AWS Big Data Blog
Author: Saurabh Bhutyani

Automate deployment of data and AI applications with Amazon SageMaker Unified Studio CI/CD CLI
The CI/CD CLI for Amazon SageMaker Unified Studio (aws-smus-cicd-cli) is an open source command line tool that automates deployment of multi-service data and AI applications across pipeline stages. Data teams define their application once in a YAML manifest, DevOps teams deploy with a single command, and the CLI handles configuration substitution, dependency ordering, and resource provisioning automatically. In this post, we walk through how the CI/CD CLI works, show you how to deploy a real application across environments, and demonstrate how it fits into your existing CI/CD workflows.

Use AWS Data Exchange to seamlessly share Apache Hudi datasets
Apache Hudi was originally developed by Uber in 2016 to bring to life a transactional data lake that could quickly and reliably absorb updates to support the massive growth of the company’s ride-sharing platform. Apache Hudi is now widely used to build very large-scale data lakes by many across the industry. Today, Hudi is the […]
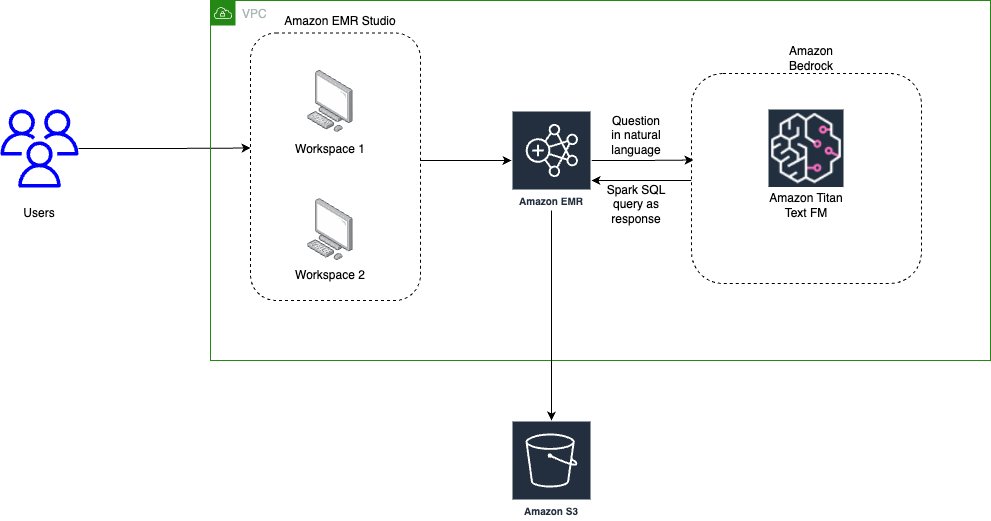
Use generative AI with Amazon EMR, Amazon Bedrock, and English SDK for Apache Spark to unlock insights
In this era of big data, organizations worldwide are constantly searching for innovative ways to extract value and insights from their vast datasets. Apache Spark offers the scalability and speed needed to process large amounts of data efficiently. Amazon EMR is the industry-leading cloud big data solution for petabyte-scale data processing, interactive analytics, and machine […]

Extend your data mesh with Amazon Athena and federated views
Amazon Athena is a serverless, interactive analytics service built on the Trino, PrestoDB, and Apache Spark open-source frameworks. You can use Athena to run SQL queries on petabytes of data stored on Amazon Simple Storage Service (Amazon S3) in widely used formats such as Parquet and open-table formats like Apache Iceberg, Apache Hudi, and Delta […]

Reduce costs and increase resource utilization of Apache Spark jobs on Kubernetes with Amazon EMR on Amazon EKS
Amazon EMR on Amazon EKS is a deployment option for Amazon EMR that allows you to run Apache Spark on Amazon Elastic Kubernetes Service (Amazon EKS). If you run open-source Apache Spark on Amazon EKS, you can now use Amazon EMR to automate provisioning and management, and run Apache Spark up to three times faster. […]

Migrating data from Google BigQuery to Amazon S3 using AWS Glue custom connectors
July, 2022: This post was reviewed and updated to include a mew data point on the effective runtime with the latest version, explaining Glue 3,0 and autoscaling. October, 2024: In Glue 4.0 we have introduced a native and managed connector for Google BigQuery. You can follow the instruction in the blog postUnlock scalable analytics with […]

Accessing and visualizing data from multiple data sources with Amazon Athena and Amazon QuickSight
Amazon Athena now supports federated query, a feature that allows you to query data in sources other than Amazon Simple Storage Service (Amazon S3). You can use federated queries in Athena to query the data in place or build pipelines that extract data from multiple data sources and store them in Amazon S3. With Athena […]

Redacting sensitive information with user-defined functions in Amazon Athena
Amazon Athena now supports user-defined functions (in Preview), a feature that enables you to write custom scalar functions and invoke them in SQL queries. Although Athena provides built-in functions, UDFs enable you to perform custom processing such as compressing and decompressing data, redacting sensitive data, or applying customized decryption. You can write your UDFs in […]

Extracting and joining data from multiple data sources with Athena Federated Query
With modern day architectures, it’s common to have data sitting in various data sources. We need proper tools and technologies across those sources to create meaningful insights from stored data. Amazon Athena is primarily used as an interactive query service that makes it easy to analyze unstructured, semi-structured, and structured data stored in Amazon Simple […]