データベースの移行は複雑なタスクになりかねません。移行には、ソフトウェアプラットフォームの変更、ソースデータの複雑性の把握、データ損失チェック、既存機能の詳細なテスト、アプリケーションパフォーマンスの比較、およびデータの検証といったあらゆる課題が伴います。
AWS では、移行前チェックリストと移行評価を提供するツールとサービスをいくつかご用意しています。AWS Schema Conversion Tool (AWS SCT) は、既存のデータベーススキーマをひとつのデータベースエンジンから別のデータベースエンジンに変換するために使用できます。AWS Database Migration Service (AWS DMS) は、リレーショナルデータベース、データウェアハウス、NoSQL データベース、およびその他のタイプのデータストアの移行を容易にしてくれます。AWS DMS は、AWS クラウドへのデータの移行、またはオンプレミスインスタンス間 (AWS クラウドセットアップ経由)、クラウドとオンプレミスセットアップとの組み合わせの間でのデータの移行に使用できます。
さらに、AWS はデータベース移行の全体を通じてユーザーをガイドする幅広いドキュメントも提供しています。詳細については、「Oracle データベースの PostgreSQL への移行」を参照してください。
AWS SCT は、スキーマオブジェクトを変換するために役立ち、AWS SCT が PostgreSQL に変換した Oracle コードの割合と、手動で変換する必要があるコードの量を示すレポートを構築します。データベースオブジェクトの移行中は常に、ターゲットデータベースでオブジェクトが欠落している、新しいオブジェクトを作成する、またはソースオブジェクト全体を意図的に無視する可能性のリスクがあります。検証は、移行対象のすべてが正常に移行されたことを顧客に証明するプロセスです。
この記事は、データベースオブジェクトの移行とコードの変換の完了後に、ソース Oracle データベースと PostgreSQL ターゲット間でオブジェクトを検証する方法の概要を説明します。
オブジェクトの検証
問題になるのは、何を検証するかということです。 これを理解するためには、Oracle データベースオブジェクトの異なるタイプと、それらに相当する PostgreSQL データベースオブジェクトのタイプを知っておく必要があります。
以下の表は、Oracle (ソース) データベースのオブジェクトと、対応する PostgreSQL (ターゲット) のオブジェクトのタイプを示しています。DB 変換が正常に行われたことを確認するには、これらのオブジェクトを詳細に検証しなければなりません。
| Oracle オブジェクト |
PostgreSQL に以下として移行 |
| TABLE |
TABLE |
| VIEW |
VIEW |
| MATERIALIZED VIEW |
MATERIALIZED VIEW |
| SEQUENCE |
SEQUENCE |
| SYNONYM |
PostgreSQL では使用されません。PostgreSQL では無視されますが、View を通じて部分的に変換できます。SET search_path はシノニムの回避策にすることもできます。 |
| TYPE |
DOMAIN/ TYPE |
| FUNCTION |
FUNCTION |
| PROCEDURE |
PostgreSQL では使用されません。PostgreSQL 関数を通じて変換できます。 |
| PACKAGE |
PostgreSQL では使用されません。関数をグループ別に分類する PostgreSQL スキーマを通じて変換できます。 |
| TRIGGER |
TRIGGER |
スキーマ検証の実行方法
データベース移行には数多くのタスク、ツール、およびプロセスが関与します。実行したい Oracle データベース移行の規模とタイプが、使用すべきツールを大きく左右します。例えば、Oracle データベースから AWS 上の異なるデータベースエンジンへの異種間移行の実行には、AWS DMS の使用が最も適しています。Oracle データベースから AWS 上の Oracle データベースへの同種間移行の実現には、ネイティブの Oracle ツールの使用が最も適しています。
以下のタスクリストは、移行プロセス中のどのタイミングでスキーマ検証を行うべきかを示しています。
- タスク 1: Oracle ソースデータベースを設定する
- タスク 2: PostgreSQL ターゲットデータベースを設定する
- タスク 3: AWS SCT を使用して Oracle スキーマオブジェクトを PostgreSQL に変換する
- タスク 4: AWS SCT が変換できなかった Oracle スキーマオブジェクトを手動で変換する
- タスク 5: AWS DMS を使用して Oracle から PostgreSQL にデータを移行する
- タスク 6: スキーマオブジェクト検証を実行する
スキーマ変換を検証するには、クエリエディタを使用して Oracle データベースと PostgreSQL データベースにあるオブジェクトを比較します。
標準的な検証方法では、ソースデータベース内のオブジェクト数とターゲットデータベース内のオブジェクト数を比較します。数の検証はどのスキーマオブジェクトでも実行できますが、数の検証だけではエンドユーザーを満足させることができるとは限りません。ユーザーは、オブジェクト定義レベルの検証を求めていることが多々あります。データベースからデータ定義言語 (DDL) を取得するカスタムクエリを作成して、それらを比較する必要があるのはこのためです。
スキーマオブジェクト検証クエリ
Oracle は、LONG データ型を使用して大きな文字セット (上限 2 GB の最大サイズ) を保存します。Oracle の LONG データ型は、多くの Oracle メタデータテーブルまたはビューに表示されます。このトピックの後半で説明する検証クエリで使用されたいくつかの Oracle メタデータテーブルには、LONG データ型が含まれています。他のデータ型とは異なり、Oracle データベースの LONG データ型は同じように動作せず、いくつかの制限の対象となります。
LONG 型に対する制限には以下が含まれます。
LONG 列は WHERE 句に使用できない。- 正規表現で
LONG データを指定できない。
- ストアド関数は
LONG 値を返すことができない。
LONG データ型を使用して PL/SQL プログラムユニットの変数または引数を宣言することはできるが、その後 SQL からプログラムユニットを呼び出すことはできない。
このトピックで説明する Oracle 検証クエリは、Oracle LONG データ型を異なる方法で処理するために DBMS_XMLGEN パッケージを使用し、いくつかの制限を回避するために役立ちます。DBMS_XMLGEN パッケージは、入力として任意の SQL クエリを使用し、レコードセット全体を XML 形式に変換して、CLOB データ型として結果を返すため、データの処理と操作が簡単になります。
ステップ 1: Oracle パッケージの検証
PostgreSQL スキーマでは、Oracle でパッケージが関数をグループ化するのと同じ方法で、関連するすべての関数を保存することができます。Oracle パッケージを PostgreSQL スキーマとして移行することは、不必要なアプリケーション変更の回避に役立ちます。Oracle データベース関数にアクセスするアプリケーションが、同じ方法で PostgreSQL の個々の関数にアクセスできるからです。例えば、次のようになります。
- 移行前のソース Oracle データベース: アプリケーションが PackageName.FunctionName としての Oracle パッケージ関数にアクセスします。
- 移行後のターゲット PostgreSQL データベース: アプリケーションは SchemaName.FunctionName としての PostgreSQL 関数にアクセスできます。
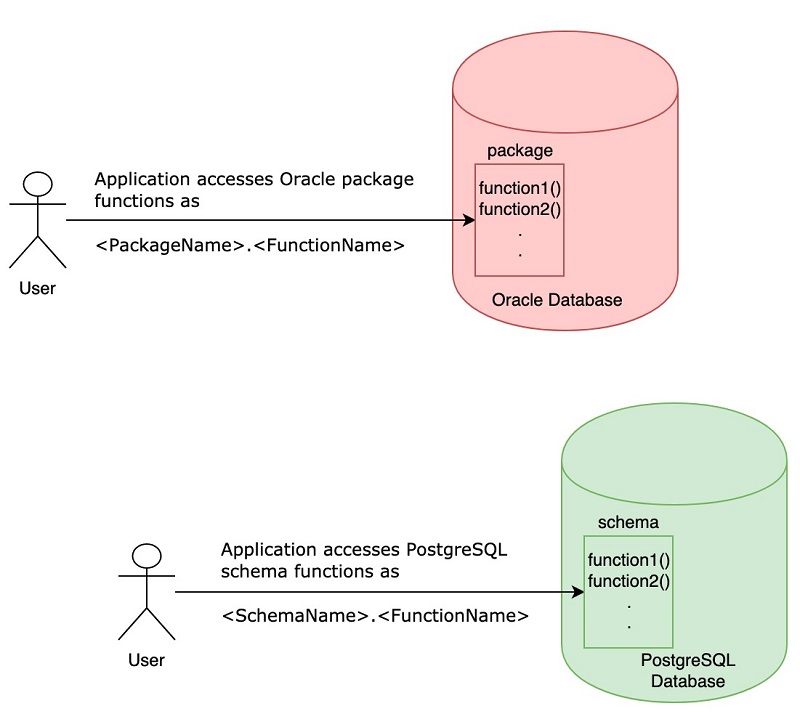
10 個のパッケージとその他のオブジェクトが含まれる Oracle に 1 人のユーザーがいると仮定します。10 個すべてのパッケージが PostgreSQL スキーマとして移行され、Oracle ユーザー自身はその他すべてのオブジェクトを保存する PostgreSQL 内の別のスキーマになります。このため、移行後の PostgreSQL には、11 個 (10 個のパッケージ = 10 スキーマ、1 人のユーザー = 1 スキーマ) のスキーマがあることになります。
すべての Oracle パッケージが PostgreSQL 内のスキーマとして移行されかどうかを検証するには、以下のクエリを使用します。
Oracle
SELECT object_name AS package_name
FROM all_objects
WHERE object_type = 'PACKAGE'
AND owner = upper('your_schema')
ORDER BY upper(object_name);
PostgreSQL
SELECT upper(schema_name) AS package_name
FROM information_schema.schemata
WHERE schema_name not in('pg_catalog','information_schema', lower('your_schema'))
ORDER BY upper(schema_name);
- クエリ例の「
your_schema」は、Oracle ユーザー名に置き換えてください。
- ソースデータベースでオブジェクトを移行から除外する、またはターゲットデータベースにオブジェクトを導入する場合は、この前、およびこの後のクエリに
WHERE 句フィルターを追加することによって、これらのオブジェクトが計上されないようにします。
ステップ 2: テーブルの検証
AWS SCT は、適切な構造で Oracle テーブルを変換し、ターゲット PostgreSQL データベースにデプロイする、または変換されたコードを .sql ファイルとして保存するオプションを提供します。ソースとターゲット両方のデータベースで数をチェックすることによって、すべてのテーブルがターゲット PostgreSQL データベースに移行されたかどうかを検証する必要があります。以下のスクリプトは、全てのテーブルで数の検証を実行します。
Oracle
SELECT count(1) AS tables_cnt
FROM all_tables
WHERE owner = upper('your_schema');
PostgreSQL
SELECT count(1) AS tables_cnt
FROM pg_tables
WHERE schemaname = lower('your_schema');
ステップ 3: View の検証
AWS SCT は、Oracle のビューコードの PostgreSQL 内のビューへの移行に役立ちます。移行後に、以下のスクリプトを使用して Oracle ソースデータベースと PostgreSQL ターゲットデータベースのビューの数を検証します。
Oracle
SELECT count(1) AS views_cnt
FROM all_views
WHERE owner = upper('your_schema');
PostgreSQL
SELECT count(1) AS views_cnt
FROM pg_views
WHERE schemaname = lower('your_schema');
ステップ 4: シーケンスの検証
移行がどのシーケンスも移行し損なっていないことを確実にするには、ソースとターゲット両方のシーケンス数が一致する必要があります。以下のスクリプトを使用して、PostgreSQL への移行後のシーケンス数を検証します。
Oracle
SELECT count(1) AS sequence_cnt
FROM all_sequences
WHERE sequence_owner = upper('your_schema');
PostgreSQL
SELECT count(1) AS sequence_cnt
FROM information_schema.sequences
WHERE sequence_schema = lower('your_schema');
ステップ 5: トリガーの検証
数の検証は、どのデータベースオブジェクトでも実行できます。データベースのトリガーが重要であることは明らかなので、トリガーのすべての属性を検証することが必要不可欠です。以下のスクリプトを使用して、PostgreSQL への移行後のトリガーを検証します。
Oracle
SELECT
owner AS schema_name,
trigger_name,
table_name,
triggering_event,
trigger_type
FROM ALL_TRIGGERS
WHERE owner = upper('your_schema')
ORDER BY trigger_name;
PostgreSQL
SELECT
upper(trigger_schema) AS schema_name,
upper(trigger_name) AS trigger_name,
upper(event_object_table) AS table_name,
string_agg(upper(event_manipulation), ' OR ' ORDER BY CASE WHEN event_manipulation = 'INSERT' THEN 1 WHEN event_manipulation = 'UPDATE' THEN 2 ELSE 3 END) AS triggering_event,
upper(action_timing) || ' ' || CASE WHEN action_orientation = 'ROW' THEN 'EACH ROW' ELSE action_orientation END AS trigger_type
FROM information_schema.triggers
WHERE trigger_schema = lower('your_schema')
GROUP BY trigger_schema, trigger_name, event_object_table, action_timing, action_orientation
ORDER BY upper(trigger_name);
ステップ 6: プライマリキーの検証
制約は、リレーショナルデータベースでのデータ整合性の維持に役立ちます。データベースの移行中は、制約を慎重に検証することが重要です。
プライマリキーは、ターゲットテーブルに同様の「primary key」制約を作成したかどうかをチェックすることで検証できます。これは、ソース Oracle データベースとターゲット PostgreSQL データベースの両方で列と列の順序が同じでなくてはならないことを意味します。ここで説明する検証は、プライマリキーの列と列の順序をチェックしません。プライマリキーは、デフォルトで Oracle と PostgreSQL の両方で UNIQUE インデックスを作成するため、インデックス検証中に、プライマリキーの列と列の順序を検証できます。以下のスクリプトを使用して、PostgreSQL への移行後のプライマリキーを検証します。
Oracle
SELECT owner AS schema_name,
table_name,
constraint_name AS object_name,
'PRIMARY KEY' AS object_type
FROM all_constraints
WHERE owner = upper('your_schema')
AND constraint_type = 'P';
PostgreSQL
SELECT upper(n.nspname) AS schema_name,
trim(upper(conrelid::regclass::varchar), '"') AS table_name,
upper(conname::varchar) AS object_name,
'PRIMARY KEY' AS object_type
FROM pg_constraint c
JOIN pg_namespace n ON n.oid = c.connamespace
WHERE contype in ('p')
AND n.nspname = lower('your_schema');
ステップ 7: インデックスの検証
インデックスはデータベースの検索を迅速化し、インデックスの移行が良好に行われない、またはインデックスの作成が行われない場合、ターゲットデータベースのクエリに大きな影響を及ぼします。インデックスの比較は、各インデックス内の列の順序が重要であるため、簡単ではありません。列の順序が変更されると、インデックスが異なる動作をし、完全に新しいインデックスと見なされます。
リレーショナルデータベースのプライマリキーは、インデックスを内部で作成します。インデックスを検証するときは、プライマリキー用に黙示的に作成されたインデックスと、CREATE INDEX 構文によって明示的に作成されたインデックスを含める必要があります。以下のクエリは、インデックスのタイプと、すべてのインデックスのテーブルすべての列順を検証します。
Oracle
WITH cols AS (
SELECT idx.owner AS schema_name, idx.table_name, idx.index_name, cols.column_name, cols.column_position, idx.uniqueness, decode(cols.descend, 'ASC', '', ' '||cols.descend) descend
FROM ALL_INDEXES idx, ALL_IND_COLUMNS cols
WHERE idx.owner = cols.index_owner AND idx.table_name = cols.table_name AND idx.index_name = cols.index_name
AND idx.owner = upper('your_schema')
),
expr AS (
SELECT extractValue(xs.object_value, '/ROW/TABLE_NAME') AS table_name
, extractValue(xs.object_value, '/ROW/INDEX_NAME') AS index_name
, extractValue(xs.object_value, '/ROW/COLUMN_EXPRESSION') AS column_expression
, extractValue(xs.object_value, '/ROW/COLUMN_POSITION') AS column_position
FROM (
SELECT XMLTYPE(
DBMS_XMLGEN.GETXML('SELECT table_name, index_name, column_expression, column_position FROM ALL_IND_EXPRESSIONS WHERE index_owner = upper(''your_schema'') '
)
) AS xml FROM DUAL
) x
, TABLE(XMLSEQUENCE(EXTRACT(x.xml, '/ROWSET/ROW'))) xs
)
SELECT
cols.schema_name,
cols.table_name,
cols.index_name AS object_name,
'INDEX' AS object_type,
'CREATE'|| decode(cols.uniqueness, 'UNIQUE', ' '||cols.uniqueness) || ' INDEX ' || cols.index_name || ' ON VESTEK.' || cols.table_name || ' USING BTREE (' ||
listagg(CASE WHEN cols.column_name LIKE 'SYS_N%' THEN expr.column_expression || cols.descend ELSE cols.column_name || cols.descend END, ', ') within group(order by cols.column_position) || ')' AS condition_column
FROM cols
LEFT OUTER JOIN expr ON cols.table_name = expr.table_name
AND cols.index_name = expr.index_name
AND cols.column_position = expr.column_position
GROUP BY cols.schema_name, cols.table_name, cols.index_name, cols.uniqueness;
PostgreSQL
SELECT upper(schemaname) AS schema_name,
upper(tablename) AS table_name,
upper(indexname) AS object_name,
'INDEX' AS object_type,
upper(indexdef) AS condition_column
FROM pg_indexes
WHERE schemaname = lower('your_schema');
ステップ 8: Check 制約の検証
CHECK 制約の検証を実行するときは、条件付きで作成された制約のチェック、およびテーブル作成中に NOT NULL と宣言された列を含めるようにしてください。Check 制約は、それぞれのテーブル列で特定の条件を検証することによって検証できます。以下のスクリプトを使用して、PostgreSQL への移行後の check 制約を検証します。
Oracle
WITH ref AS (
SELECT extractValue(xs.object_value, '/ROW/OWNER') AS schema_name
, extractValue(xs.object_value, '/ROW/TABLE_NAME') AS table_name
, extractValue(xs.object_value, '/ROW/CONSTRAINT_NAME') AS object_name
, extractValue(xs.object_value, '/ROW/SEARCH_CONDITION') AS condition_column
, extractValue(xs.object_value, '/ROW/COLUMN_NAME') AS column_name
FROM (
SELECT XMLTYPE(
DBMS_XMLGEN.GETXML('SELECT cons.owner, cons.table_name, cons.constraint_name, cons.search_condition, cols.column_name
FROM ALL_CONSTRAINTS cons, ALL_CONS_COLUMNS cols
WHERE cons.owner = cols.owner AND cons.table_name = cols.table_name AND cons.constraint_name = cols.constraint_name
AND cons.owner = upper(''your_schema'') AND cons.constraint_type = ''C'' '
)
) AS xml FROM DUAL
) x
, TABLE(XMLSEQUENCE(EXTRACT(x.xml, '/ROWSET/ROW'))) xs
)
SELECT * FROM (
SELECT
schema_name,
table_name,
object_name,
'CHECK' AS object_type,
condition_column AS check_condition
FROM ref
UNION
SELECT
owner AS schema_name,
table_name,
'SYS_C0000'||column_id AS object_name,
'CHECK' AS object_type,
'"'||column_name||'" IS NOT NULL' AS check_condition
FROM all_tab_columns tcols where owner = upper('your_schema') and nullable = 'N'
AND NOT EXISTS ( SELECT 1 FROM ref WHERE ref.table_name = tcols.table_name
AND ref.column_name = tcols.column_name
AND ref.condition_column = '"'||tcols.column_name||'" IS NOT NULL')
);
PostgreSQL
SELECT * FROM (
SELECT
upper(n.nspname) AS schema_name,
upper(c.relname) AS table_name,
'SYS_C0000'||attnum AS object_name,
'CHECK' AS constraint_type,
'"'||upper(a.attname)||'" IS NOT NULL' AS check_condition
FROM pg_attribute a, pg_class c, pg_namespace n
WHERE a.attrelid = c.oid and c.relnamespace = n.oid AND n.nspname = 'vestek'
AND attnotnull AND attstattarget <> 0
UNION
SELECT
upper(n.nspname),
upper(conrelid::regclass::varchar) AS table_name,
upper(conname::varchar) AS object_name,
'CHECK' AS object_type,
upper(pg_get_constraintdef(c.oid)) AS check_condition
FROM pg_constraint c
JOIN pg_namespace n ON n.oid = c.connamespace
WHERE contype in ('c')
AND conrelid::regclass::varchar <> '-'
) a
WHERE schema_name = lower('your_schema');
ステップ 9: 外部キーの検証
外部キーは、別のテーブルのプライマリまたはユニークキーを参照することによって、リレーショナルテーブル間のリンクを維持するために役立ちます。以下のクエリは、外部キーの検証中に親テーブルと子テーブルの両方を考慮します。
Oracle
SELECT
c.owner AS schema_name,
c.table_name,
c.constraint_name AS object_name,
'FOREIGN KEY' AS object_type,
'FOREIGN KEY ('|| cc.fk_column || ') REFERENCES ' || p.table_name || '('|| pc.ref_column ||') NOT VALID' AS condition_column
FROM ( SELECT owner, table_name, constraint_name, r_constraint_name FROM ALL_CONSTRAINTS WHERE owner = upper('your_schema') AND constraint_type = 'R') c,
( SELECT table_name, constraint_name FROM ALL_CONSTRAINTS WHERE owner = upper('your_schema') AND constraint_type IN('P', 'U') ) p,
( SELECT owner, table_name, constraint_name, listagg(column_name, ', ') WITHIN group(ORDER BY position) fk_column
FROM ALL_CONS_COLUMNS WHERE owner = upper('your_schema') GROUP BY owner, table_name, constraint_name ) cc,
( SELECT owner, table_name, constraint_name, listagg(column_name, ', ') WITHIN group(ORDER BY position) ref_column
FROM ALL_CONS_COLUMNS WHERE owner = upper('your_schema') GROUP BY owner, table_name, constraint_name ) pc
WHERE c.r_constraint_name = p.constraint_name
AND c.table_name = cc.table_name AND c.constraint_name = cc.constraint_name
AND p.table_name = pc.table_name AND p.constraint_name = pc.constraint_name;
PostgreSQL
SELECT n.nspname::text AS schema_name,
trim(upper(conrelid::regclass::varchar), '"') AS table_name, upper(conname::varchar) AS object_name,
'FOREIGN KEY' AS object_type,
CASE contype WHEN 'f' THEN upper(pg_get_constraintdef(c.oid)) END AS condition_column
FROM pg_constraint c
JOIN pg_namespace n ON n.oid = c.connamespace
WHERE contype in ('f')
AND c.connamespace::text = lower('your_schema');
便利な PostgreSQL カタログテーブル
以下の PostgreSQL カタログテーブルとビューは、カスタムクエリの構築に役立ちます。
| ソース Oracle メタデータ |
ターゲット PostgreSQL メタデータ |
| all_tables |
pg_tables
information_schema.tables |
| all_views |
pg_views
information_schema.views |
| all_sequences |
information_schema.sequences |
| all_triggers |
information_schema.triggers |
| all_indexes |
pg_indexes |
| all_constraints |
pg_constraint join to pg_namespace |
| all_procedures |
information_schema.routines |
まとめ
データベースオブジェクトの検証は、基本的にデータベース移行の正確性の見解で、すべてのオブジェクトが適切な属性で正常に移行されたことを確認します。様々な制約を検証することは、ターゲットデータベースの整合性を二重にチェックし、データベースから不良データを排除するために役立ちます。インデックスはデータ取得操作を迅速化し、インデックスの検証は、既存のクエリがターゲットデータベースを遅くすることを防ぎます。
この記事のクエリは、Oracle と PostgreSQL の各データベースからレコードセットを取得するために、どのプログラミング言語でもそのまま使用できます。要件に基づいてカスタム検証クエリを作成することもできますが、この記事では移行後のオブジェクト検証を実行するために使用できる 1 つの方法をご紹介しました。
以下の関連リソースは、データベース移行をより良く理解するために役立ちます。
この記事に関する質問または提案などがありましたら、ぜひコメントを残してください。
著者について

Sashikanta Pattanayak はアマゾン ウェブ サービスのアソシエイトコンサルタントです。Sashikanta は、AWS クラウドでスケーラブルかつ可用性に優れたセキュアなソリューションを構築するためにお客様と連携し、主にデータベースの同種間および異種間移行に携わっています。