ما المقصود بالتعليم بواسطة التعزيز؟
ما المقصود بالتعليم بواسطة التعزيز؟
التعلم المعزز (RL) هو أسلوب التعلم الآلي (ML) الذي يدرب البرامج على اتخاذ القرارات لتحقيق أفضل النتائج. إنه يحاكي أسلوب "التعلم بالمحاولة والخطأ" الذي تستخدمه العناصر البشرية لتحقيق أهدافها. يتم تعزيز إجراءات البرامج التي تعمل على تحقيق هدفك، وفي الوقت نفسه يحدث تجاهل للإجراءات التي تنتقص من الهدف.
خوارزميات التعليم بواسطة التعزيز (RL) تستخدم نموذج "الثواب والعقاب" في معالجة البيانات. تتعلم الخوارزميات من التعليقات حول كل إجراء وتكتشف بنفسها أفضل مسارات المعالجة لتحقيق النتائج النهائية. الخوارزميات قادرة أيضًا على تطبيق الإشباع المتأخر أو تأخير الإرضاء. إن أفضل إستراتيجية شاملة قد تتطلب تضحيات قصيرة المدى، ولذا فإن أفضل نهج تكتشفه الخوارزميات قد يشمل بعض العقوبات أو التراجع أثناء المسار. RL هي طريقة قوية لمساعدة أنظمة الذكاء الاصطناعي (AI) على تحقيق النتائج المثلى في البيئات غير المرئية.
ما مزايا التعليم بواسطة التعزيز (RL)؟
توجد مزايا كثيرة تنتج عن استخدام التعليم بواسطة التعزيز (RL). ومع ذلك، غالبًا ما تبرز الميزات الثلاث التالية.
يتفوق في البيئات المعقدة
يُمكن استخدام خوارزميات التعليم بواسطة التعزيز (RL) في البيئات المعقدة المشتملة على قواعد وتبعيات كثيرة. في نفس البيئة، قد لا يكون العنصر البشري قادرًا على تحديد المسار الأفضل الذي ينبغي اتخاذه، حتى وإن توفرت له المعرفة الفائقة بالبيئة. بدلًا من ذلك، تتكيف خوارزميات التعليم بواسطة التعزيز (RL) الخالية من النماذج بسرعة مع البيئات دائمة التغير وتجد إستراتيجيات جديدة لتحسين النتائج.
يتطلب تفاعلًا بشريًا أقل
في خوارزميات تعلّم الآلة التقليدية، يجب على العنصر البشري تصنيف أزواج البيانات لتوجيه الخوارزمية. عند استخدام خوارزمية التعليم بواسطة التعزيز (RL)، لا يكون ذلك ضروريًا. إنها تتعلم من تلقاء نفسها. وفي الوقت نفسه توفر آليات لدمج التعليقات البشرية، ما يسمح للأنظمة بأن تتكيف مع التفضيلات البشرية والخبرة والتصحيحات.
يتحسن للأهداف طويلة المدى
يركز التعليم بواسطة التعزيز (RL) بطبيعته على تعظيم مبدأ الثواب على المدى الطويل، ما يجعله مناسبًا للسيناريوهات التي فيها تؤدي الإجراءات إلى عواقب مستمرة. إنه مناسب بشكل خاص لمواقف العالم الحقيقي التي لا يتوفر فيها تعليقات فورية حول كل خطوة، حيث يمكنه التعلم من المكافآت المتأخرة.
على سبيل المثال، قد تؤدي القرارات المتعلقة باستهلاك الطاقة أو تخزينها إلى عواقب طويلة المدى. يمكن استخدام التعليم بواسطة التعزيز (RL) في تحسين كفاءة الطاقة والتكلفة على المدى الطويل. باستخدام البنيات المناسبة، يمكن لوكلاء التعليم بواسطة التعزيز (RL) أيضًا تعميم إستراتيجياتهم التي تم تعلّمها عبر مهام متشابهة ولكن ليست متطابقة.
ما حالات استخدام التعليم بواسطة التعزيز (RL)؟
يمكن تطبيق التعليم بواسطة التعزيز (RL) على مجموعة كبيرة من حالات الاستخدام في العالم الحقيقي. نقدم في ما بعد بعض الأمثلة.
تخصيص التسويق
في تطبيقات مثل أنظمة التوصية، يمكن للتعليم بواسطة التعزيز (RL) تخصيص الاقتراحات للمستخدمين الأفراد بناءً على تفاعلاتهم. هذا يؤدي إلى تجارب أكثر تخصيصًا. على سبيل المثال، قد يعرض التطبيق إعلانات لمستخدم استنادًا إلى بعض المعلومات الديموغرافية. مع كل تفاعل مع الإعلانات، يتعرف التطبيق على الإعلانات التي سيتم عرضها للمستخدم لتحسين مبيعات المنتجات.
تحديات التحسين
تعمل طرق التحسين التقليدية على حل المشكلات من خلال تقييم الحلول الممكنة ومقارنتها بناءً على معايير معينة. في المقابل، يقدم التعليم بواسطة التعزيز (RL) ميزة التعلّم من التفاعلات للبحث عن أفضل الحلول أو الحلول الأقرب إلى الأفضل بمرور الوقت.
على سبيل المثال، يستخدم أحد الأنظمة السحابية الخاصة بتحسين النفقات التعليم بواسطة التعزيز (RL) للتكيف مع احتياجات الموارد المتقلبة، واختيار أفضل أنواع المثيلات والكميات والتكوينات. إنه يتخذ القرارات بناءً على عوامل مثل البنية التحتية السحابية الحالية والمتاحة، والإنفاق، والاستخدام.
التنبؤات المالية
إن الطبيعة الديناميكية للأسواق المالية تتسم بالتعقيد، حيث إن الخصائص الإحصائية تتغير بمرور الوقت. يمكن لخوارزميات التعليم بواسطة التعزيز (RL) تحسين العوائد طويلة الأجل من خلال النظر في تكاليف المعاملات والتكيف مع تحولات السوق.
على سبيل المثال، يُمكن للخوارزمية مراقبة قواعد وأنماط سوق الأسهم قبل أن تختبر الإجراءات وتُسجّل المكافآت المرتبطة بها. إنها تنشئ بشكل ديناميكي وظيفة قيمة وتطور إستراتيجية لتحقيق أقصى قدر من الأرباح.
كيف يعمل التعلم المعزز؟
تشبه عملية تعلم خوارزميات التعلم المعزز (RL) التعلم المعزز للحيوان والإنسان في مجال علم النفس السلوكي. على سبيل المثال، قد يكتشف الطفل أنه يتلقى الثناء من أبويه عندما يساعد شقيقه أو في التنظيف ولكنه يتلقى ردود فعل سلبية عندما يرمي الألعاب أو يصرخ. سرعان ما يتعلم الطفل أي مجموعة من الأنشطة تؤدي إلى المكافأة النهائية.
تحاكي خوارزمية RL عملية تعلم مماثلة. وهي تحاول القيام بأنشطة مختلفة لمعرفة القيم السلبية والإيجابية المرتبطة بها لتحقيق نتيجة المكافأة النهائية.
المفاهيم الأساسية
في التعلم المعزز، هناك بعض المفاهيم الأساسية التي يجب أن تتعرف عليها:
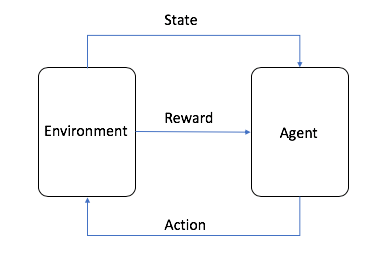
- الوكيل هو خوارزمية ML (أو النظام الذاتي)
- البيئة هي مساحة المشكلة التكيفية مع سمات مثل المتغيرات وقيم الحدود والقواعد والإجراءات الصالحة
- الإجراء هو خطوة يتخذها وكيل RL للتنقل في البيئة
- الدولة هي البيئة في نقطة زمنية معينة
- المكافأة هي القيمة الإيجابية أو السلبية أو الصفرية - بمعنى آخر، المكافأة أو العقوبة - لاتخاذ إجراء
- المكافأة التراكمية هي مجموع جميع المكافآت أو القيمة النهائية
أساسيات الخوارزمية
يعتمد التعلم المعزز على عملية Markov لاتخاذ القرار، وهي نمذجة رياضية لصنع القرار تستخدم خطوات زمنية منفصلة. في كل خطوة، يتخذ الوكيل إجراءً جديدًا ينتج عنه حالة بيئية جديدة. وبالمثل، تُعزى الحالة الحالية إلى تسلسل الإجراءات السابقة.
من خلال التجربة والخطأ في التنقل عبر البيئة، يقوم الوكيل ببناء مجموعة من القواعد أو السياسات. تساعد السياسات في تحديد الإجراء الذي يجب اتخاذه بعد ذلك للحصول على المكافأة التراكمية المثلى. يجب على الوكيل أيضًا الاختيار بين المزيد من استكشاف البيئة لتعلم مكافآت إجراءات الدولة الجديدة أو تحديد إجراءات المكافأة العالية المعروفة من دولة معينة. وهذا ما يسمى مقايضة الاستكشاف والاستغلال.
ما أنواع خوارزميات التعليم بواسطة التعزيز (RL)؟
توجد خوارزميات كثيرة مستخدمة في التعليم بواسطة التعزيز (RL)، مثل Q-learning، وأساليب تدرج السياسات، وأساليب مونت كارلو، وتعلّم الفروق الزمنية. التعليم بواسطة التعزيز (RL) العميق هو تطبيق الشبكات العصبونية العميقة على التعليم بواسطة التعزيز (RL). من أمثلة خوارزميات التعليم بواسطة التعزيز (RL) العميق الخوارزمية "تحسين سياسات منطقة الثقة (TRPO)".
يمكن تجميع كل هذه الخوارزميات في فئتين رئيسيتين.
التعليم بواسطة التعزيز (RL) القائم على النموذج
عادةً ما يُستخدم التعليم بواسطة التعزيز (RL) القائم على النموذج عندما تكون البيئات محددة جيدًا وغير متغيرة وحيث يكون اختبار بيئة العالم الحقيقي صعبًا.
يقوم الوكيل أولاً ببناء (نموذج) تمثيل داخلي للبيئة. يستخدم هذه العملية في بناء هذا النموذج:
- يتخذ إجراءات داخل البيئة ويدوّن الحالة الجديدة وقيمة المكافأة
- يربط انتقال حالة الإجراء بقيمة المكافأة.
بمجرد اكتمال النموذج، يحاكي الوكيل تسلسلات الإجراءات بناءً على احتمالية المكافآت التراكمية المثلى. ثم يقوم أيضًا بتعيين قيم لتسلسلات الإجراءات نفسها. وبالتالي يقوم الوكيل بتطوير إستراتيجيات مختلفة داخل البيئة لتحقيق الهدف النهائي المنشود.
مثال
افترض وجود روبوت يتعلم التنقل في مبنى جديد للوصول إلى غرفة معينة. في البداية، يستكشف الروبوت بحرية ويبني نموذجًا داخليًا (أو خريطةً داخليةً) للمبنى. على سبيل المثال، قد يعرف أنه يواجه مصعدًا بعد التحرك للأمام لمسافة 10 أمتار من المدخل الرئيسي. بمجرد إنشاء الخريطة، يمكنه إنشاء سلسلة من تسلسلات مسارات أقصر بين المواقع المختلفة التي يزورها بشكل متكرر في المبنى.
التعليم بواسطة التعزيز (RL) الخالي من النموذج
من الأفضل استخدام التعليم بواسطة التعزيز (RL) الخالي من النموذج عندما تكون البيئة كبيرةً ومعقدةً ولا يمكن وصفها بسهولة. هذا النوع مثالي عندما تكون البيئة غير معلومة ومتغيرة، ولا ينتج عن الاختبارات القائمة على البيئة سلبيات كبيرة.
لا يقوم الوكيل ببناء نموذج داخلي للبيئة وطبيعتها الديناميكية. بل إنه يستخدم "طريقة التجربة والخطأ" داخل البيئة. يسجل ويدوّن أزواج الحالة-الإجراء وتسلسلات أزواج الحالة-الإجراء لتطوير سياسة.
مثال
افترض وجود سيارة ذاتية القيادة تحتاج إلى التنقل في حركة المرور بالمدينة. يمكن للطرق وأنماط حركة المرور وسلوك المشاة وعوامل أخرى لا حصر لها أن تجعل البيئة ديناميكيةً ومعقدةً للغاية. تقوم فرق الذكاء الاصطناعي بتدريب السيارة في بيئة محاكاة في المراحل الأولية. تتخذ السيارة إجراءات بناءً على حالتها الحالية وتتلقى مكافآت أو عقوبات.
بمرور الوقت، من خلال قيادة ملايين الأميال في سيناريوهات افتراضية مختلفة، تتعرف السيارة على الإجراءات الأفضل لكل حالة دون وضع نمذجة واضحة لديناميكيات حركة المرور بأكملها. عند دخولها إلى العالم الحقيقي، تستخدم السيارة السياسة التي تم تعلّمها ولكنها تستمر في تحسينها باستخدام بيانات جديدة.
ما الفرق بين تعلّم الآلة بواسطة التعزيز، والخاضع للإشراف، وغير الخاضع للإشراف؟
في حين أن التعلم الخاضع للإشراف والتعلم غير الخاضع للإشراف والتعليم بواسطة التعزيز (RL) كلها خوارزميات من خوارزميات تعلّم الآلة في مجال الذكاء الاصطناعي، إلا أن هناك اختلافات بين الأنواع الثلاثة.
اقرأ حول التعلّم الخاضع للإشراف والتعلّم غير الخاضع للإشراف »
مقارنة بين التعليم بواسطة التعزيز (RL) والتعلم الخاضع للإشراف
في التعلم الخاضع للإشراف، يُمكنك تحديد كل من المدخلات والمخرجات المرتبطة المتوقعة. على سبيل المثال، يُمكنك تقديم مجموعة من الصور التي تحمل تصنيفات كلاب أو قطط، ومن المتوقع بعد ذلك أن تحدد الخوارزمية صورة حيوان جديدة على أنها كلب أو قطة.
تتعلم خوارزميات التعلم الخاضع للإشراف الأنماط والعلاقات بين أزواج المدخلات والمخرجات. ثم تتوقع النتائج بناءً على بيانات الإدخال الجديدة. يتطلب الأمر مشرفًا، وعادةً ما يكون إنسانًا، لتصنيف كل سجل بيانات في مجموعة بيانات تدريب يكون لها مخرج واحد.
في المقابل، يكون للتعليم بواسطة التعزيز (RL) هدف نهائي محدد جيدًا في شكل نتيجة مرغوبة ولكن لا يوجد مشرف لتصنيف البيانات المرتبطة مسبقًا. أثناء التدريب، بدلًا من محاولة تعيين مدخلات ذات مخرجات معلومة، يقوم البرنامج بتعيين المدخلات بنتائج محتملة. من خلال مكافأة السلوكيات المرغوبة، فإنك تعطي قيمةً ووزنًا لأفضل النتائج.
مقارنة بين التعليم بواسطة التعزيز (RL) والتعلم غير الخاضع للإشراف
تتلقى خوارزميات التعلم غير الخاضع للإشراف مدخلات ليس لها مخرجات محددة أثناء عملية التدريب. تبحث الخوارزميات عن الأنماط والعلاقات المخفية داخل البيانات باستخدام وسائل إحصائية. على سبيل المثال، يُمكنك تقديم مجموعة من المستندات، وتقوم الخوارزمية بتجميعها في فئات تحددها بناءً على الكلمات الموجودة في النص. لا تحصل على نتائج محددة؛ بل تحصل على نتائج تقع ضمن نطاق.
على العكس من ذلك، يحتوي التعليم بواسطة التعزيز (RL) على هدف نهائي محدد مسبقًا. في حين أن التعليم بواسطة التعزيز (RL) يتطلب نهجًا استكشافيًا، يجري التحقق من الاستكشافات بصفة مستمرة وتخضع للتحسين لزيادة احتمالية الوصول إلى الهدف النهائي. يقوم التعليم بواسطة التعزيز (RL) بتعليم نفسه للوصول إلى نتائج محددة جدًا.
ما التحديات التي تواجه التعليم بواسطة التعزيز (RL)؟
في حين أن تطبيقات التعليم بواسطة التعزيز (RL) يمكن أن تغير العالم، إلا أنه ربما لا يكون من السهل نشر هذه الخوارزميات.
التطبيق العملي
قد يكون من غير العملي تجربة أنظمة الثواب والعقاب في العالم الحقيقي. على سبيل المثال، قد يؤدي اختبار طائرة مسيرة في العالم الحقيقي بدون اختبارها في جهاز محاكاة أولاً إلى تحطم أعداد كبيرة من الطائرات. فبيئات العالم الحقيقي تتغير كثيرًا وتتغير تغيرًا كبيرًا وتقل فيها التحذيرات. وهذا قد يجعل من الصعب على الخوارزمية أن تؤتي ثمارها خلال الممارسة.
القابلية للتفسير
مثل أي مجال من مجالات العلوم، يبحث علم البيانات أيضًا في الأبحاث والنتائج القطعية للتوصّل إلى وضع المعايير وتحديد الإجراءات. يفضل علماء البيانات معرفة كيفية الوصول إلى نتيجة قطعية بعينها للتحقق من الإثبات والتكرار.
مع خوارزميات التعليم بواسطة التعزيز (RL) المعقدة، قد يكون من الصعب التأكد من أسباب اتخاذ سلسلة معينة من الخطوات. ما الإجراءات المتسلسلة التي أدت إلى النتيجة النهائية المثلى؟ قد يكون من الصعب استنتاج ذلك، ما يسبب تحديات في التنفيذ.
كيف تساعدك AWS في التعليم بواسطة التعزيز (RL)؟
تقدم Amazon Web Services (AWS) العديد من العروض التي تساعدك في تطوير خوارزميات التعليم بواسطة التعزيز (RL) وتدريب تلك الخوارزميات ونشرها في تطبيقات من العالم الحقيقي.
باستخدام Amazon SageMaker، يمكن للمطورين وعلماء البيانات تطوير نماذج RL القابلة للتطوير بسرعة وسهولة. يُمكنك الجمع بين إطار التعلّم العميق (مثل TensorFlow أو Apache MXNet) وإحدى مجموعات أدوات التعليم بواسطة التعزيز (RL) (مثل RL Coach أو RLlib) وبيئة لمحاكاة سيناريو من العالم الحقيقي. يُمكنك استخدامه في إنشاء نموذجك واختباره.
باستخدام AWS RoboMaker، يمكن للمطورين تشغيل المحاكاة وتوسيع نطاقها وأتمتتها باستخدام خوارزميات RL للروبوتات دون أي متطلبات للبنية التحتية.
احصل على تجربة عملية مع AWS DeepRacer، سيارة السباق المستقلة بالكامل بمقياس 1/18. إنها تتميز ببيئة سحابية كاملة التكوين يمكنك استخدامها في تدريب نماذج التعليم بواسطة التعزيز (RL) وتكوينات الشبكة العصبونية.
ابدأ بالتعلم المعزز على AWS من خلال إنشاء حساب اليوم.
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages