AWS Partner Network (APN) Blog
Best Practices from SoftServe for Using Kubernetes on AWS in Enterprise IT
By Jarosław Grząbel, Cloud Architect and AWS Ambassador – SoftServe
 |
| SoftServe |
 |
Over the past couple of years, enterprises have increasingly started to adopt containers to increase IT agility. Often, Kubernetes is being used as the platform to power these efforts.
Managing traditional Kubernetes clusters can be difficult and require a lot of time and know-how to set up and operate, especially at scale. Despite the availability of multiple automation frameworks like kubespray to simplify cluster provisioning, maintenance of a secure and scalable control plane, as well as management of worker nodes, remains difficult.
In on-premises environments, additional limitations with regards to the scaling of physical resources apply; this typically implies the forecasting, purchasing, and managing of server hardware.
Amazon Web Services (AWS) removes much of the heavy lifting to provision and run production-grade Kubernetes environments through Amazon Elastic Kubernetes Service (Amazon EKS). In an enterprise IT setting, however, there are more elements required to provision and operate a Kubernetes platform successfully, both technically and organizationally.
In this post, I will share best practices on how to run Kubernetes in an enterprise IT environment. As a cloud architect at SoftServe, an AWS Premier Tier Services Partner, I have helped develop and implement multiple solutions based on Amazon EKS, helping enterprise clients transform their applications from monoliths to microservices.
I have been an AWS Ambassador since 2022. AWS Ambassadors are prominent leaders who are passionate about sharing AWS technical expertise. We author blogs and whitepapers, create and deliver public presentations, and contribute to open-source projects.
Typical Amazon EKS Architecture
The diagram below shows a typical Amazon EKS-based platform that we see at SoftServe being deployed with enterprise customers.
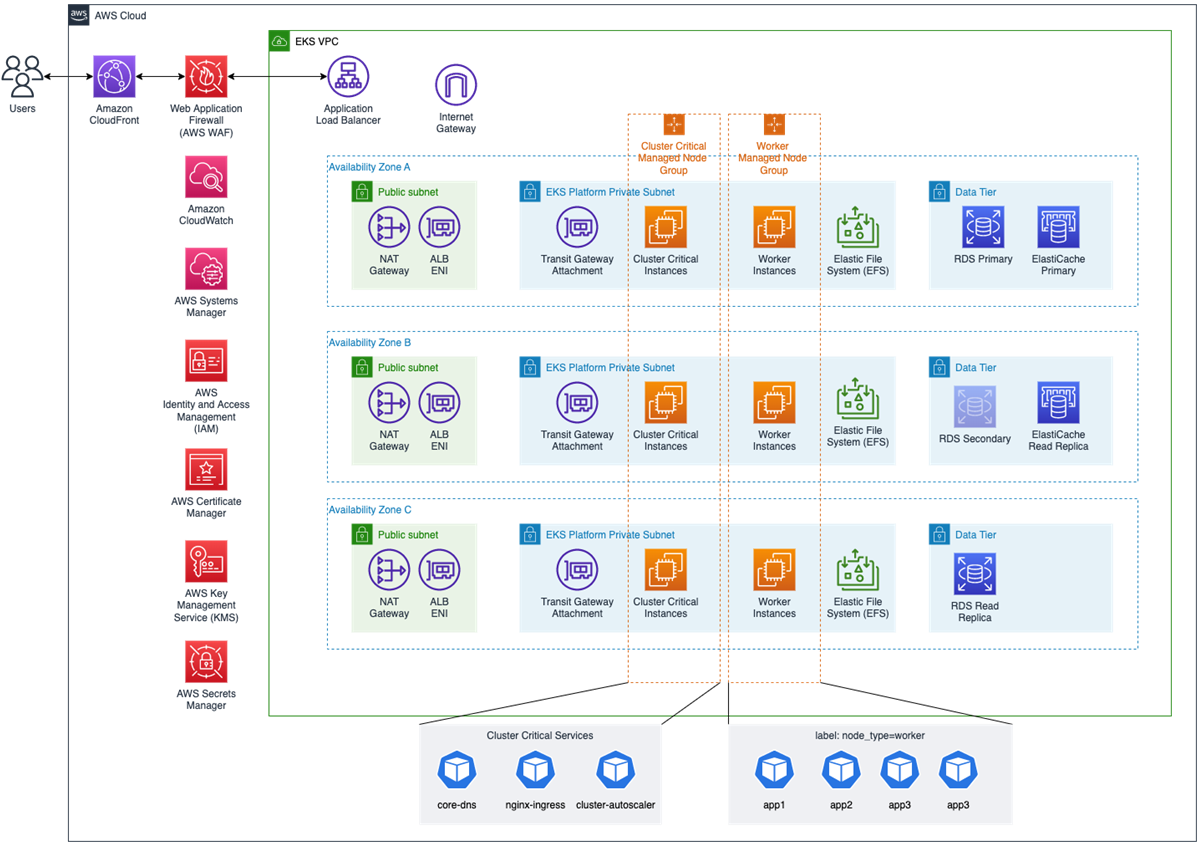
Figure 1 – SoftServe’s Application Modernization Platform solution architecture.
For the generic setup of Amazon EKS clusters, refer to the Amazon EKS Best Practices Guide. To get started, worker nodes are placed into private subnets with routes to network access translation (NAT) gateways in each AWS Availability Zone (AZ).
Data stores such as Amazon Relational Database Service (Amazon RDS) are placed in separate subnets to minimize dependencies with the worker nodes. Same with the other components that can be shared with the platform like Amazon ElastiCache.
The most important consideration for subnets is size to allow for the growth of the worker nodes and pods. The Amazon VPC CNI is used to provide networking for the pods and allows for native integration with the VPC IP range. The size and type of the worker node instances determine the maximum amount of IP addresses which can be allocated to pods; for example on an m6i.2xlarge instance with eight vCPU that allows for 58 pods.
Scalability due to the shortage of IPv4 addresses for EKS is critical; hence I also recommend to deploy the CNI metrics helper that in connection with Amazon CloudWatch can alert if the cluster is running out of IPs.
When configured for prefix assignment, the CNI add-on can assign significantly more IP addresses to a network interface than it can when assigned individual IP addresses. Amazon EKS also supports IPv6 in a single-mode setup, which is distinct from Kubernetes’ IPv4/IPv6 dual-stack feature to come across the problem of the IP address space shortage.
Application Load Balancer (ALB) provides access to the exposed services. By default, each ingress object in the Kubernetes manifest will result in an additional load balancer. We add an NGINX ingress controller to our configuration that can use a single ALB instead, which helps reduce cost but also simplifies ingress management by the development teams. An extra benefit of using ALB is direct integration with AWS WAF and AWS Certificate Manager.
Since most enterprise customers have comparably complex network setups—for example, through integration with on-premises locations and usage of multiple dedicated AWS accounts for development, test and, production environments—we also deploy AWS Transit Gateway to provide a single hub securely connecting all of the required networks, sometimes even across multiple AWS regions.
In addition to the network security aspect, we recommend using AWS Secrets Manager or AWS Systems Manager Parameter Store to store application secrets. In order to manage the clusters on AWS, we recommend using role-based access control (RBAC) in combination with AWS Identity and Access Management (IAM) or through OIDC configuration that can integrate with Active Directory.
For the pods consuming other AWS services (like Amazon S3 or Amazon SQS), we deploy IAM Roles for Service Accounts (IRSA) which allows containers to consume IAM roles without a need to provide any secret credentials. We always use Parameter Store to store global parameters (like URLs or basic connection strings) and Sessions Manager to be able to connect to the worker nodes in case of any problems.
For better support of stateful pods that require file-based access, we deploy the Amazon EFS CSI driver that allows mounting persistent volumes regardless of the worker node AZ placement, providing a more resilient and highly available solution to access the data.
For low latency or high local traffic requirements between pods, we recommend using appropriate placement groups.
Infrastructure Management
Provisioning and configuration of all the components described above can be a tedious and error-prone task. Making use of infrastructure as code (IaC) is also considered a best practice to mitigate potential errors.
Besides existing templates for this, such as eks-blueprints and eks-add-ons, SoftServe has created a library of predefined templates to speed up the deployment for customers. As we are deploying Kubernetes environments on multiple platforms, our templates are written in Terraform.
In enterprise organizations, where multiple teams are working on such a platform, it’s recommended to use a pipeline-based approach to orchestrate the required Terraform templates. Due to the nature of SoftServe’s business, we can support the majority of CI/CD solutions like Jenkins, CircleCI, GitLab CI, FluxCD, ArgoCD, or Terraform Cloud to deploy infrastructure from code.
We know from experience that maintaining infrastructure components takes precious time from IT employees and does not add a lot of value. Coming from on-premises environments, however, customers are used to provisioning and maintaining worker nodes by themselves.
Misconfiguration can cause misbehavior in self-managed instances. Additionally, with self-managed node groups, customers need to make sure the nodes are tagged correctly, the cluster-autoscaler has the right permissions, and the correct instance types are being used.
By using EKS-managed node groups, customers can reduce errors and time spent on such tasks. Managed node groups also orchestrate the draining of the pods during termination or updates to reduce workload disruption, and by supporting custom launch templates customers have control over the operating systems and node configurations.
Also, self-managed nodes require extra care to make sure the Amazon Machine Image (AMI) and kubelet versions are the same, otherwise it can raise concerns, as EKS version upgrades can bring changes (like removing some API calls or changing them) which result in kubelet not being able to communicate with the cluster.
Managed node groups simplify all of that, as AWS is taking care of all these tasks. Handling critical cluster components versions like core-dns is important to follow because they may not work with incompatible EKS versions. With self-managed nodes and self-managed cluster components, that task needs to be under control of the operations teams.
AWS recently released Karpenter, an open-source infrastructure scheduler and manager that allows you to optimize the capacity of EKS clusters and reduce costs. It allows for additional optimization compared to cluster-autoscaler and can be installed from kOps, Terraform, eksctl, or a Helm chart.
The major difference between cluster-autoscaler and Karpenter is that Karpenter automatically launches just the right compute resources to handle your cluster’s applications. Cluster-autoscaler, however, operates on a node group level. One particular assumption that cluster-autoscaler makes is that all the capacity within a node group has instances with the same number of vCPUs and Memory.
In a typical enterprise customer deployment, the infrastructure layer is managed by a dedicated team and the applications running on top are managed by individual teams. AWS Proton can help with the appropriate segregation of duties and automation between teams providing the platform and teams running the applications on top.
Cluster Services Fault Tolerance
There is a group of services that are crucial for all applications running in an EKS cluster; for example, core-dns or nginx-ingress, and kube-proxy. These critical services should be treated with care and always have enough resources to cope with the workloads running on the cluster, and they should ideally be placed on a dedicated node group.
Although customers can configure their worker nodes to handle any container load that’s needed and cluster-autoscaler will scale nodes depending on workload demand, there’s a risk involved that these critical components fail to operate properly because there were problems in getting the required resources at the right time.
Regardless of using managed worker groups or self-managed worker groups, we recommend using a dedicated node group for critical services and labelling it with a specific key-value pair, which later is used as nodeSelector in the deployment manifest or create appropriate taints and tolerations.
This node group is usually only a few small instances, as most of these services are not resource-intensive, but the risk of interference with other applications in the cluster is reduced. They need to be highly available, and you need to make sure they will always have a space to scale.
Application Management
After setting up the infrastructure layer properly, customers are good to go with a Kubernetes platform that is managed via code and configured for automatic scaling based on workload requirements, with a high degree of AWS-managed services removing the undifferentiated heavy-lifting from the infrastructure teams.
In this example, SoftServe’s deployments are managed by ArgoCD that comes with a number of features, from single sign-on (SSO) integration, web and command line interface (CLI) visualizations, continuous monitoring of deployed applications, and webhook integration with GitHub, GitLab, and BitBucket. It can also be integrated with most existing or new CI/CD pipelines.
Cost Management
Amazon EC2 Spot instances can save up to 90% of the cost compared to the On-Demand instance price. Spot instance termination notification is issued two minutes before the instance stops. If pods can handle this and finish or delegate the task to another group of pods, this architecture is a good fit for Spot instances. If the workload can be architected to handle the termination, run in any region and any Availability Zone, options to run it on EC2 Spot instances should be evaluated.
Additionally, AWS Fault Injection Simulator can be used to simulate Spot interruptions and test the application’s resiliency. Managed worker node groups can handle Spot termination and move workloads to non-Spot managed node groups.
Both managed node groups and Karpenter support Spot instances mixed in, and there is no more reason to have multiple separated groups that need to consist of On-Demand instances or Reserved Instances and others consisting of Spot instances.
Operations Management
With infrastructure and applications running on Amazon EKS, it’s time to establish good operations management practices. The first step is to train the customer teams on the AWS Shared Responsibility Model. This is an essential element of the customer’s operating model and helps increase resiliency for applications and platforms on top of AWS services.
Make sure that permissions are under control and the principle of least privileged is followed so the workloads can access only what they need. IAM roles for the service accounts and consuming AWS SDK allow for creating secure interface to either Systems Manager or Parameter Store and consume sensitive data on-demand, rather than being part of the pod environment runtime variables which significantly increases security.
Set the detective controls on the audit log and monitor for inappropriate access, and enable Amazon GuardDuty for EKS to detect unauthorized access, for example. Establish pod security checks in the CI/CD pipeline using tools like Snyk, or use Amazon Elastic Container Registry (Amazon ECR) to monitor and alert on findings linked with Amazon Inspector that can be deployed as an agent on the worker nodes.
Make sure the latest version of the OS and AMIs are used to avoid kubelet and Kubernetes cluster version mismatch. That can be achieved by creating an AWS Config custom rule to monitor compliance. Treat infrastructure as immutable and do not perform upgrades in place; rather, just recreate worker nodes. Constantly review pod limits and requests that can help with more optimized pod placement within the cluster that can turn into better cost optimization and sustainability.
Always make sure the right metrics are extracted and understood. Lastly, make sure the appropriate alerts are in place when the failure or anomaly is detected, and Amazon CloudWatch can help with that.
Conclusion
Setting up operating standards in the cloud and on premises can be challenging for enterprises. That’s why SoftServe proposes customers use as many AWS-managed services as possible to reduce management overhead and allow teams to focus on deploying new features, releasing more often, and increasing productivity.
SoftServe can help to adopt containers and Kubernetes by running a Containers Strategy or Containers Maturity Assessment to verify your current container strategy, and then accelerating this adoption by deploying its Application Modernization Platform which complies with best practices.
Special thanks to Sascha Moellering, Principal Container Specialist Solutions Architect – AWS
The content and opinions in this blog are those of the third-party author and AWS is not responsible for the content or accuracy of this post.
.

.
SoftServe – AWS Partner Spotlight
SoftServe is an AWS Premier Tier Services Partner and digital authority that implements repeatable end-to-end solutions through deep industry expertise.