腫瘍を良性と誤って分類する可能性が最も低く、すべての悪性腫瘍を悪性腫瘍として識別する可能性が最も高いということです。
これらのレポートの詳細を見ると、F1 スコアが最も低く、平均の精度とリコールが最も低いにもかかわらず、医療モデルがこれらの 3 つのモデルで「ベスト」であることがわかります。
混同行列
間違いをよりよく理解するために、より良いツールは混同行列です。
私たちの目標は偽陰性の数を減らすことであるため、偽陽性の増加が過度でない限り、偽陰性が最も少ないモデルが「最良」です。
これら 3 つの混同行列を移動すると、偽陽性と比較した偽陰性のコストが増加しています。そのようなものとして、偽陰性の数が減少し、偽陽性の数が増加することを期待します。しかし、従来とは異なるように加重するようにモデルをトレーニングしているので、真陽性と真陰性の数もシフトするかもしれません。
組み込み損失関数
|
予想される陰性 |
予想される陽性 |
|
| 実際の陰性 |
85 |
3 |
| 実際の陽性 |
4 |
51 |
5:1 カスタム損失関数
|
予想される陰性 |
予想される陽性 |
|
| 実際の陰性 |
83 |
5 |
| 実際の陽性 |
3 |
52 |
医療カスタム損失関数
|
予想される陰性 |
予想される陽性 |
|
| 実際の陰性 |
66 |
22 |
| 実際の陽性 |
1 |
54 |
この結果から、モデルをトレーニングする際に提供される損失関数の値を修正することで、間違いのカテゴリ間のバランスをシフトできることがわかります。相対コストに異なる重み付けを使用すると、間違いに対して重大な影響があり、他の予測も同様に移動します。将来の研究にとって興味深い方向は、こうした予測の違いをサポートするためにモデルによって識別される変化する特徴を探索することです。
これにより、さまざまな間違いの相対的な重みについて行った決定の道徳的、倫理的、経済的な影響に基づいて、モデルに影響を与える強力な手段が得られます。
カスタムの混同行列
特定の観察結果は、そのスコアを閾値と比較することによって、陽性または陰性と分類されます。直観的に、選択された閾値からスコアが離れているほど、予測が正しいという仮定の確率が高くなります (閾値をうまく選択したと仮定して)。
モデルの予測とクラスを分割するために使用される閾値を比較すると、値が閾値に非常に近いことが考えられます。極端な場合、「真」または「偽」の間の値の差は、入力センサーまたは測定の2つの異なる読み取り間の誤差よりも小さくなり得ます。 あるいは、浮動小数点ライブラリの丸め誤差よりも小さい場合さえあります。最悪の場合、観測のスコアの大部分が、閾値に非常に近いところに集中する可能性があります。こうした「密接な混同」は、混同行列、または前の F1 スコアまたは ROC 曲線には表示されません。
直感的には、スコアの大部分を閾値からさらに遠ざけること、または逆にスコアの分布のギャップに基づいて閾値を識別することが望ましいです。(たとえば、地図製作では、同じ問題に対処するために Jenks の自然分類が頻繁に使用されます。) 以下のグラフは、スコアと閾値との関係を調べるツールです。
以下の分布図の各セットは、混同行列の各サンプルの実際のスコアを示しています。各セットにおいて、一番上のヒストグラムは、全ての実際の陰性、すなわち良性腫瘍の予測スコアの分布をプロットしています (混同行列の最上列)。一番下のヒストグラムは、実際の陽性の予測スコアをプロットしています (最下行)。
それぞれのプロットで正しく分類された観測値は青色で表示され、誤って分類された観測値はオレンジ色で表示されています。このノートブックの他の関数で使用される 0.5 の閾値は、プロットに色を付けるために使用されます。ただし、この閾値の選択は、実際のスコアまたはプロットの形状やレベルには影響を与えず、着色にのみ影響を与えます。別の閾値を選択することもでき、このセクションの結果は保留されます。
下の図で、「良い」分布とは予測の大部分が 0 から 1 の点の周りでグループ化されている分布です。より具体的には、ヒストグラムの「良好な」セットは、偽陰性がほとんどなく、実際の陽性が 1 の周りに概ね集中していて、オレンジ色のポイントがほとんどないものです。実際の陰性が 0 の周りに集中していることを確認したいと思いますが、このユースケースでは、実際の陽性の予測が 1 の周りに集中していて、偽陰性の数が少ない限り、擬陽性のサポートで予測の広がりを受け入れる意思があります。
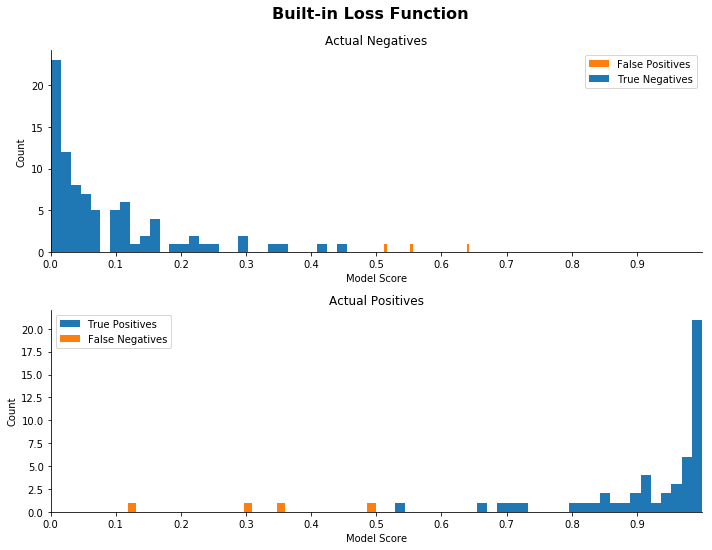
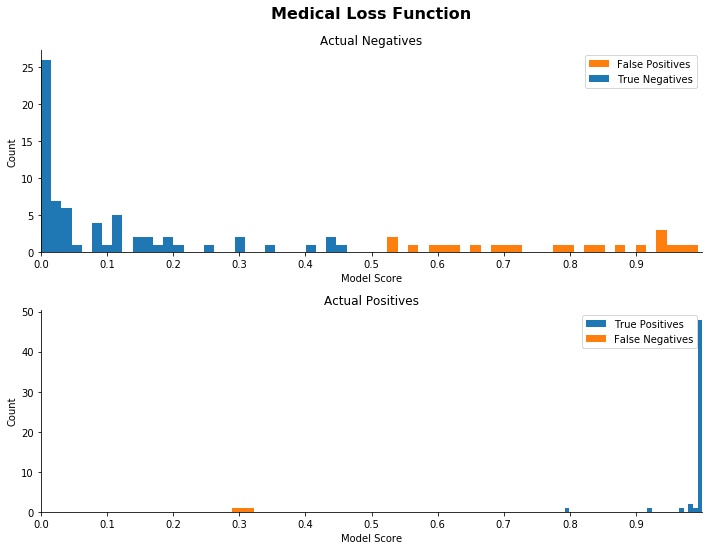
これらのプロットから、比率を増やすと分布がシフトすることがわかります。間違いのタイプの間での比率が増加するにつれて、モデルは多くのサンプルを極端へとプッシュし、本質的にはるかに識別的になります。
また、実際の陽性の中には、カットオフに近いスコアがほとんどないことも分かります。このモデルは、陽性の分類における「確実性」の向上を実証しています。
期待値
ここで、3 つの分類モデルのそれぞれの期待値 (経済価値) を計算します。期待値は、個々の患者が特定の診断テストを受けた場合に罹患すると予想される確率加重損失を米ドルで表したものです。期待値が最も高い診断テストは、このメトリクスの下で「ベスト」とみなされます。期待値は、米ドルで表示されます。
以下のセルで定義されているテスト結果に関連する QALY とドルでの価値の説明については、このブログ記事の前の方にあるスクリーニングのコストの説明を参照してください。
このセクションでは、4 つの可能なテスト結果のすべての価値が反映されています—真陰性および偽陰性、そして真陽性および偽陽性です。
| 期待値 | |
| 組み込み | -$19,658.34 |
| 5:1 | -$18,160.83 |
| 医療 | -$15,282.86 |
医学文献で報告されたコストに基づくカスタム損失関数でトレーニングされたバイナリ分類子は、3 つのうち最もコストがかからないりません。
モデルをトレーニングするために QALY 値を使用し、経済的コストを評価するためにも使用しましたが、同じ値を使用する必要はないことに注意してください。これは、モデルに影響を及ぼすこと、理解すること、評価することで 2 番目に強力な手段となります。
これで、カスタム損失関数を使って分類子をトレーニングし、その結果を検証する方法を実演したので、FN と FP のさまざまな相対値をさまざまなコストで試してみて、影響を調べましょう。
まとめ
このブログ記事の例で、カスタム損失関数を使用して FN 間違いと FP 間違いのバランスを変更する方法を示しました。それぞれの予測セットに適用される異なる種類の治療計画のコストとは別に、そのバランスに影響を与えることができることを示しました。
この作業を拡張するにはいくつかの方法があります。有望な手段としては、以下があります。
- 相対損失と経済的コストをハイパーパラメータとして使用し、ハイパーパラメータ空間を探索して最適なトレードオフを見つける。
- 観測内の特定のフィーチャに応じてコストを変えるなど、別の、または複雑なコスト関数を検討する。
- 異なる相対コストでモデルがどのように変化するか、その変化に最も関連する特徴をさらに調査し、理解する。
ここで、バイナリ分類子の問題に適用したアプローチを示しましたが、マルチクラスの分類子の問題に一般化可能です。さまざまな種類の間違いや誤分類のコストを正確に (または適切に) 反映する入力コストマトリクスを設計することは、より困難です。例えば、一時停止標識を 45 mph の速度制限標識として識別することは、おそらく、逆のコストまたは結果と同じではないでしょう。ただし、この理解でトレーニングされたモデルは、精度、リコール、F1 スコア、AUC を単純に最大化するようにトレーニングされたモデルよりも全体的な経済的価値が高くなる可能性があります。
このブログ記事では、さまざまな種類の間違いの真の影響を表現するためにカスタム損失関数を使用する効果を示しました。カスタム損失関数により、モデルが行った間違いの種類の相対的なバランスを選択し、そのバランスを変えることによる経済的影響を評価することができます。得られたスコアの分布を視覚化することで、モデルの識別能力を評価することができます。また、さまざまな予測とその間違いに対する異なるアプローチのコストとトレードオフを評価することもできます。この組み合わせにより、機械学習をビジネスの結果にリンクさせる強力な新しいツールが提供され、行われるトレードオフの透明性が向上します。
参考文献
- Dua, D. and Karra Taniskidou, E.(2017).UCI Machine Learning Repository [http://archive.ics.uci.edu/ml].Irvine, CA: University of California, School of Information and Computer Science.
- Elkan, Charles.“The Foundations of Cost-Sensitive Learning.” In International Joint Conference on Artificial Intelligence, 17:973–978.Lawrence Erlbaum Associates Ltd, 2001.
- Wu, Yirong, Craig K. Abbey, Xianqiao Chen, Jie Liu, David C. Page, Oguzhan Alagoz, Peggy Peissig, Adedayo A. Onitilo, and Elizabeth S. Burnside.“Developing a Utility Decision Framework to Evaluate Predictive Models in Breast Cancer Risk Estimation.” Journal of Medical Imaging 2, no. 4 (October 2015). https://doi.org/10.1117/1.JMI.2.4.041005.
- Abbey, Craig K., Yirong Wu, Elizabeth S. Burnside, Adam Wunderlich, Frank W. Samuelson, and John M. Boone.“A Utility/Cost Analysis of Breast Cancer Risk Prediction Algorithms.” Proceedings of SPIE–the International Society for Optical Engineering 9787 (February 27, 2016).
- Eykholt, Kevin, Ivan Evtimov, Earlence Fernandes, Bo Li, Amir Rahmati, Chaowei Xiao, Atul Prakash, Tadayoshi Kohno, and Dawn Song.“Robust Physical-World Attacks on Deep Learning Models.” ArXiv:1707.08945 [Cs], July 27, 2017. http://arxiv.org/abs/1707.08945.
著者について
 Veronika Megler (PhD) は、AWS プロフェッショナルサービスのシニアコンサルタントです。彼女は、革新的なビッグデータ、AI および ML のテクノロジーを適用して、顧客が新しい問題を解決し、古い問題をより効率的かつ効果的に解決することを助けています。
Veronika Megler (PhD) は、AWS プロフェッショナルサービスのシニアコンサルタントです。彼女は、革新的なビッグデータ、AI および ML のテクノロジーを適用して、顧客が新しい問題を解決し、古い問題をより効率的かつ効果的に解決することを助けています。
 Scott Gregoireは、AWS プロフェッショナルサービスのデータサイエンティストです。彼は、テキサス大学オースティン校で経済学博士号を取得し、国際金融から小売までの分野のクライアントにアドバイスをしてきました。現在、彼は顧客と協力して、AWS で革新的な機械学習ソリューションを開発しています。
Scott Gregoireは、AWS プロフェッショナルサービスのデータサイエンティストです。彼は、テキサス大学オースティン校で経済学博士号を取得し、国際金融から小売までの分野のクライアントにアドバイスをしてきました。現在、彼は顧客と協力して、AWS で革新的な機械学習ソリューションを開発しています。