¿Qué es la arquitectura de datos?
¿Qué es la arquitectura de datos?
La arquitectura de datos es el marco general que describe y rige la recopilación, la administración y el uso de datos de una organización. Hoy en día, las organizaciones tienen enormes volúmenes de datos que provienen de diversos orígenes, además de equipos dispares que desean acceder a esos datos a fin de utilizarlos con aplicaciones de análisis, machine learning o inteligencia artificial, entre otras. La arquitectura de datos moderna presenta un sistema cohesivo que hace que los datos sean accesibles y puedan utilizarse, al tiempo que garantiza su seguridad y calidad. Este sistema define las políticas, los modelos de datos, los procesos y las tecnologías que permiten a las organizaciones mover con facilidad los datos entre los departamentos y garantizar que estén disponibles siempre que sea necesario (incluido el acceso en tiempo real), al tiempo que respaldan plenamente el cumplimiento de las normativas.
¿Cuáles son los componentes de cualquier arquitectura de datos?
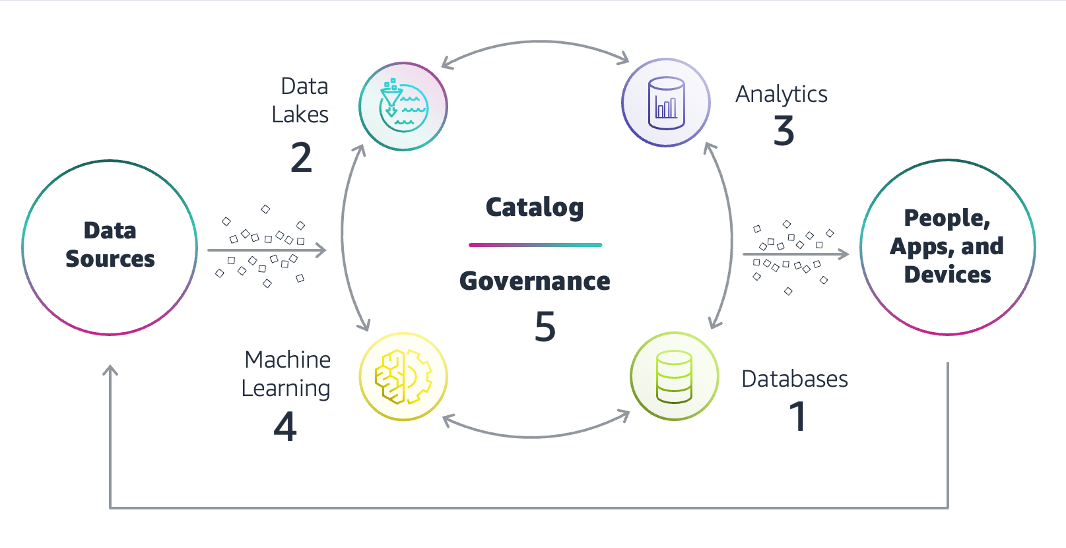
A continuación, se detallan los principales componentes de la arquitectura de datos.
Orígenes de datos
Los orígenes de datos pueden ser aplicaciones orientadas al cliente, sistemas de supervisión y telemetría, dispositivos de IoT y sensores inteligentes, aplicaciones que respaldan las operaciones comerciales, almacenes de conocimiento internos, archivos de datos, almacenes de datos de terceros y más. Tanto los datos estructurados como los no estructurados ingresan a la organización a diferentes velocidades, volúmenes y frecuencias.
Bases de datos
Los sistemas de bases de datos personalizadas son compatibles con aplicaciones modernas y sus diferentes características. Pueden ser relacionales o no relacionales; algunas almacenan datos como tablas estructuradas y otras almacenan tipos de datos no estructurados como documentos o pares clave-valor. Las bases de datos suelen almacenar datos específicos del dominio relacionados con un caso de uso limitado. Sin embargo, los datos se pueden usar más allá del sistema actual. Por ejemplo, los datos de una aplicación orientada al cliente se pueden usar para el análisis o la planificación de marketing y deben sacarse de la base de datos para su procesamiento. Del mismo modo, los datos procesados de otros lugares deben volver a cargarse en la base de datos de una aplicación de análisis o machine learning (ML).
Lagos de datos
Un lago de datos es un repositorio centralizado para el almacenamiento de datos sin procesar a escala. La arquitectura de datos describe cómo los datos se mueven desde diferentes bases de datos al lago de datos y de regreso a diferentes bases de datos según sea necesario para su uso. El lago de datos almacena los datos en un formato nativo o abierto, lo que permite formatear y limpiar antes de usarlos. Admite la integración de datos y desglosa los silos de datos dentro de una organización.
Análisis de datos
El componente de análisis de datos incluye almacenes de datos tradicionales, informes por lotes y tecnología de transmisión de datos para alertas e informes en tiempo real. Se pueden usar para consultas únicas y casos de uso de análisis avanzado. Los silos de datos no limitan los análisis porque la arquitectura de datos abre el acceso y permite que todos tengan más libertad para usar los activos de datos de la organización.
Inteligencia artificial
Las tecnologías de machine learning e inteligencia artificial son fundamentales para una estrategia de datos moderna que ayude a las organizaciones a predecir escenarios futuros e incorporar inteligencia a las aplicaciones. Los científicos de datos utilizan los datos de los lagos para experimentar, identificar casos de uso de inteligencia y entrenar nuevos modelos. Incluso después del entrenamiento, los modelos de IA requieren un acceso continuo a datos nuevos para generar resultados relevantes y útiles. Las arquitecturas de datos modernas incluyen toda la tecnología y la infraestructura que respaldan el entrenamiento y la inferencia de modelos de IA.
Gobernanza de datos
La gobernanza de datos determina las funciones, las responsabilidades y los estándares para el uso de los datos. Describe quién puede tomar qué medidas, con qué datos, utilizando qué métodos y en qué situaciones. Incluye la administración de la calidad y la seguridad de los datos. Los arquitectos de datos definen los procesos para auditar y realizar un seguimiento del uso de los datos para el cumplimiento continuado de las normativas.
La administración de metadatos es una parte integral de la gobernanza de datos. La arquitectura de datos incluye herramientas y políticas para almacenar y compartir metadatos. Describe los mecanismos para proporcionar un almacén de metadatos central en el que sistemas dispares puedan almacenar y detectar metadatos y usarlos para consultar y procesar más activos de datos.
¿Cómo se implementa la arquitectura de datos?
La implementación de la arquitectura de datos moderna en capas es una práctica recomendada. Las capas agrupan procesos y tecnologías en función de objetivos distintos. Los detalles de implementación son flexibles, pero las capas guían las elecciones en cuanto a tecnología y la forma en que deben integrarse.

Capa de preparación
La capa de preparación o staging es el punto de entrada de los datos dentro de la arquitectura. Gestiona la ingesta de datos sin procesar de varios orígenes, incluidos los formatos estructurados, semiestructurados y no estructurados. Quiere que esta capa sea lo más flexible posible.
Si el esquema (formatos y tipos de datos) se aplica de manera rígida en esta capa, los casos de uso posteriores se ven limitados. Por ejemplo, imponer todos los valores de fecha como un formato de mes, año limita los casos de uso futuros que requieren el formato dd/mm/aaaa. Al mismo tiempo, quiere que haya un poco de coherencia. Por ejemplo, si los números de teléfono se almacenan como cadenas y se utilizan como tales, pero otro origen de datos comienza a generar los mismos datos como valores numéricos, se interrumpe la canalización de datos.
Equilibrar la flexibilidad con la coherencia requiere dividir esta capa en dos subcapas.
Capa sin procesar
La capa sin procesar almacena los datos inalterados exactamente como llegan, de manera que conserva el formato y la estructura originales sin transformaciones. Es un repositorio empresarial para la exploración, auditoría y reproducibilidad de los datos. Los equipos pueden revisar y analizar los datos en su estado original cuando sea necesario, lo que garantiza la transparencia y la trazabilidad.
Capa estandarizada
La capa estandarizada prepara los datos sin procesar para su consumo mediante la aplicación de validaciones y transformaciones de acuerdo con estándares predefinidos. Por ejemplo, en esta capa, todos los números de teléfono se convertirían en cadenas, todos los valores de tiempo en formatos específicos, etc. De este modo, se convierte en la interfaz para que todos los usuarios de la organización accedan a datos estructurados y de calidad garantizada.
La capa estandarizada de la arquitectura de datos es crucial para hacer posible la inteligencia empresarial (BI) de autoservicio, el análisis de rutina y los flujos de trabajo de machine learning. Aplica los estándares del esquema y minimiza las interrupciones causadas por los cambios en el esquema.
Capa conformada
La integración de datos de diferentes orígenes se completa en la capa conformada. La capa crea un modelo de datos empresarial unificado en todos los dominios. Por ejemplo, los datos de los clientes pueden tener diferentes detalles en diferentes departamentos: las ventas capturan los detalles de los pedidos, las cuentas capturan el historial financiero y el marketing captura los intereses y la actividad en línea. La capa conformada crea una comprensión compartida de dichos datos en toda la organización. Las ventajas principales permiten hacer lo siguiente:
-
Definir de manera uniforme y unificada las entidades principales de toda la organización.
-
Cumplir las normas de seguridad y privacidad de los datos.
-
Equilibrar de forma flexible la uniformidad en toda la empresa con la personalización específica del dominio mediante patrones centralizados y distribuidos.
No se usa directamente para la inteligencia empresarial operativa, pero respalda el análisis exploratorio de datos, la inteligencia empresarial de autoservicio y el enriquecimiento de datos de dominios específicos.
Capa enriquecida
Esta capa transforma los datos de la capa anterior en conjuntos de datos denominados productos de datos, diseñados para casos de uso específicos. Los productos de datos pueden ir desde paneles operativos utilizados para la toma de decisiones diarias hasta perfiles de clientes detallados enriquecidos con recomendaciones personalizadas o información sobre cuál es la siguiente acción recomendada. Se alojan en varias bases de datos o aplicaciones elegidas en función del caso de uso específico.
Las organizaciones catalogan los productos de datos en sistemas de administración de datos centralizados para que otros equipos puedan detectarlos y acceder a ellos. Esto reduce la redundancia y garantiza que los datos enriquecidos y de alta calidad sean fácilmente accesibles.
¿Cuáles son los tipos de arquitecturas de datos?
Hay dos enfoques diferentes para la capa conformada que crean diferentes tipos de arquitectura de datos.
Arquitectura de datos centralizada
En las arquitecturas de datos centralizadas, la capa conformada se centra en crear y administrar entidades comunes, como la de un cliente o un producto, que se utilizan de forma universal en toda la empresa. Las entidades se definen con un conjunto limitado de atributos genéricos para una administración de datos más sencilla y una amplia aplicabilidad. Por ejemplo, una entidad cliente puede incluir atributos principales como el nombre, la edad, la profesión y la dirección.
Estas arquitecturas de datos admiten la gobernanza de datos centralizada, especialmente para la información confidencial, como la información de identificación personal (PII) o la información de tarjetas de pago (PCI). La administración centralizada de metadatos garantiza que los datos se cataloguen y controlen de manera eficaz, con controles de seguimiento del linaje y del ciclo de vida para garantizar la transparencia y la seguridad.
Sin embargo, este modelo evita incluir todos los atributos posibles, ya que la administración centralizada de los requisitos de datos complejos ralentiza la toma de decisiones y la innovación. En cambio, las propiedades específicas del dominio, como las impresiones de las campañas de los clientes (que solo son necesarias para el departamento de marketing), se obtienen en la capa enriquecida las respectivas unidades de negocio.
Las tecnologías de tejido de datos son útiles para implementar arquitecturas de datos centralizadas.
Arquitectura de datos distribuida
Cada dominio crea y administra su propia capa conformada en arquitecturas de datos distribuidas. Por ejemplo, el marketing se centra en atributos como los segmentos de clientes, las impresiones de las campañas y las conversiones, mientras que la contabilidad prioriza propiedades como los pedidos, los ingresos y los ingresos netos.
Las arquitecturas de datos distribuidas brindan flexibilidad a la hora de definir las entidades y sus propiedades, pero dan como resultado varios conjuntos de datos para entidades comunes. La capacidad de detección y la gobernanza de estos conjuntos de datos distribuidos se logran a través de un catálogo de metadatos central. Las partes interesadas pueden encontrar y usar el conjunto de datos apropiado mientras supervisan los procesos de intercambio de datos.
Las tecnologías de malla de datos son útiles para implementar arquitecturas de datos distribuidos.
¿Qué es un marco de arquitectura de datos?
Un marco de arquitectura de datos es un enfoque estructurado cuyo objetivo es el diseño de una arquitectura de datos. Proporciona un conjunto de principios, estándares, modelos y herramientas que garantizan procesos de administración de datos eficientes que están en consonancia con los objetivos comerciales de la organización. Puede considerarlo como un esquema estándar que un arquitecto de datos utiliza para crear arquitecturas de datos completas y de alta calidad.
Algunos ejemplos de marcos de arquitectura de datos incluyen
El marco DAMA-DMBOK
El marco Data Management Body of Knowledge (DAMA-DMBOK) describe las prácticas recomendadas, principios y procesos para una administración de datos eficaz a lo largo de su ciclo de vida. Permite establecer prácticas de administración de datos coherentes y, al mismo tiempo, garantiza que estas estén en consonancia con los objetivos empresariales. Al tratar los activos de datos como un recurso estratégico, DAMA-DMBOK proporciona una guía práctica para mejorar la toma de decisiones y la eficiencia operativa.
El marco de Zachman
El marco de Zachman es un marco de arquitectura empresarial que utiliza un formato matricial para definir las relaciones entre las diferentes perspectivas (como el propietario de la empresa, el diseñador y el creador) y seis interrogativos clave (qué, cómo, dónde, quién, cuándo y por qué). Las organizaciones pueden visualizar cómo se ajustan los datos a sus operaciones generales, lo que garantiza los procesos relacionados con los datos estén en consonancia con los objetivos empresariales y los requisitos del sistema. El marco de Zachman tiene un amplio reconocimiento debido a su capacidad para aportar claridad a las dependencias de los sistemas y los datos de toda la empresa.
TOGAF
El marco Open Group Architecture Framework (TOGAF) trata la arquitectura de datos como un componente fundamental de un sistema más amplio, y hace hincapié en la creación de modelos de datos, flujos de datos y estructuras de gobierno que respalden las necesidades de la organización. Establece procesos de datos estandarizados, lo que garantiza la interoperabilidad del sistema y una administración de datos eficiente. Es particularmente beneficioso para las grandes empresas que buscan alinear sus estrategias empresariales y de TI mediante un enfoque unificado.
¿Cómo se compara la arquitectura de datos con otros términos relacionados?
Las diferentes terminologías de datos parecen similares, pero tienen significados completamente diferentes. A continuación, se lo explicamos.
La arquitectura de datos frente a la arquitectura de la información
La arquitectura de la información es la organización y presentación de la información a los usuarios finales. El término se aplica a las interfaces de usuario, los sitios web o los sistemas de contenido y se refiere a la accesibilidad de la información por parte del usuario final. Los principios y las herramientas de la arquitectura de la información se centran en la navegación, la categorización y la capacidad de búsqueda, por ejemplo, dentro de un almacén de conocimientos en línea o una base de datos de documentos.
Por el contrario, la arquitectura de datos se centra en el diseño y la administración de todos los datos de la organización. Se ocupa de toda la infraestructura de datos técnicos del backend, mientras que la arquitectura de la información únicamente se centra en la forma en que los usuarios finales interactúan con la información y la interpretan.
La arquitectura de datos en comparación con la ingeniería de datos
La ingeniería de datos es la implementación práctica de la arquitectura de datos. Los arquitectos de datos proporcionan un plan de alto nivel para administrar los activos de datos de una organización. Diseñan sistemas de datos escalables en consonancia con los objetivos empresariales y las políticas de seguridad. Los ingenieros de datos implementan el plan: crean, mantienen y optimizan las canalizaciones de datos. Garantizan que los datos se ingieran, limpien, transformen y entreguen para su análisis de acuerdo con las reglas de la arquitectura de datos.
La arquitectura de datos en comparación con el modelado de datos
El modelado de datos es un proceso dentro de la arquitectura de datos que crea una representación visual de cualquier recopilación de datos. Incluye la creación de modelos de datos conceptuales, lógicos y físicos que describan los datos de la colección. Un modelo de datos lógicos representa de manera esquemática las restricciones de datos, los nombres de las entidades y las relaciones para su implementación de forma independiente de la plataforma. Un modelo de datos físico perfecciona aún más el modelo de datos lógico para su implementación en una tecnología de datos específica.
La arquitectura de datos tiene un alcance mucho más amplio, que va más allá del modelado de datos. Más allá de los atributos y las relaciones de los datos, también define una estrategia más amplia para la administración de datos en toda la organización. Incluye infraestructura, políticas y tecnologías para la integración de datos que están en consonancia con los objetivos de la organización.
¿Cómo puede AWS satisfacer sus requisitos de arquitectura de datos?
AWS proporciona un conjunto completo de servicios de análisis para cada capa de su arquitectura de datos, desde el almacenamiento y la administración hasta la gobernanza de datos y la inteligencia artificial. AWS ofrece servicios diseñados específicamente con la mejor relación entre precio y rendimiento, escalabilidad y el costo más bajo. Por ejemplo,
- Las bases de datos de AWS incluyen más de 15 servicios de bases de datos diseñados específicamente para admitir diversos modelos de datos relacionales y no relacionales.
- Los lagos de datos de AWS incluyen servicios que proporcionan almacenamiento ilimitado de datos sin procesar y crean lagos de datos seguros en cuestión de días en lugar de meses.
- La integración de datos con AWS incluye servicios que reúnen datos de varias fuentes para que pueda transformar, operar y administrar los datos en toda su organización.
AWS Well-Architected ayuda a los arquitectos de datos en la nube a crear una infraestructura segura, de alto rendimiento, resiliente y eficiente. El Centro de arquitectura de AWS incluye directrices basadas en casos de uso para implementar varias arquitecturas de datos modernas en su organización.
Comience con la arquitectura de datos en AWS creando una cuenta gratuita hoy mismo.
Siguientes pasos en AWS
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages