



Qual é a diferença entre bancos de dados relacionais e não relacionais?
Bancos de dados relacionais e não relacionais são dois métodos de armazenamento de dados para aplicações. Um banco de dados relacional (ou banco de dados SQL) armazena dados em formato tabular com linhas e colunas. As colunas contêm atributos de dados, e as linhas têm valores de dados. Você pode vincular as tabelas em um banco de dados relacional para obter insights mais profundos sobre a interconexão entre diversos pontos de dados. Por outro lado, bancos de dados não relacionais (ou bancos de dados NoSQL) usam uma variedade de modelos de dados para acessar e gerenciar dados. Eles são otimizados especificamente para aplicações que exigem grande volume de dados, baixa latência e modelos de dados flexíveis, o que é obtido relaxando algumas das restrições de consistência de dados de outros bancos de dados.
Como bancos de dados relacionais armazenam dados?
Bancos de dados relacionais armazenam dados em tabelas com colunas e linhas. Cada coluna representa um atributo de dados específico, e cada linha representa uma instância desses dados.
Cada tabela recebe uma chave primária: uma coluna identificadora que identifica a tabela de maneira exclusiva. Essa chave primária é usada para estabelecer relações entre tabelas. Você a usa para relacionar linhas entre tabelas como a chave externa em outra tabela.
Quando duas tabelas estão conectadas, você obtém dados de ambas com uma única consulta. Você escreve consultas SQL para interagir com o banco de dados relacional.
Exemplo de dados armazenados
Por exemplo, imagine que um varejista crie uma tabela com todos os seus produtos. Nessa tabela, você pode ter colunas para os nomes, as descrições e os preços dos produtos. Outra tabela contém dados sobre clientes, seus nomes e o que eles compraram.
As tabelas a seguir demonstram essa abordagem.
| Product_id (Chave primária) |
Product_name |
Product_cost |
| P1 |
Product_A |
100 USD |
| P2 |
Product_B |
50 USD |
| P3 |
Product_C |
80 USD |
| Customer_id |
Customer_name |
Item_purchased (Chave externa) |
| C1 |
Customer_A |
P2 |
| C2 |
Customer_B |
P1 |
| C3 |
Customer_C |
P3 |
Como bancos de dados não relacionais armazenam dados?
Existem vários sistemas de banco de dados não relacionais diferentes devido às variações na forma como gerenciam e armazenam dados sem esquema. Dados sem esquema são dados armazenados sem as restrições exigidas pelos bancos de dados relacionais.
A seguir, explicamos alguns dos tipos comuns de bancos de dados não relacionais.
Bancos de dados de chave-valor
Um banco de dados de chave-valor armazena dados como uma coleção de pares de chave-valor. Em um par, a chave atua como um identificador exclusivo. As chaves e os valores podem ser qualquer coisa, desde objetos simples até objetos compostos complexos.
Leia sobre bancos de dados de chave-valor »
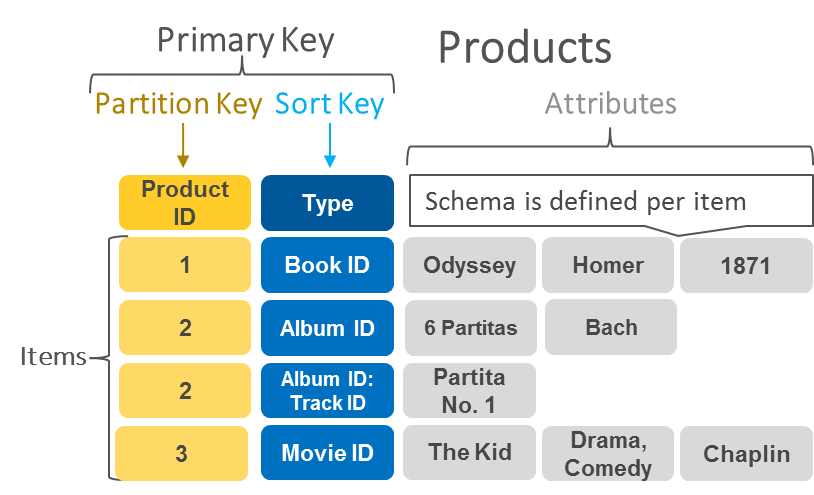
Bancos de dados de documentos
Bancos de dados orientados a documentos têm o mesmo formato de modelo de documento que os desenvolvedores utilizam no código da aplicação. Eles armazenam dados como objetos JSON que são flexíveis, semiestruturados e de natureza hierárquica.
O exemplo a seguir mostra como podem ser os dados armazenados em um banco de dados de documentos.
| { company_name: "AnyCompany", address: {street: "1212 Main Street", city: "Anytown"}, phone_number: "1-800-555-0101", industry: ["food processing", "appliances"] type: "private", number_of_employees: 987 } |
Leia sobre bancos de dados de documentos »
Bancos de dados de gráficos
Os bancos de dados de grafos foram criados especificamente para possibilitar o armazenamento de relacionamentos e a navegação por eles. Eles usam nós para armazenar entidades de dados e arestas para armazenar os relacionamentos entre as entidades.
Uma borda sempre tem um nó inicial, um nó final, um tipo e uma direção. Ela pode descrever, por exemplo, relacionamentos, ações e propriedade entre pais e filhos.
Leia sobre bancos de dados de grafos »

Principais diferenças: bancos de dados relacionais versus não relacionais
Bancos de dados relacionais e não relacionais armazenam e gerenciam dados de maneiras muito diferentes. As seções a seguir discutem diferenças específicas.
Estrutura
Bancos de dados relacionais armazenam dados em formato tabular e seguem regras rígidas sobre variações de dados e relacionamentos de tabelas. Eles permitem que você processe consultas complexas em dados estruturados ao mesmo tempo em que mantém a integridade e a consistência dos dados.
Bancos de dados não relacionais são mais flexíveis e úteis para dados com requisitos variáveis. Você pode usá-los para armazenar imagens, vídeos, documentos e outros conteúdos semiestruturados e não estruturados.
Mecanismo de integridade de dados
Atomicidade, consistência, isolamento e durabilidade (ACID) referem-se à capacidade do banco de dados de manter a integridade dos dados apesar de erros ou interrupções no seu processamento.
Um modelo de banco de dados relacional segue propriedades ACID estritas. Isso significa que um conjunto de operações consequentes sempre será concluído em conjunto. Se uma única operação falhar, todo o conjunto de operações falhará. Isso garante a precisão dos dados em todos os momentos.
Em contraste, bancos de dados não relacionais oferecem um modelo mais flexível, sendo basicamente disponíveis, de estado flexível e eventualmente consistentes (BASE).
Bancos de dados não relacionais garantem disponibilidade, mas não consistência imediata. O estado do banco de dados pode mudar com o tempo e, eventualmente, se tornar consistente. Alguns bancos de dados não relacionais podem oferecer conformidade com o ACID com performance ou outras vantagens e desvantagens.
Performance
A performance dos bancos de dados relacionais depende de seu subsistema de disco. Para melhorar a performance do banco de dados, você pode usar SSDs e otimizar o disco configurando-o com uma matriz redundante de discos independentes (RAID). Para obter a máxima performance, você também precisa otimizar índices, estruturas de tabela e consultas.
Por outro lado, a performancedos bancos de dados NoSQL depende da latência da rede, do tamanho do cluster de hardware e da aplicação de chamada. Há algumas maneiras de melhorar a performance de um banco de dados não relacional:
- Aumentar o tamanho do cluster
- Minimizar a latência da rede
- Indexar e armazenar em cache
Os bancos de dados NoSQL oferecem maior performance e escalabilidade para casos de uso específicos em comparação com um banco de dados relacional.
Escala
O esquema rígido de um sistema de banco de dados relacional pode apresentar desafios em grande escala. Normalmente, você escala verticalmente adicionando mais recursos de CPU ou RAM ao servidor. Você também pode escalar horizontalmente, duplicando dados entre servidores para workloads somente leitura. No entanto, o ajuste de escala horizontal para workloads de leitura e gravação exige estratégias especiais, como particionamento e fragmentação.
Leia sobre fragmentação de banco de dados »
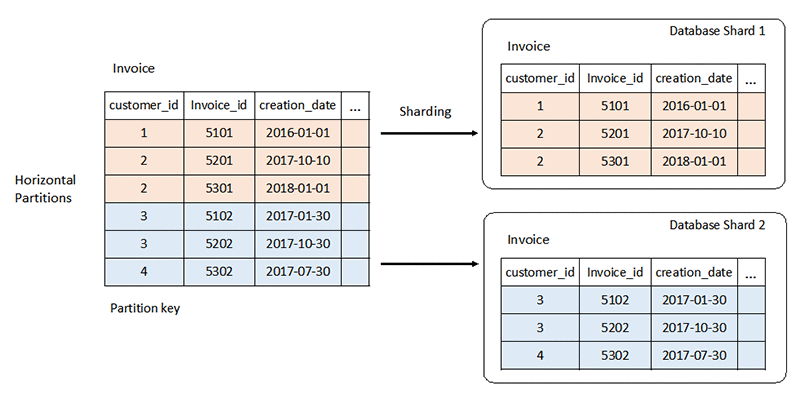
Por outro lado, os bancos de dados NoSQL são altamente escaláveis. Você pode distribuir sua workload em vários nós com mais facilidade. Esses bancos de dados podem processar um grande volume de dados particionando em conjuntos menores e distribuindo esses conjuntos em vários nós.

Quando usar bancos de dados relacionais versus não relacionais
Bancos de dados relacionais são a melhor opção quando seus dados são previsíveis em termos de tamanho, estrutura e frequência de acesso. Você também pode preferir um sistema de gerenciamento de banco de dados relacional se os relacionamentos entre entidades forem importantes. Por exemplo, se você tem um grande conjunto de dados com uma estrutura e relacionamentos complexos, quer que esses relacionamentos se destaquem pela análise e facilidade de uso.
Por outro lado, um modelo não relacional funciona melhor para armazenar dados flexíveis em forma ou tamanho, ou que possam mudar no futuro.
Além disso, em alguns casos, as relações de dados simplesmente não se encaixam bem no formato tabular de chaves primárias e estrangeiras. Por exemplo, para modelar os amigos e relacionamentos em uma rede de mídia social, você precisaria de uma tabela com centenas de linhas em um banco de dados relacional.
Em contraste, isso pode ser representado em uma única linha em um banco de dados não relacional. O exemplo a seguir mostra entradas de dados de um membro com quatro amigos em um banco de dados não relacional.
| ID do membro ID do amigo M1 M2 M1 M3 M1 M4 M1 M5 |
{member name: “member 1” member friends: “member 2, member 3, member 4, member 5”} |
Resumo das diferenças: bancos de dados relacionais versus não relacionais
| Categoria |
Banco de dados relacional |
Banco de dados não relacional |
| Modelo de dados |
Tabular. |
Chave-valor, documento ou grafo. |
| Tipo de dados |
Estruturado. |
Dados estruturados, semiestruturados e não estruturados. |
| Integridade dos dados |
Alto com total conformidade com ACID. |
Modelo de consistência eventual. |
| Performance |
Aprimorada com a adição de mais recursos ao servidor. |
Melhorada com a adição de mais nós de servidor. |
| Escalabilidade |
O ajuste de escala horizontal requer estratégias adicionais de gerenciamento de dados. |
O ajuste de escala horizontal é simples e direto. |
Como a AWS pode dar suporte aos seus requisitos de banco de dados relacionais e não relacionais?
A Amazon Web Services (AWS) oferece muitos serviços para requisitos de banco de dados relacionais e não relacionais.
Serviços da AWS para bancos de dados relacionais
O Amazon Relational Database Service (Amazon RDS) é uma coleção de serviços gerenciados que simplifica a configuração, a operação e a escalabilidade de um banco de dados relacional na nuvem. Os bancos de dados em nuvem oferecem muitos benefícios, como performance, escala e eficiência de custos. Você pode usar mecanismos de banco de dados relacional como estes:
- Amazon RDS para SQL Server para implantar várias edições do SQL Server (2014, 2016, 2017 e 2019)
- Amazon RDS para MySQL para oferecer suporte às versões 5.7 e 8.0 do MySQL Community Edition
- Amazon RDS para MariaDB para oferecer suporte às versões 10.3, 10.4, 10.5 e 10.6 do MariaDB Server
Além disso, o Amazon RDS para Oracle tem dois modelos de licenciamento diferentes, o que significa que você não precisa comprar licenças Oracle separadamente se não as tiver.
Serviços da AWS para bancos de dados não relacionais
A AWS também tem vários serviços de banco de dados NoSQL para atender a todos os seus requisitos de NoSQL. Veja alguns exemplos:
- O Amazon DynamoDB é um serviço de banco de dados de chave-valor que fornece latência consistente de menos de 10 milissegundos para workloads em qualquer escala.
- O Amazon DocumentDB (com compatibilidade com o MondoDB) é um popular banco de dados orientado a documentos com APIs poderosas e intuitivas para desenvolvimento flexível e iterativo.
- O Amazon MemoryDB para Redis é um durável serviço de banco de dados na memória. Ele oferece latência de leitura e gravação em microssegundos para performance ultrarrápida.
- O Amazon Neptune é um serviço de banco de dados de grafos totalmente gerenciado para criar e executar aplicativos de grafos de alta performance.
- O Amazon OpenSearch Service foi criado especificamente para fornecer visualizações e análises quase em tempo real de dados gerados por máquina.
Comece a usar bancos de dados relacionais e não relacionais na AWS criando uma conta hoje mesmo.