Amazon Web Services 한국 블로그
AWS Step Functions를 통한 Amazon EMR 작업 관리 기능 출시
AWS Step Functions를 사용하면 애플리케이션에 서버리스 워크플로우 자동화를 추가할 수 있습니다. 워크플로우의 단계는 AWS Lambda 함수, Amazon Elastic Compute Cloud(EC2) 또는 온프레미스 등 어디에서나 실행될 수 있습니다. 워크플로우 구축을 간소화하기 위해 Step Functions는 Amazon ECS, AWS Fargate, Amazon DynamoDB, Amazon Simple Notification Service(SNS), Amazon Simple Queue Service(SQS), AWS Batch, AWS Glue, Amazon SageMaker와 같은 여러 AWS 서비스에 직접 통합되어 있으며 중첩 워크플로우 실행을 위해 Step Functions 자체에도 통합됩니다.
이제 AWS Step Functions는 Amazon EMR에 연결되므로 최소한의 코드로 데이터 프로세싱 및 분석 워크플로우를 생성할 수 있어 시간이 절감되고 클러스터 사용률이 최적화됩니다. 예를 들어, 기계 학습을 위한 데이터 프로세싱 파이프라인 구축은 시간이 많이 소모되고 어려운 작업입니다. 이 새로운 통합은 병렬 실행 및 이전 단계의 결과에 기반한 종속성, 데이터 프로세싱 작업을 실행할 때의 핸들 실패 및 예외를 비롯한 워크플로우 기능을 간단히 오케스트레이션할 수 있게 해 줍니다.
구체적으로, Step Functions 상태 시스템은 이제 다음과 같은 작업을 수행할 수 있습니다.
- EMR 클러스터를 생성 또는 종료하며 클러스터 종료 보호를 변경할 수 있습니다. 이 방식에서는 기존 EMR 클러스터를 해당 워크플로우에 재사용하거나, 워크플로우 실행 중에 온디맨드로 워크플로우를 생성할 수 있습니다.
- 클러스터에 대한 EMR 단계를 추가 또는 취소합니다. 각 EMR 단계는 Apache Spark, Hive 또는 Presto 같은 도구를 비롯하여 클러스터에 설치된 소프트웨어가 프로세싱할 수 있도록 데이터를 조작하는 지침이 포함된 작업 단위입니다.
- EMR 클러스터 인스턴스 플릿 또는 그룹의 크기를 수정합니다. 이는 워크플로우 각 단계의 요구 사항에 따라 프로그래밍 방식으로 크기 조정을 관리할 수 있게 해 줍니다. 예를 들어, 컴퓨팅 집약적인 단계를 추가하기 전에 인스턴스 그룹 크기를 늘리고 작업이 완료되면 크기를 줄일 수 있습니다.
클러스터를 생성 또는 종료하거나 클러스터에 EMR 단계를 추가할 때 동기식 통합을 사용하여 EMR 클러스터에서 해당 작업이 완료되었을 때에만 워크플로우가 다음 단계로 이동하게 할 수 있습니다.
EMR 클러스터의 구성 또는 상태를 읽는 것은 Step Functions 서비스 통합의 일부가 아닙니다. 이 기능이 필요한 경우에는 Lambda 함수를 작업으로 사용하여 EMR List* 및 Describe* API에 액세스할 수 있습니다.
EMR 및 Step Functions를 사용한 워크플로우 구축
Step Functions 콘솔에서 새 상태 시스템을 생성합니다. 콘솔은 이를 시각적으로 렌더링하므로 이해하기가 훨씬 더 쉽습니다.

상태 시스템을 생성하기 위해 ASL(Amazon States Language)을 통해 다음 정의를 사용합니다.
{
"StartAt": "Should_Create_Cluster",
"States": {
"Should_Create_Cluster": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.CreateCluster",
"BooleanEquals": true,
"Next": "Create_A_Cluster"
},
{
"Variable": "$.CreateCluster",
"BooleanEquals": false,
"Next": "Enable_Termination_Protection"
}
],
"Default": "Create_A_Cluster"
},
"Create_A_Cluster": {
"Type": "Task",
"Resource": "arn:aws:states:::elasticmapreduce:createCluster.sync",
"Parameters": {
"Name": "WorkflowCluster",
"VisibleToAllUsers": true,
"ReleaseLabel": "emr-5.28.0",
"Applications": [{ "Name": "Hive" }],
"ServiceRole": "EMR_DefaultRole",
"JobFlowRole": "EMR_EC2_DefaultRole",
"LogUri": "s3://aws-logs-123412341234-eu-west-1/elasticmapreduce/",
"Instances": {
"KeepJobFlowAliveWhenNoSteps": true,
"InstanceFleets": [
{
"InstanceFleetType": "MASTER",
"TargetOnDemandCapacity": 1,
"InstanceTypeConfigs": [
{
"InstanceType": "m4.xlarge"
}
]
},
{
"InstanceFleetType": "CORE",
"TargetOnDemandCapacity": 1,
"InstanceTypeConfigs": [
{
"InstanceType": "m4.xlarge"
}
]
}
]
}
},
"ResultPath": "$.CreateClusterResult",
"Next": "Merge_Results"
},
"Merge_Results": {
"Type": "Pass",
"Parameters": {
"CreateCluster.$": "$.CreateCluster",
"TerminateCluster.$": "$.TerminateCluster",
"ClusterId.$": "$.CreateClusterResult.ClusterId"
},
"Next": "Enable_Termination_Protection"
},
"Enable_Termination_Protection": {
"Type": "Task",
"Resource": "arn:aws:states:::elasticmapreduce:setClusterTerminationProtection",
"Parameters": {
"ClusterId.$": "$.ClusterId",
"TerminationProtected": true
},
"ResultPath": null,
"Next": "Add_Steps_Parallel"
},
"Add_Steps_Parallel": {
"Type": "Parallel",
"Branches": [
{
"StartAt": "Step_One",
"States": {
"Step_One": {
"Type": "Task",
"Resource": "arn:aws:states:::elasticmapreduce:addStep.sync",
"Parameters": {
"ClusterId.$": "$.ClusterId",
"Step": {
"Name": "The first step",
"ActionOnFailure": "CONTINUE",
"HadoopJarStep": {
"Jar": "command-runner.jar",
"Args": [
"hive-script",
"--run-hive-script",
"--args",
"-f",
"s3://eu-west-1.elasticmapreduce.samples/cloudfront/code/Hive_CloudFront.q",
"-d",
"INPUT=s3://eu-west-1.elasticmapreduce.samples",
"-d",
"OUTPUT=s3://MY-BUCKET/MyHiveQueryResults/"
]
}
}
},
"End": true
}
}
},
{
"StartAt": "Wait_10_Seconds",
"States": {
"Wait_10_Seconds": {
"Type": "Wait",
"Seconds": 10,
"Next": "Step_Two (async)"
},
"Step_Two (async)": {
"Type": "Task",
"Resource": "arn:aws:states:::elasticmapreduce:addStep",
"Parameters": {
"ClusterId.$": "$.ClusterId",
"Step": {
"Name": "The second step",
"ActionOnFailure": "CONTINUE",
"HadoopJarStep": {
"Jar": "command-runner.jar",
"Args": [
"hive-script",
"--run-hive-script",
"--args",
"-f",
"s3://eu-west-1.elasticmapreduce.samples/cloudfront/code/Hive_CloudFront.q",
"-d",
"INPUT=s3://eu-west-1.elasticmapreduce.samples",
"-d",
"OUTPUT=s3://MY-BUCKET/MyHiveQueryResults/"
]
}
}
},
"ResultPath": "$.AddStepsResult",
"Next": "Wait_Another_10_Seconds"
},
"Wait_Another_10_Seconds": {
"Type": "Wait",
"Seconds": 10,
"Next": "Cancel_Step_Two"
},
"Cancel_Step_Two": {
"Type": "Task",
"Resource": "arn:aws:states:::elasticmapreduce:cancelStep",
"Parameters": {
"ClusterId.$": "$.ClusterId",
"StepId.$": "$.AddStepsResult.StepId"
},
"End": true
}
}
}
],
"ResultPath": null,
"Next": "Step_Three"
},
"Step_Three": {
"Type": "Task",
"Resource": "arn:aws:states:::elasticmapreduce:addStep.sync",
"Parameters": {
"ClusterId.$": "$.ClusterId",
"Step": {
"Name": "The third step",
"ActionOnFailure": "CONTINUE",
"HadoopJarStep": {
"Jar": "command-runner.jar",
"Args": [
"hive-script",
"--run-hive-script",
"--args",
"-f",
"s3://eu-west-1.elasticmapreduce.samples/cloudfront/code/Hive_CloudFront.q",
"-d",
"INPUT=s3://eu-west-1.elasticmapreduce.samples",
"-d",
"OUTPUT=s3://MY-BUCKET/MyHiveQueryResults/"
]
}
}
},
"ResultPath": null,
"Next": "Disable_Termination_Protection"
},
"Disable_Termination_Protection": {
"Type": "Task",
"Resource": "arn:aws:states:::elasticmapreduce:setClusterTerminationProtection",
"Parameters": {
"ClusterId.$": "$.ClusterId",
"TerminationProtected": false
},
"ResultPath": null,
"Next": "Should_Terminate_Cluster"
},
"Should_Terminate_Cluster": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.TerminateCluster",
"BooleanEquals": true,
"Next": "Terminate_Cluster"
},
{
"Variable": "$.TerminateCluster",
"BooleanEquals": false,
"Next": "Wrapping_Up"
}
],
"Default": "Wrapping_Up"
},
"Terminate_Cluster": {
"Type": "Task",
"Resource": "arn:aws:states:::elasticmapreduce:terminateCluster.sync",
"Parameters": {
"ClusterId.$": "$.ClusterId"
},
"Next": "Wrapping_Up"
},
"Wrapping_Up": {
"Type": "Pass",
"End": true
}
}
}
Step Functions 콘솔이 이 상태 시스템의 실행을 위해 새 AWS Identity and Access Management(IAM) 역할을 생성합니다. 이 역할은 EMR을 액세스하는 데 필요한 모든 권한을 포함합니다.
이 상태 시스템은 기존 EMR 클러스터를 사용하거나 새 클러스터를 생성할 수 있습니다. 다음 입력을 사용하면 워크플로우 끝에서 종료되는 새 클러스터를 생성할 수 있습니다.
{
"CreateCluster": true,
"TerminateCluster": true
}
기존 클러스터를 사용하려면 다음 구문을 사용하여 클러스터 ID에 값을 입력해야 합니다.
{
"CreateCluster": false,
"TerminateCluster": false,
"ClusterId": "j-..."
}
이제 작동 방식을 살펴 보겠습니다. 워크플로우가 시작되면 Should_Create_Cluster Choice 상태가 입력을 확인하여 Create_A_Cluster 상태로 전환될지 여부를 결정합니다. 여기에서 동기식 호출(elasticmapreduce:createCluster.sync)을 사용하여 다음 워크플로우 상태로 진행하기 전에 새 EMR 클러스터가 WAITING 상태에 도달할 때까지 기다립니다. AWS Step Functions 콘솔에는 EMR 콘솔에 대한 링크와 함께 생성 중인 리소스가 표시됩니다.

그런 다음, Merge_Results Pass 상태가 입력 상태를 새로 생성된 클러스터의 클러스터 ID와 병합하여 클러스터를 워크플로우의 다음 단계로 전달합니다.
데이터 프로세싱을 시작하기 전에 Enable_Termination_Protection 상태(elasticmapreduce:setClusterTerminationProtection)를 사용하면 EMR 클러스터의 EC2 인스턴스가 사고 또는 실수로 인해 종료되지 않도록 하는 데 도움이 됩니다.
이제 EMR 클러스터로 작업을 수행할 수 있습니다. 워크플로우에는 3개의 EMR 단계가 있습니다. 간결한 설명을 위하여 이러한 단계는 모두 이 Hive 자습서를 기반으로 준비되었습니다. 각 단계에 대해 Hive의 SQL 스타일 인터페이스를 사용하여 일부 샘플 CloudFront 로그에 대한 쿼리를 실행하고 결과를 Amazon Simple Storage Service(S3)에 작성합니다. 프로덕션 사용 사례에서는 EMR 도구가 병렬(동시에 2개 이상의 단계 실행)로 또는 일부 종속성(한 단계의 출력이 다른 단계에 필요)을 가지고 데이터를 처리 및 분석하는 방식의 조합이 사용될 가능성이 높습니다. 이와 비슷한 방식을 구현해 보겠습니다.
먼저 Parallel 상태 내에서 Step_One 및 Step_Two를 실행합니다.
- Step_One은 EMR 단계를 비동기식 작업(
elasticmapreduce:addStep.sync) 형태로 실행합니다. 이는 실행이 워크플로우의 다음 단계로 이동하기 전에 EMR 단계가 완료(또는 취소)되기를 기다림을 의미합니다. 선택적으로 EMR 단계의 실행이 예상 시간 범위 내에 이루어지도록 시간 제한을 추가할 수 있습니다. - Step_Two는 비동기식으로 EMR 단계(
elasticmapreduce:addStep)를 추가합니다. 이 경우 워크플로우는 EMR이 요청을 수신했다고 응답하는 즉시 다음 단계로 이동합니다. 몇 초가 지난 후, 다른 통합을 시도하기 위해 Step_Two(elasticmapreduce:cancelStep)를 취소합니다. 이 통합은 프로덕션 사용 사례에서 매우 유용할 수 있습니다. 예를 들어, 병렬로 실행 중인 다른 단계에서 오류가 발생하여 EMR 단계의 실행을 계속하는 것이 무의미해지는 경우 이 단계를 취소할 수 있습니다.
두 단계가 모두 완료되고 결과가 제공되었으면 Step_One과 비슷한 방식으로 Step_Three를 작업으로 실행합니다. Step_Three가 완료되면 이 워크플로우를 위해 클러스터를 더 이상 사용할 필요가 없으므로 Disable_Termination_Protection 단계로 전환합니다.
입력 상태에 따라 Should_Terminate_Cluster Choice 상태가 Terminate_Cluster 상태(elasticmapreduce:terminateCluster.sync)로 전환되어 EMR 클러스터의 종료를 기다리거나 바로 Wrapping_Up 상태로 전환되고 클러스터는 그대로 실행 중인 상태로 유지됩니다.
드디어 Wrapping_Up 상태에 도달했습니다. 최종 상태에서는 특별한 작업을 하지 않지만 Choice 상태에서는 워크플로우를 종료할 수 없습니다.
EMR 콘솔에는 클러스터와 EMR 단계의 상태가 표시됩니다.
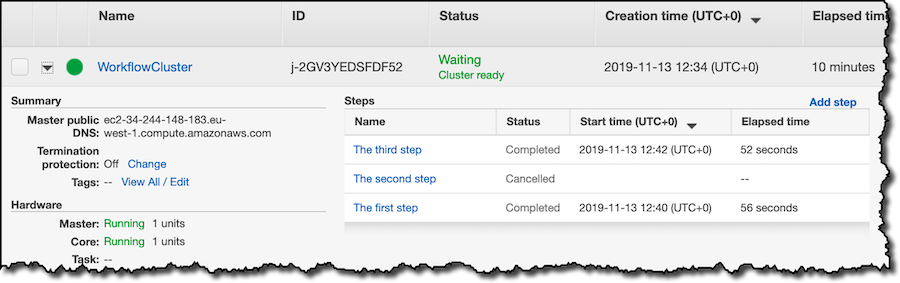
EMR 단계에 대한 출력으로 구성된 S3 버킷에서 AWS CLI(명령줄 인터페이스)를 사용하여 쿼리 결과를 찾습니다.
aws s3 ls s3://MY-BUCKET/MyHiveQueryResults/
...
사용자 입력에 따라 EMR 클러스터는 이 워크플로우 실행이 종료된 후에도 여전히 실행 중입니다. Create_A_Cluster 단계에 있는 리소스 링크를 따라 EMR 콘솔로 이동하여 클러스터를 종료합니다. 이 데모를 따라 작업을 수행하는 경우, 더 이상 필요하지 않은 EMR 클러스터를 그대로 두지 않도록 주의하십시오.
지금 이용 가능
Step Functions의 EMR 통합은 모든 리전에서 사용 가능합니다. 일반적인 Step Functions 및 EMR 요금 외에는 이 기능의 사용에 대해 별도의 요금이 부과되지 않습니다.
이제 Step Functions를 사용하면 EMR 작업 실행을 위한 복잡한 워크플로우를 빠르게 구축할 수 있습니다. 워크플로우는 병렬 실행, 종속성 및 예외 처리를 포함할 수 있습니다. Step Functions에서는 문제가 발생했을 때 어떻게 될 지를 지정할 수 있으므로 실패한 작업을 쉽게 재시도하고 중대한 오류가 발생한 경우 워크플로우를 종료할 수 있습니다. 귀사는 이 기능을 어디에 사용할 계획인지 알려주시기 바랍니다!
— Danilo