How was this content?
- Learn
- Building generative AI applications for your startup
Building generative AI applications for your startup
Recent generative AI advancements are raising the bar on tools that can help startups to rapidly build, scale, and innovate. This widespread adoption and democratization of machine learning (ML), specifically with the transformer neural network architecture, is an exciting inflection point in technology. With the right tools, startups can build new ideas or pivot their existing product to harness the benefits of generative AI for their customers.
Are you ready to build a generative AI application for your startup? Let’s first review the concepts, core ideas, and common approaches to build generative AI applications.
What are generative AI applications?
Generative AI applications are programs that are based on a type of AI that can create new content and ideas, including conversations, stories, images, videos, code, and music. Like all AI applications, generative AI applications are powered by ML models that are pre-trained on vast amounts of data, and commonly referred to as foundation models (FMs).
An example of a generative AI application is Amazon CodeWhisperer, an AI coding companion that helps developers to build applications faster and more securely by providing whole line and full function code suggestions in your integrated development environment (IDE). CodeWhisperer is trained on billions of lines of code, and can generate code suggestions ranging from snippets to full functions instantly, based on your comments and existing code. Startups can use AWS Activate credits with the CodeWhisperer Professional Tier, or start with the Individual Tier which is free to use.
The rapidly-developing generative AI landscape
There is rapid growth occurring in generative AI startups, and also within startups building tools to simplify the adoption of generative AI. Tools such as LangChain—an open source framework for developing applications powered by language models—are making generative AI more accessible to a wider range of organizations, which will lead to faster adoption. These tools also include prompt engineering, augmenting services (such as embedding tools or vector databases), model monitoring, model quality measurement, guard rails, data annotation, reinforced learning from human feedback (RLHF), and many more.
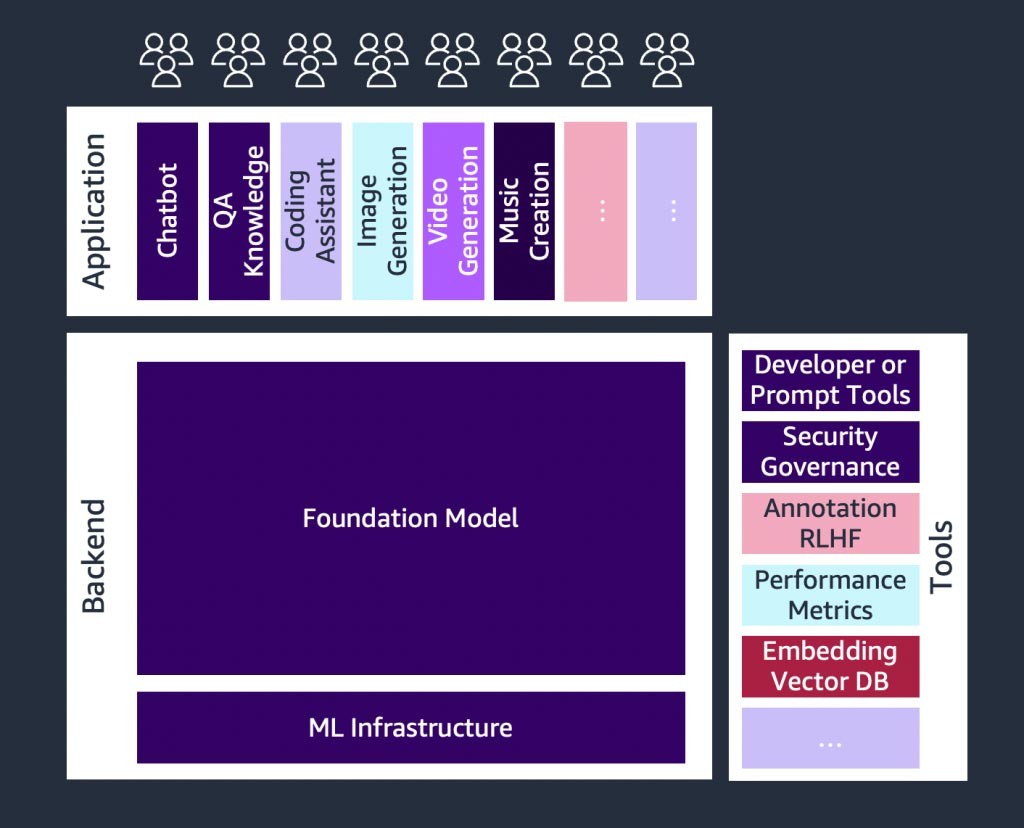
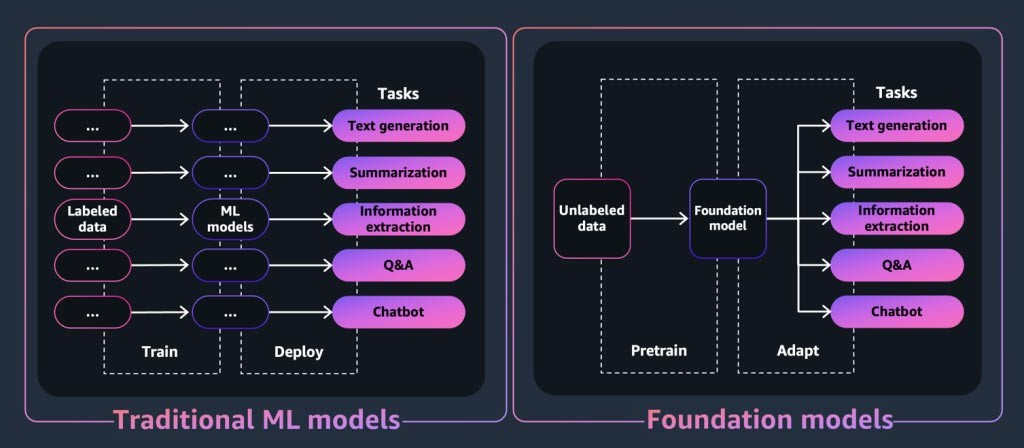
An introduction to foundation models
For a generative AI application or tool, at the core is the foundation model. Foundation models are a class of powerful machine learning models that are differentiated by their ability to be pre-trained on vast amounts of data in order to perform a wide range of downstream tasks. These tasks include text generation, summarization, information extraction, Q&A, and/or chatbots. In contrast, traditional ML models are trained to perform a specific task from a data set.
So how does a foundation model “generate” the output that generative AI applications are known for? These capabilities result from learning patterns and relationships that allow the FM to predict the next item or items in a sequence, or generate a new one:
- In text-generating models, FMs output the next word, next phrase, or the answer to a question.
- For image-generation models, FMs output an image based on the text.
- When an image is an input, FMs output the next relevant or upscaled image, animation, or 3D images.
In each case, the model starts with a seed vector derived from a “prompt”: Prompts describe the task the model has to perform. The quality and detail (also known as the “context”) of the prompt determine the quality and relevance of the output.
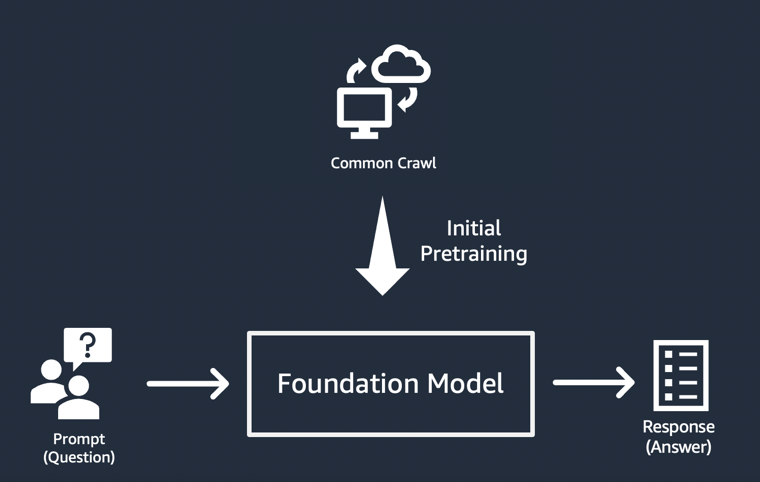
The simplest implementation of generative AI applications
The simplest approach for building a generative AI application is to use an instruction-tuned foundation model, and provide a meaningful prompt (“prompt engineering”) using zero-shot learning or few-shot learning. An instruction-tuned model (such as FLAN T5 XXL, Open-Llama, or Falcon 40B Instruct) uses its understanding of related tasks or concepts to generate predictions to prompts. Here are some prompt examples:
Zero-shot learning
Title: \”University has new facility coming up“\\n Given the above title of an imaginary article, imagine the article.\n
RESPONSE: <a 500-word article>
Few-shot learning
This is awesome! // Positive
This is bad! // Negative
That movie was hopeless! // Negative
What a horrible show! //
RESPONSE: Negative
Startups, in particular, can benefit from the rapid deployment, minimal data needs, and cost optimization that result from using an instruction-tuned model.
To learn more about considerations for selecting a foundation model, check out Selecting the right foundation model for your startup.
Customizing foundation models
Not all use cases can be met by using prompt engineering on instruction-tuned models. Reasons for customizing a foundation model for your startup may include:
- Adding a specific task (such as code generation) to the foundation model
- Generating responses based on your company’s proprietary dataset
- Seeking responses generated from higher quality datasets than those that pre-trained the model
- Reducing “hallucination,” which is output that is not factually correct or reasonable
There are three common techniques to customize a foundation model.
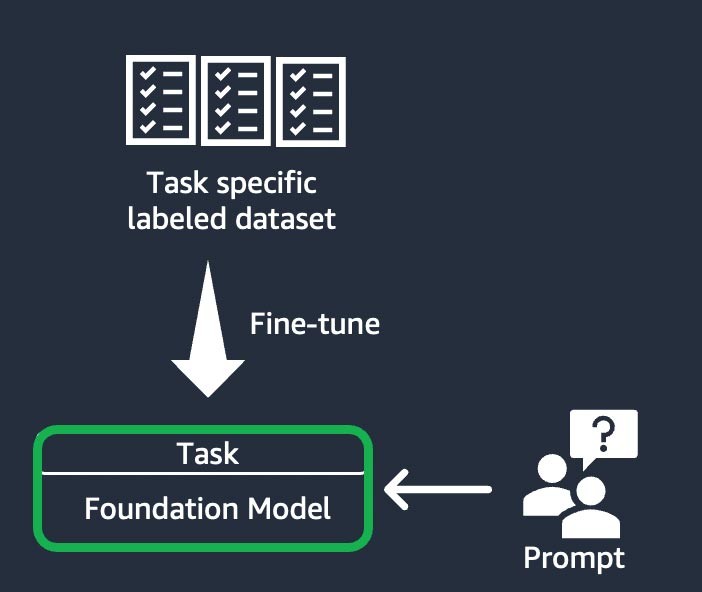
Instruction-based fine-tuning
This technique involves training the foundation model to complete a specific task, based on a task-specific labeled dataset. A labeled data set consists of pairs of prompts and responses. This customization technique is beneficial to startups who want to customize their FM quickly and with a minimal dataset: It takes a fewer data sets and steps to train. The model weights update based on the task or the layer that you are fine-tuning.
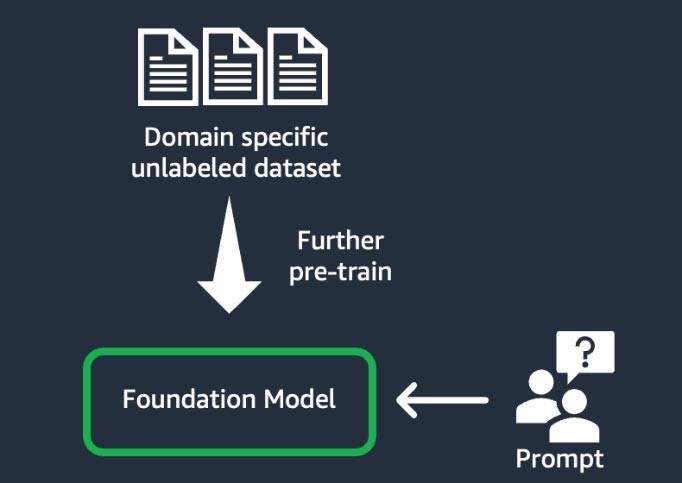
Domain adaptation (also known as “further pre-training”)
This technique involves training the foundation model using a large “corpus”—a body of training materials—of domain-specific unlabeled data (known as “self-supervised learning”). This technique benefits use cases that include domain-specific jargon and statistical data that the existing foundation model hasn’t seen before. For example, startups building a generative AI application to work with proprietary data in the financial domain may benefit from further pre-training the FM on custom vocabulary and from “tokenization,” a process of breaking down text into smaller units called tokens.
To achieve higher quality, some startups implement reinforced learning from human feedback (RLHF) techniques in this process. On top of this, instruction-based fine-tuning will be required to fine-tune a specific task. This is an expensive and time-consuming technique compared to the others. The model weights update across all the layers.
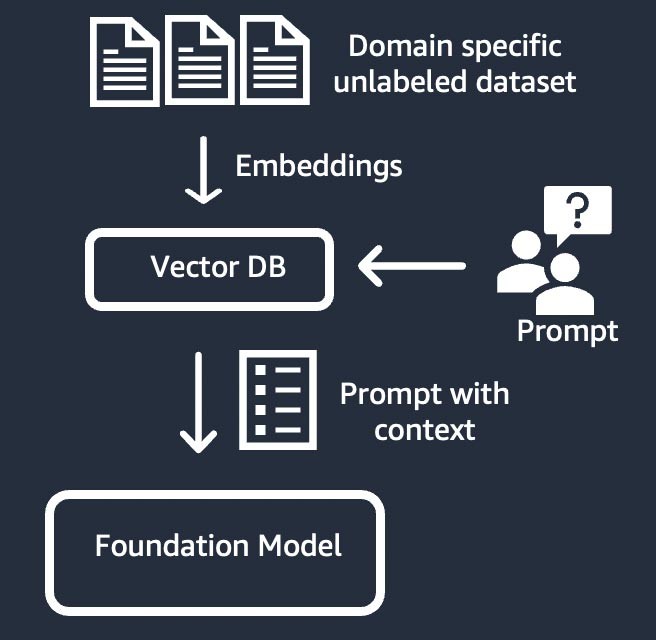
Information retrieval (also known as “retrieval-augmented generation” or “RAG”)
This technique augments the foundation model with an information retrieval system that is based on dense vector representation. The closed-domain knowledge or proprietary data goes through a text-embedding process to generate a vector representation of the corpus, and is stored in a vector database. A semantic search result based on the user query becomes the context for the prompt. The foundation model is used to generate a response based on the prompt with context. In this technique, the foundation model’s weight is not updated.
Components of a generative AI application
In the above sections, we learnt various approaches startups can take with foundation models when building generative AI applications. Now, let’s review how these foundation models are part of the typical ingredients or components required to build a generative AI application.
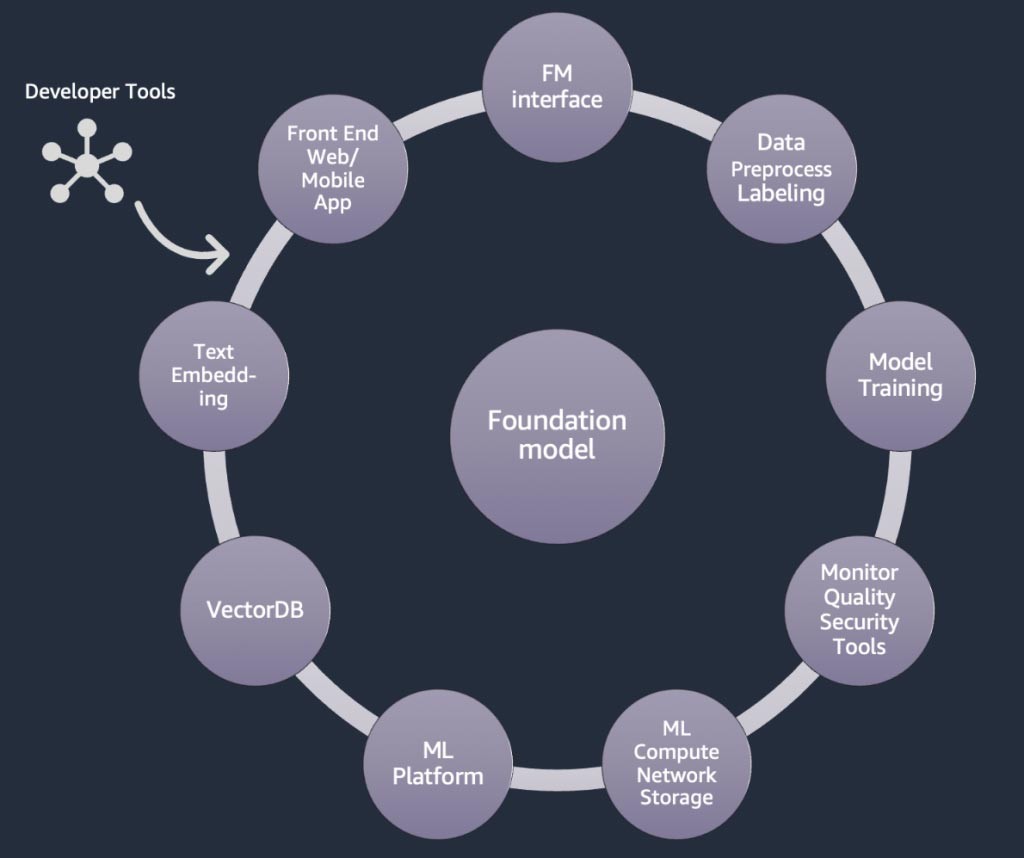
At the core is a foundation model (center). In the simplest approach discussed earlier in this blog, this requires a web application or mobile app (top left) that accesses the foundation model through an API (top). This API is either a managed service through a model provider or self-hosted using an open source or proprietary model. In the self-hosting case, you may need a machine learning platform that is supported by accelerated computing instances to host the model.
In the RAG technique, you will need to add a text embedding endpoint and a vector database (left and lower left). Both of these are provided as either an API service or are self-hosted. The text embedding endpoint is backed by a foundation model, and the choice of foundation model depends on the embedding logic and tokenization support. All of these components are connected together using developer tools, which provide the framework for developing generative AI applications.
And, lastly, when you choose the customization techniques of fine-tuning or further pre-training of a foundation model (right), you need components that help with data pre-processing and annotation (top right), and an ML platform (bottom) to run the training job on specific accelerated computing instances. Some model providers support API-based fine-tuning, and in such cases, you need not worry about the ML platform and underlying hardware.
Regardless of the customization approach, you may also want to integrate components that provide monitoring, quality metrics, and security tools (lower right).
Which AWS services should I use to build my generative AI application?
The following diagram, Figure 9, maps each component to corresponding AWS service(s). Note that these are a curated set of AWS services I see startups taking benefits from; however, there are other AWS services available.
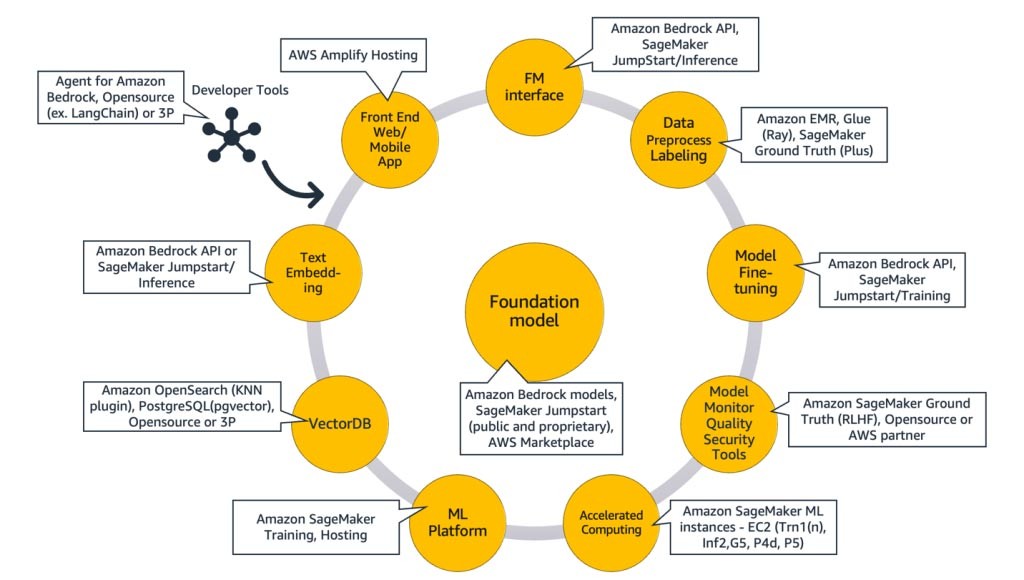
To elaborate, I will start with mapping AWS services to the common components of a generative AI application. Then I will explain the AWS services that map to the remaining components in Figure 9, based on the approaches you use to implement your application.
Common components
The common components of a generative AI application are the foundation model (FM), its interface, and optionally the machine learning (ML) platform and accelerated computing. These can be met using managed offerings available from AWS:
Amazon Bedrock (foundation model and its interface components)
Amazon Bedrock, a fully managed service that makes foundation models from leading AI startups (AI21’s Jurassic, Anthropic’s Claude, Cohere’s Command and Embedding, Stability’s SDXL models) and Amazon (Titan Text and Embeddings models) available via API, so you can choose from a wide range of FMs to find the model that’s best suited for your use case. Amazon Bedrock provides API or serverless access to a set of foundation models to provide three capabilities: text embedding, prompt/response, and fine-tuning (on select models).
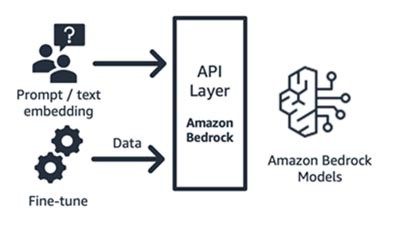
Amazon Bedrock is well-suited for application or model consumer startups who are building value-added services – prompt engineering, retrieval-augmented generation, and more – around a foundation model of their choice. Its pricing model is pay-by-use, typically in the unit of millions of tokens processed. Amazon Bedrock is generally available; however some of the features discussed in this blog are in private preview. Learn more here.
Amazon SageMaker JumpStart (foundation model and its interface components)
AWS offers generative AI capabilities to Amazon SageMaker Jumpstart: a foundation model hub containing both publicly available and proprietary models, quick start solutions, and example notebooks to deploy and fine-tune models. When you deploy these models, it creates a real-time inference endpoint which you can access as directly using SageMaker SDK/API. Or, you can front-end SageMaker’s foundation model endpoint with AWS API Gateway and a lightweight compute logic in an AWS Lambda function. You can also leverage some of these models for text embedding.
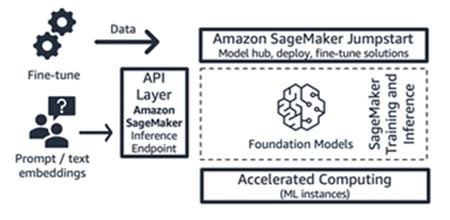
Both the inference endpoint and the fine-tuning training jobs run on your choice of managed ML instances (see “Accelerated Computing” in Figure 9) using SageMaker as the ML platform (see “ML Platform” in Figure 9). SageMaker Jumpstart is well-suited for application or model consumer startups who want more control over their infrastructure, and who have moderate ML skills and infrastructure knowledge. Its pricing model is pay-by-use, typically in the unit of instance-hours. All the models and solutions in this offering are generally available.
Amazon SageMaker training and inference (ML platform)
Startups can leverage Amazon SageMaker’s training and inference features for advanced capabilities like distributed training, distributed inference, multi-model endpoints, and more. You can bring the foundation models from the model hub of your choice – whether that’s SageMaker JumpStart or Hugging Face or AWS Marketplace, or you can build your own foundation model from scratch.
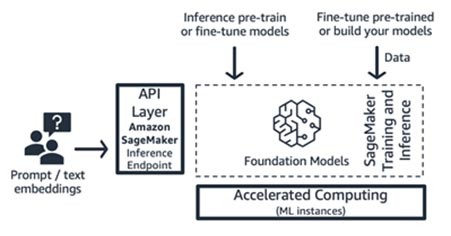
SageMaker is well-suited for full-stack generative AI application builders (from model providers to model consumers), or for model providers with teams who have advanced ML and data pre-processing skills. SageMaker also offers a pay-by-use pricing model, typically in the unit of instance-hours.
AWS Trainium and AWS Inferentia (accelerated computing)
In April 2023, AWS announced general availability of Amazon EC2 Trn1n Instances powered by AWS Trainium, and Amazon EC2 Inf2 Instances powered by AWS Inferentia2. You can leverage AWS purpose-built accelerators (AWS Trainium and AWS Inferentia) using SageMaker as the ML platform.
The benchmark testing for inference workloads reports Inf2 instances perform with 52% lower costs against a comparable inference-optimized Amazon EC2 instance. I suggest keeping an eye on fast development cycles of AWS Neuron SDK, where approximately every month AWS is adding new model architecture in their support matrix for both training and inference.
Approaches for building generative AI applications
Now, let’s discuss each of the components in Figure 9 from an implementation perspective.
The zero-shot or few-shot learning inference approach
As we discuss in earlier, zero-shot or few-shot learning is the simplest approach for building a generative AI application. To build applications based on this approach, all you need are the services for the four common components (foundation model, its interface, ML platform, and compute), your custom code to generate prompts, and a front-end web/mobile app.
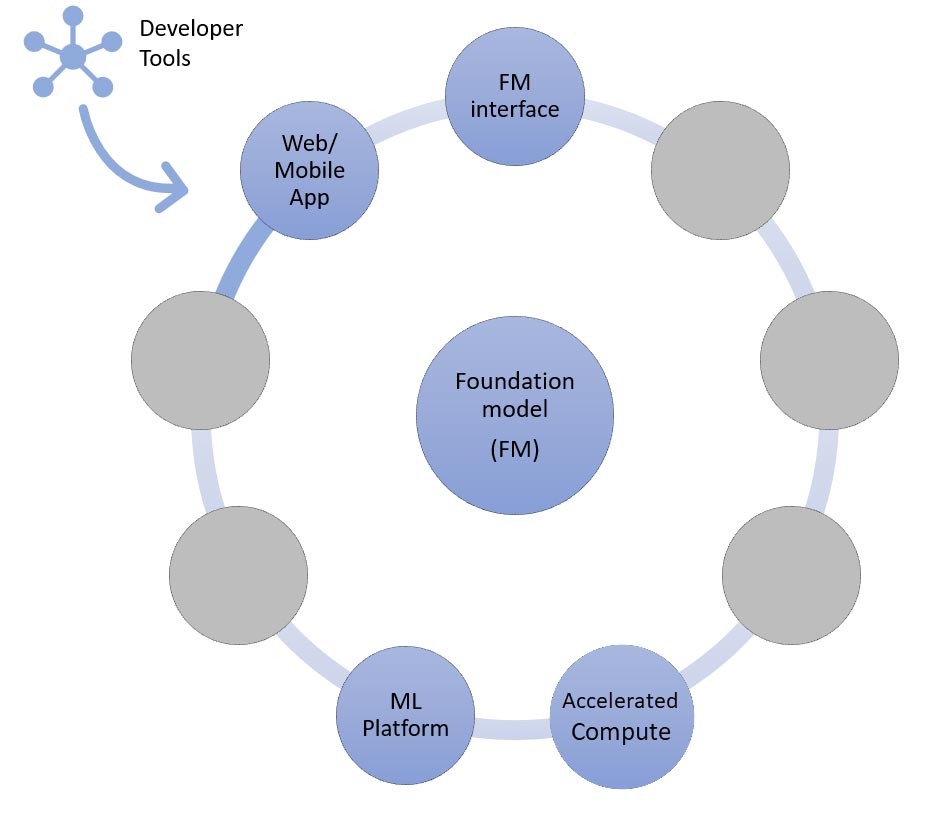
To learn more about selecting a foundation model through Amazon Bedrock or Amazon SageMaker JumpStart, refer to the model selection guidelines here.
The custom code can leverage developer tools like LangChain for prompt templates and generation. The LangChain community has already added support for Amazon Bedrock, Amazon API Gateway, and SageMaker endpoints. Just to remind you, you may also like to leverage AWS Amazon CodeWhisperer, a coding companion tool, to help improve developers’ efficiency.
Startups building a front-end web app or mobile app can easily start and scale by using AWS Amplify, and host these web apps in a fast, secure, and reliable way using AWS Amplify Hosting.
Check out this example of zero-shot learning that builds with SageMaker Jumpstart.
The information retrieval approach
As discussed, one of the ways your startup can customize foundation models is through augmenting with an information retrieval system, most commonly known as retrieval-augmented generation (RAG). This approach involves all of the components mentioned in zero-shot and few-shot learning, as well as the text embeddings endpoint and vector database.
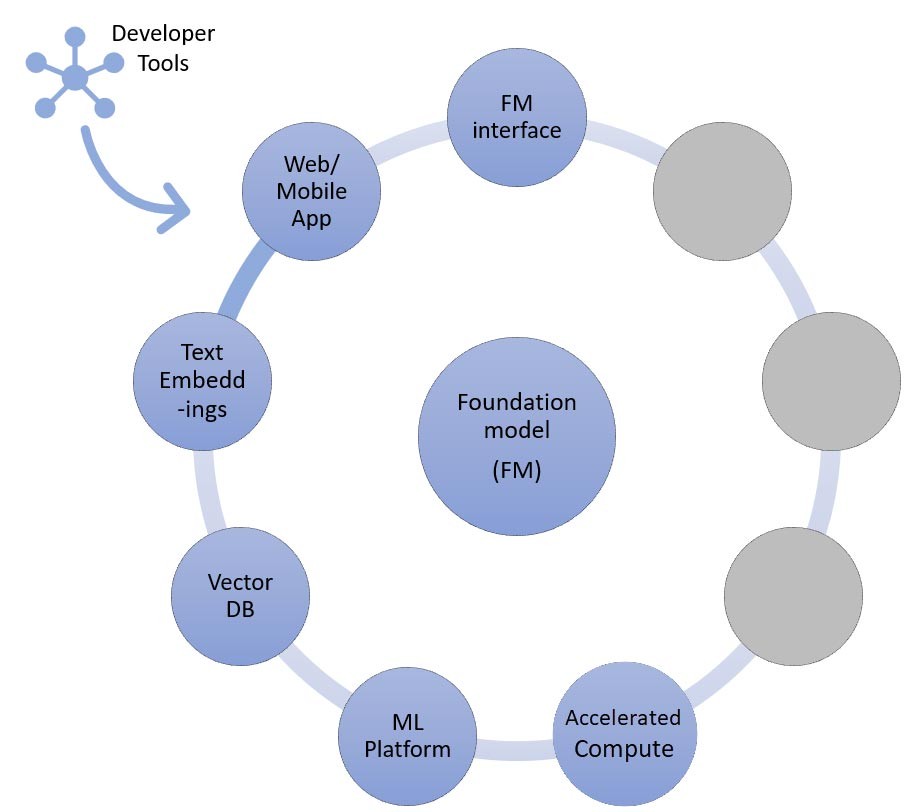
Options for the text embeddings endpoint vary depending on which AWS managed service you’ve selected:
- Amazon Bedrock offers an embeddings large language model (LLM) that translates text inputs (words, phrases, or possibly large units of text) into numerical representations (known as embeddings) that contain the semantic meaning of the text.
- If using SageMaker JumpStart, you can host an embeddings model like GPT-J 6B or any other LLM of your choice from the model hub. The SageMaker endpoint can be invoked by the SageMaker SDK or Boto3 to translate text inputs into embeddings.
The embeddings can then be stored in a vector datastore to do semantic searches using either Amazon RDS for PostgreSQL’s pgvector extension, or Amazon OpenSearch Service’s k-NN plugin. Startups prefer one or the other based on which service they are typically most comfortable using. In some cases, startups use AI native vector databases from AWS partners or from open source. For guidance on vector datastore selection, I recommend referring to The role of vector datastores in generative AI applications.
In this approach too, developer tools play a pivotal role. They provide an easy plug-n-play framework, prompt templates, and wide-support for integrations.
Going forward, you can also leverage agents for Amazon Bedrock, a new capability for developers that can manage API calls to your company systems.
Check out this example of using retrieval augmented generation with foundation models in Amazon SageMaker Jumpstart.
The fine-tuning or further pre-training approach
Now, let’s map the components to the AWS services needed for the last approach to implementing a generative AI application: fine-tuning or further pre-training a foundation model. This approach involves all of the components discussed in zero-shot or few-shot learning, as well as data pre-processing and model training.
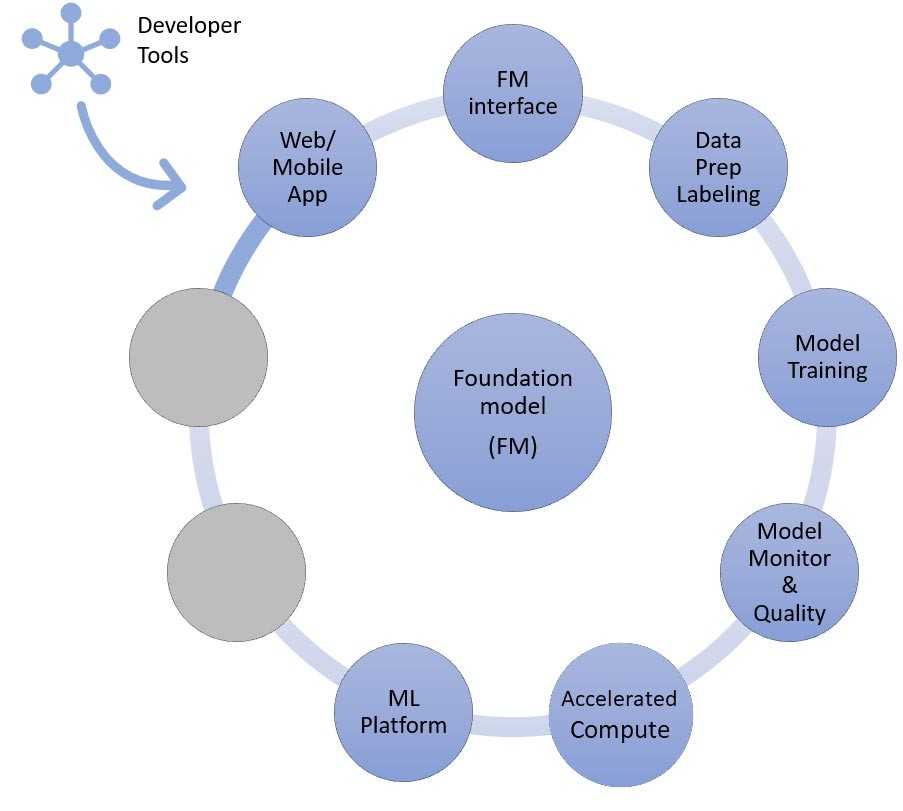
Data preparation (sometimes called preprocessing or annotation) is particularly important during fine-tuning, where you need smaller and labeled data sets. Startups can easily get started using Amazon SageMaker Data Wrangler. This service helps reduce the time it takes to aggregate and prepare tabular and image data for machine learning from weeks to minutes. You may also leverage this service’s inference pipeline feature to chain the preprocessing workflow to training or fine-tuning jobs.
If your startup needs to preprocess a huge corpus of unstructured and unlabeled datasets in your data lake on Amazon S3, you have a few options:
- If you’re using Python and popular Python libraries, is useful to leverage AWS Glue for Ray. AWS Glue uses Ray, an open source unified compute framework used to scale Python workloads
- Alternatively, Amazon EMR can help process vast amounts of data using open source tools such as Apache Spark, Apache Hive, Apache HBase, Apache Flink, Apache Hudi, and Presto.
For the model training component of this approach, Amazon Bedrock allows you to privately customize FMs with your own data. It manages your FMs at scale without having to manage any infrastructure (this is the API way to fine-tune). Alternatively, the SageMaker Jumpstart approach provides a quick-start solution to privately fine-tune (on select models) for instruction or domain adaptation using your own data. You can modify the SageMaker JumpStart bundled training script for your needs, or you can bring your own training scripts for open-source models, and submit these as SageMaker’s training job. If you have to further pre-train the model (typically for open source models), you can leverage SageMaker’s distributed training libraries to speed up and efficiently utilize all of the GPUs of an ML instance.
In addition, you may also consider fully managed data generation, data annotation services, and model development with the Reinforced Learning from Human Feedback technique using Amazon SageMaker Ground Truth Plus.
An example architecture
So, how do all of these components look when realizing a generative AI use case? While every startup has a different use case, and unique approaches to solving real world problems, one common theme or starting point I have seen in building generative AI applications is the retrieval-augmented generation approach. After plugging in all those AWS services discussed above, the architecture looks like this:
Ingestion pipeline – The domain-specific or proprietary data is preprocessed as text data. It is either batch processed (stored in Amazon S3) or streamed (using Amazon Kinesis) as it is created or updated through the embedding process, and stored in dense vector representation.

Retrieval pipeline – When a user queries the proprietary data stored in vector representation, it retrieves the related documents using k nearest neighbor (kNN) or semantic search. It is then decoded back to clear text. The output serves as rich and dense context to the prompt.

Summarization generation pipeline – The context is added to the prompt with the original user query to get insight or summarization from the retrieved document.

All of these layers can be built with a few lines of code by using developer tools like LangChain.
Conclusion
This is one way to build an end-to-end generative AI application using AWS services. The AWS services you select will vary based on the use case or customization approach you take. Stay tuned on latest AWS releases, solutions, and blogs in generative AI by bookmarking this link.
Let’s go build generative AI applications on AWS! Kickstart your generative AI journey with AWS Activate, a free program specifically designed for startups and early stage entrepreneurs that offers the resources needed to get started on AWS.

Hrushikesh Gangur
Hrushikesh Gangur is a Principal Solutions Architect for AI/ML startups with expertise in both AWS machine learning and networking services. He helps startups building generative AI, autonomous vehicles, and ML platforms to run their business efficiently and effectively on AWS.
How was this content?