Por que o Amazon SageMaker?
O Amazon SageMaker é um serviço totalmente gerenciado que reúne um amplo conjunto de ferramentas para proporcionar machine learning (ML) de alta performance e baixo custo para qualquer caso de uso. Com o SageMaker, você pode criar, treinar e implantar modelos de ML em grande escala usando ferramentas como cadernos, depuradores, perfiladores, pipelines, MLOps e muito mais, tudo em um ambiente de desenvolvimento integrado (IDE). O SageMaker oferece suporte aos requisitos de governança com controle de acesso simplificado e transparência sobre seus projetos de ML. Além disso, você pode criar seus próprios FMs, modelos grandes que foram treinados em grandes conjuntos de dados, com ferramentas específicas para ajustar, experimentar, retreinar e implantar FMs. O SageMaker oferece acesso a centenas de modelos pré-treinados, incluindo FMs disponíveis publicamente, que você pode implantar com apenas alguns cliques.
Por que o Amazon SageMaker?
O Amazon SageMaker é um serviço totalmente gerenciado que reúne um amplo conjunto de ferramentas para proporcionar machine learning (ML) de alta performance e baixo custo para qualquer caso de uso. Com o SageMaker, você pode criar, treinar e implantar modelos de ML em grande escala usando ferramentas como cadernos, depuradores, perfiladores, pipelines, MLOps e muito mais, tudo em um ambiente de desenvolvimento integrado (IDE). O SageMaker oferece suporte aos requisitos de governança com controle de acesso simplificado e transparência sobre seus projetos de ML. Além disso, você pode criar seus próprios FMs, modelos grandes que foram treinados em grandes conjuntos de dados, com ferramentas específicas para ajustar, experimentar, retreinar e implantar FMs. O SageMaker oferece acesso a centenas de modelos pré-treinados, incluindo FMs disponíveis publicamente, que você pode implantar com apenas alguns cliques.
Benefícios do SageMaker
Habilite mais pessoas para inovar com ML
-
Analistas de negócios
-
Cientistas de dados
-
Engenheiros de ML
-
Analistas de negócios
-

Analistas de negócios
Faça previsões de ML usando uma interface visual com o SageMaker Canvas. -
Cientistas de dados
-
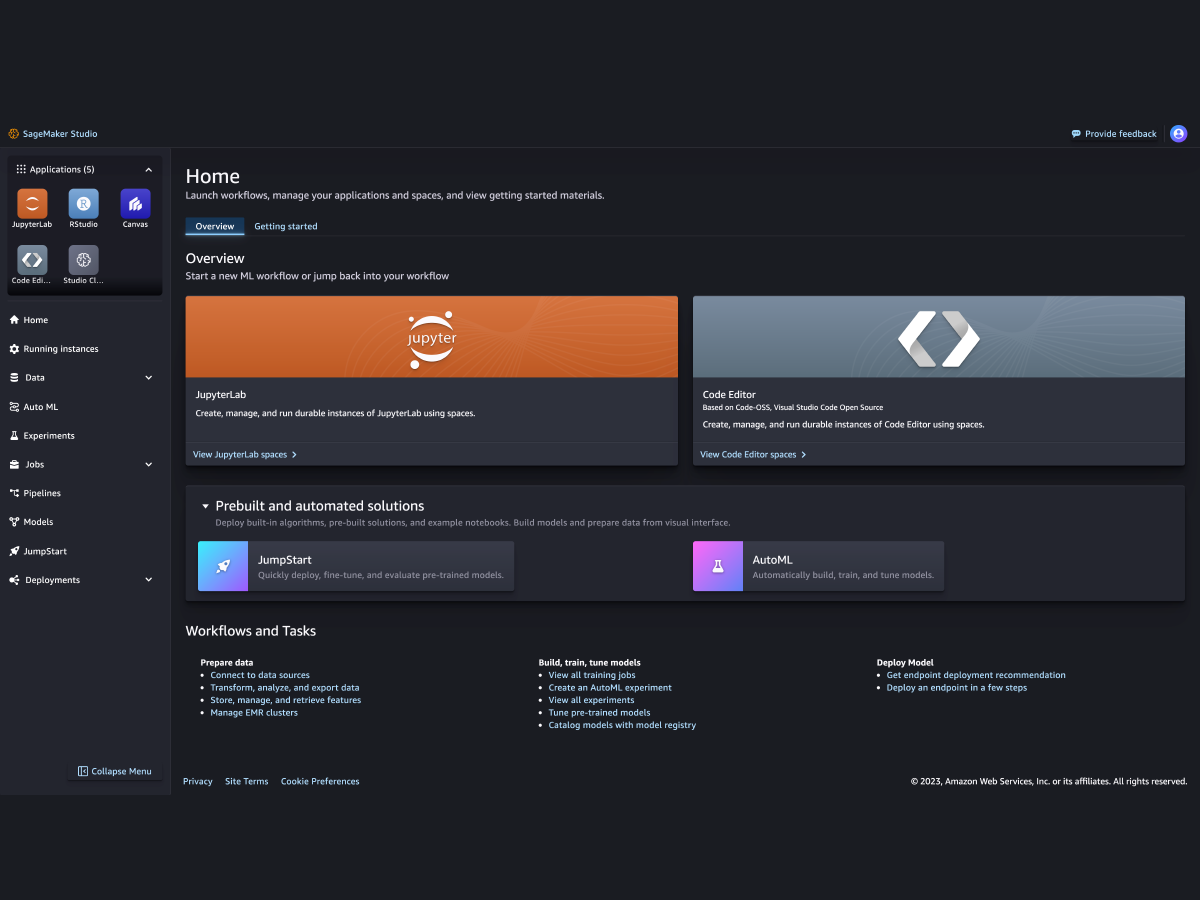
Cientistas de dados
Prepare dados e crie, treine e implante modelos com o SageMaker Studio. -
Engenheiros de ML
-

Engenheiros de ML
Implante e gerencie modelos em escala com o SageMaker MLOps.
Suporte para os principais frameworks, toolkits e linguagens de programação de ML
