Integración de Amazon Redshift para Apache Spark
Cree aplicaciones de Apache Spark que lean y escriban datos de Amazon Redshift
¿Por qué optar por la integración de Amazon Redshift para Apache Spark?

Beneficios de Amazon Redshift
-
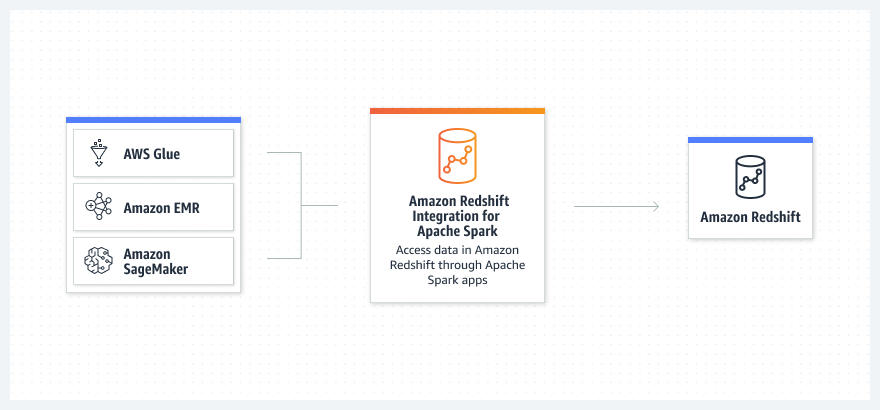
Amplíe la variedad de orígenes de datos que puede utilizar en sus aplicaciones de análisis y machine learning (ML) enriquecidas que se ejecutan en Amazon EMR, AWS Glue o SageMaker mediante la lectura de datos desde su almacenamiento de datos y la escritura de datos en este.
-
Optimice el proceso engorroso y, a menudo, manual de configurar conectores no certificados y controladores JDBC, y reduzca el tiempo de preparación para las tareas de análisis y ML.
-
Utilice las diferentes capacidades de inserción, como ordenar, agregar, limitar, unir y escalar funciones, de manera que solo se trasladen datos relevantes desde el almacenamiento de datos Amazon Redshift.
Funcionamiento
Casos de uso
-
Cree aplicaciones Apache Spark en Java, Scala y Python con los servicios de análisis de AWS basados en Apache Spark.
-
Lea datos desde Amazon Redshift y escríbalos en este con Amazon EMR, AWS Glue, SageMaker y los servicios de análisis y ML de AWS.
-
Utilice Amazon EMR o AWS Glue para obtener el código del marco de datos de su trabajo o cuaderno de Apache Spark y conectarse a Amazon Redshift.
-
Optimice su proceso sin instalación ni pruebas, con una seguridad mejorada (credenciales basadas en IAM) y pushdowns operativos y formato del archivo Parquet para el rendimiento.
Clientes
Corey Johnson,gerente de Arquitectura de Datos, Huron Consulting
Huron es una empresa de servicios profesionales globales que colabora con clientes para poner en práctica lo posible creando estrategias sólidas, optimizando las operaciones, acelerando la transformación digital e impulsando a empresas y al personal para alcanzar su propio futuro.
“Impulsamos a nuestros ingenieros para que creen sus canalizaciones y aplicaciones de datos con Apache Spark utilizando Python y Scala. Queríamos una solución personalizada que simplificara las operaciones y funcionara más rápido y de manera más eficiente para nuestros clientes, y eso es lo que obtuvimos con la nueva integración de Amazon Redshift para Apache Spark”.
Alcuin Weidus, arquitecto principal de datos sénior, GE Aerospace
GE Aerospace es un proveedor mundial de motores a reacción, componentes y sistemas para aeronaves comerciales y militares. La empresa ha estado diseñando, desarrollando y fabricando motores a reacción desde la Primera Guerra Mundial.
“GE Aerospace utiliza el análisis de AWS y Amazon Redshift para habilitar información comercial crucial que impulsa decisiones comerciales importantes. Con la compatibilidad de la copia automática de Amazon S3, podemos crear canalizaciones de datos más simples para trasladar datos de Amazon S3 a Amazon Redshift. Esto acelera la capacidad de nuestros equipos de productos de datos para acceder a los datos y brindar información a los usuarios finales. Dedicamos más tiempo a agregar valor a través de los datos y menos tiempo a las integraciones”.
Neema Raphael, Chief Data Officer, Goldman Sachs
Goldman Sachs Group, Inc.es una institución financiera líder mundial que brinda una amplia gama de servicios financieros en la banca de inversión, los valores, la administración de inversiones y la banca de consumo a una base de clientes grande y diversificada, que incluye corporaciones, instituciones financieras, gobiernos y personas.
“Nuestro objetivo es proporcionar acceso de autoservicio a los datos para todos nuestros usuarios en Goldman Sachs. A través de Legend, nuestra plataforma de administración y gobierno de datos de código abierto, permitimos a los usuarios desarrollar aplicaciones centradas en datos y obtener información basada en datos a medida que colaboramos en la industria de los servicios financieros. Con la integración de Amazon Redshift para Apache Spark, nuestro equipo de la plataforma de datos podrá acceder a los datos de Amazon Redshift con un mínimo de pasos manuales, lo que permitirá una ETL de código cero, que aumentará nuestra capacidad para facilitar que los ingenieros se centren en perfeccionar su flujo de trabajo a medida que recopilan información completa y oportuna. Esperamos ver una mejora en el rendimiento de las aplicaciones y una mayor seguridad, dado a que nuestros usuarios ahora pueden acceder con facilidad a los datos más recientes en Amazon Redshift”.
Recursos
¿Encontró lo que buscaba hoy?
Ayúdenos a mejorar la calidad del contenido de nuestras páginas compartiendo sus comentarios