¿Qué son las incrustaciones en el machine learning?
¿Qué son las incrustaciones en el machine learning?
Las incrustaciones son representaciones numéricas de objetos del mundo real que los sistemas de aprendizaje automático (ML) e inteligencia artificial (IA) utilizan para comprender dominios de conocimiento complejos como lo hacen los humanos. Por ejemplo, los algoritmos informáticos entienden que la diferencia entre 2 y 3 es 1, lo que indica una relación cercana entre 2 y 3 en comparación con 2 y 100. Sin embargo, los datos del mundo real incluyen relaciones más complejas. Por ejemplo, un nido de aves y la guarida de un león son pares análogos, mientras que el día y la noche son términos opuestos. Las incrustaciones convierten los objetos del mundo real en representaciones matemáticas complejas que capturan las propiedades y relaciones inherentes entre los datos del mundo real. Todo el proceso está automatizado, y los sistemas de IA crean las incrustaciones automáticamente durante el entrenamiento y las utilizan según sea necesario para completar nuevas tareas.
¿Por qué son importantes las incrustaciones?
Las incrustaciones permiten que los modelos de aprendizaje profundo entiendan los dominios de datos del mundo real de manera más eficaz. Simplifican la forma en que se representan los datos del mundo real y, al mismo tiempo, conservan las relaciones semánticas y sintácticas. Esto permite que los algoritmos de machine learning extraigan y procesen tipos de datos complejos y habiliten aplicaciones de IA innovadoras. En las siguientes secciones se describen algunos factores importantes.
Reducir la dimensionalidad de los datos
Los científicos de datos utilizan incrustaciones para representar datos de alta dimensión dentro de un espacio de baja dimensión. En la ciencia de datos, por lo general, el término dimensión se refiere a una característica o atributo de los datos. En la IA, los datos de dimensiones superiores se refieren a conjuntos de datos con muchas características o atributos que definen cada punto de datos. Esto puede significar decenas, cientos o incluso miles de dimensiones. Por ejemplo, una imagen puede considerarse un dato de alta dimensión porque cada valor de color de píxel es una dimensión independiente.
Cuando se presentan con datos de alta dimensión, los modelos de aprendizaje profundo requieren más potencia informática y tiempo para aprender, analizar e inferir con precisión. Las incrustaciones reducen la cantidad de dimensiones al identificar los puntos en común y los patrones entre varias características. En consecuencia, esto reduce los recursos informáticos y el tiempo necesario para procesar los datos en bruto.
Entrenar modelos de lenguaje de gran tamaño
Las incrustaciones mejoran la calidad de los datos al entrenar modelos lingüísticos de gran tamaño (LLM). Por ejemplo, los científicos de datos utilizan incrustaciones para limpiar los datos de entrenamiento de las irregularidades que afectan al aprendizaje de los modelos. Los ingenieros de ML también pueden reutilizar modelos previamente entrenados al añadir nuevas incorporaciones para transferir el aprendizaje, lo que requiere perfeccionar el modelo fundamental con nuevos conjuntos de datos. Con las incrustaciones, los ingenieros pueden ajustar un modelo para conjuntos de datos personalizados del mundo real.
Cree aplicaciones innovadoras
Las incrustaciones permiten nuevas aplicaciones de aprendizaje profundo e inteligencia artificial generativa (IA generativa). Las diferentes técnicas de integración aplicadas en la arquitectura de redes neuronales permiten desarrollar, entrenar e implementar modelos de IA precisos en diversos campos y aplicaciones. Por ejemplo:
- Con las incrustaciones de imágenes, los ingenieros pueden crear aplicaciones de visión artificial de alta precisión para detectar objetos, reconocer imágenes y otras tareas relacionadas con la visualización.
- Con las incrustaciones de palabras, el software de procesamiento del lenguaje natural puede comprender con mayor precisión el contexto y las relaciones de las palabras.
- Las incrustaciones gráficas extraen y clasifican la información relacionada de los nodos interconectados para respaldar el análisis de redes.
Los modelos de visión artificial, los chatbots de IA y los sistemas de recomendación de IA utilizan integraciones para completar tareas complejas que imitan la inteligencia humana.
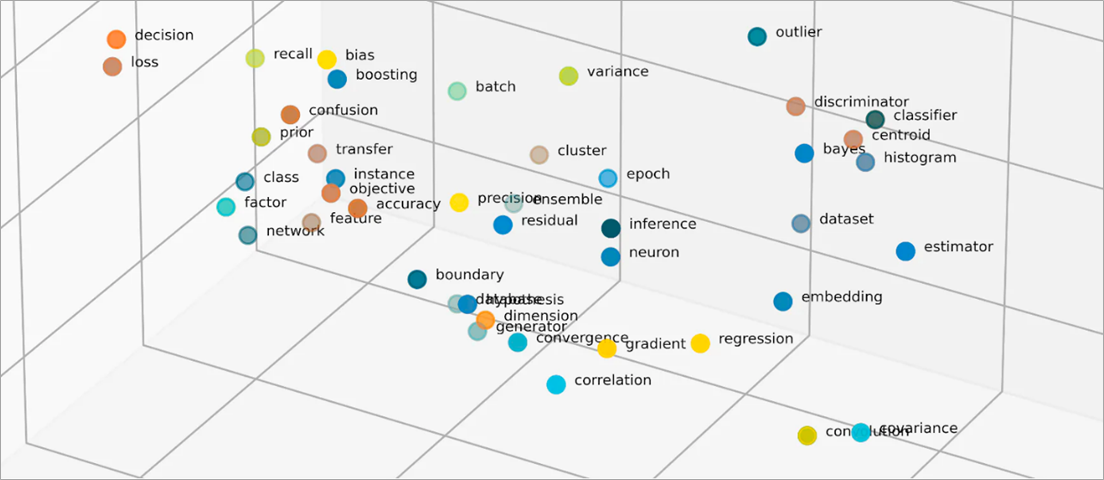
¿Qué son los vectores en las incrustaciones?
Los modelos de ML no pueden interpretar la información de manera inteligible en su formato bruto y requieren datos numéricos como entrada. Utilizan incrustaciones de redes neuronales para convertir información de palabras reales en representaciones numéricas llamadas vectores. Los vectores son valores numéricos que representan información en un espacio multidimensional. Ayudan a los modelos de ML a encontrar similitudes entre los elementos distribuidos de forma dispersa.
Cada objeto del que aprende un modelo de ML tiene varias características o funciones. Como un ejemplo sencillo, considere las siguientes películas y programas de televisión. Cada uno se caracteriza por el género, el tipo y el año de lanzamiento.
La conferencia (terror, 2023, película)
Upload (Comedia, 2023, Serie de TV, Temporada 3)
Cuentos de la cripta (terror, 1989, serie de televisión, temporada 7)
El escenario de ensueño (comedia de terror, 2023, película)
Los modelos de ML pueden interpretar variables numéricas, como los años, pero no pueden comparar variables no numéricas como el género, los tipos, los episodios y el total de las temporadas. Los vectores incrustados codifican datos no numéricos en una serie de valores que los modelos de ML pueden comprender y relacionar. Por ejemplo, la siguiente es una representación hipotética de los programas de televisión listados con anterioridad.
La conferencia (1.2, 2023, 20.0)
Upload (2.3, 2023, 35.5)
Cuentos de la cripta (1.2, 1989, 36.7)
El escenario de ensueños (1.8, 2023, 20.0)
El primer número del vector corresponde a un género específico. Un modelo de ML descubriría que La conferencia y Cuentos de la cripta comparten el mismo género. Del mismo modo, el modelo encontrará más similitudes entre Upload y Cuentos de la cripta basándose en el tercer número, el cual representa el formato, las temporadas y los episodios. A medida que se introducen más variables, se puede perfeccionar el modelo para condensar más información en un espacio vectorial más pequeño.
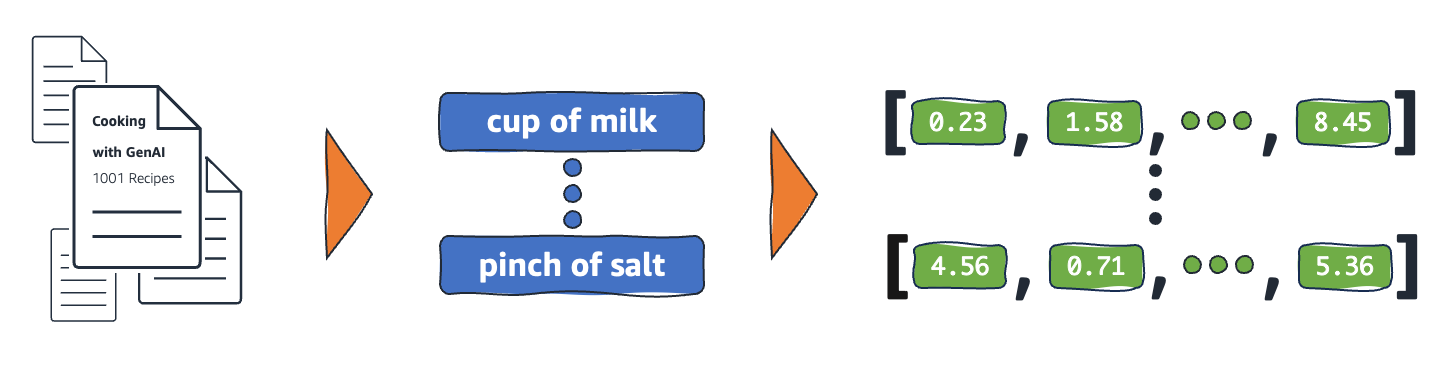
¿Cómo funcionan las incrustaciones?
Las incrustaciones convierten los datos brutos en valores continuos que los modelos de ML pueden interpretar. De forma convencional, los modelos de ML utilizan la codificación one-hot para diseñar variables categóricas en formas de las que pueden aprender. El método de codificación divide cada categoría en filas y columnas y les asigna valores binarios. Tenga en cuenta las siguientes categorías de productos y su precio.
|
Frutas |
Precio |
|
Apple |
5,00 |
|
Orange |
7,00 |
|
Zanahoria |
10,00 |
La representación de los valores con codificación one-hot da como resultado la siguiente tabla.
|
Apple |
Orange |
Pera |
Precio |
|
1 |
0 |
0 |
5,00 |
|
0 |
1 |
0 |
7,00 |
|
0 |
0 |
1 |
10,00 |
La tabla se representa de forma matemática como los vectores [1,0,0,5.00], [0,1,0,7.00] y [0,0,1,10.00].
La codificación one-hot amplía los valores dimensionales de 0 y 1 sin proporcionar información que ayude a los modelos a relacionar los diferentes objetos. Por ejemplo, el modelo no puede encontrar similitudes entre la manzana y la naranja a pesar de ser frutas, ni puede diferenciar la naranja y la zanahoria como frutas y verduras. A medida que se agregan más categorías a la lista, la codificación produce variables distribuidas de forma dispersa con muchos valores vacíos que consumen mucho espacio en la memoria.
Las incrustaciones vectorizan objetos en un espacio de baja dimensión al representar similitudes entre objetos con valores numéricos. Las incrustaciones de redes neuronales garantizan que la cantidad de dimensiones siga siendo manejable con la expansión de las características de entrada. Las características de entrada son rasgos de objetos específicos que un algoritmo de ML tiene la tarea de analizar. La reducción de la dimensionalidad permite que las incrustaciones retengan la información que los modelos de ML utilizan para encontrar similitudes y diferencias entre los datos de entrada. Los científicos de datos también pueden visualizar incrustaciones en un espacio bidimensional para comprender mejor las relaciones entre los objetos distribuidos.
¿Qué son los modelos de incrustación?
Los modelos de incrustación son algoritmos entrenados para encapsular información en representaciones densas en un espacio multidimensional. Los científicos de datos utilizan modelos de incrustación para permitir que los modelos de ML comprendan y razonen con datos de alta dimensión. Estos son modelos de incrustación comunes que se utilizan en las aplicaciones de ML.
Análisis de componente de entidad principal
El análisis de componente de entidad principal (PCA) es una técnica de reducción de dimensionalidad que reduce los tipos de datos complejos a vectores de baja dimensión. Busca puntos de datos con similitudes y los comprime en vectores incrustados que reflejan los datos originales. Aunque el PCA les permite a los modelos procesar los datos brutos con mayor eficacia, puede producirse una pérdida de información durante el procesamiento.
Descomposición de valores singulares
La descomposición de valores singulares (SVD) es un modelo de incrustación que transforma una matriz en sus matrices singulares. Las matrices resultantes retienen la información original al mismo tiempo que permiten que los modelos comprendan mejor las relaciones semánticas de los datos que representan. Los científicos de datos utilizan SVD para llevar a cabo diversas tareas de ML, como la compresión de imágenes, la clasificación de texto y la recomendación.
Word2Vec
Word2Vec es un algoritmo de ML entrenado para asociar palabras y representarlas en el espacio de incrustación. Los científicos de datos alimentan el modelo Word2Vec con conjuntos de datos textuales masivos para permitir la comprensión del lenguaje natural. El modelo encuentra similitudes en las palabras tras considerar su contexto y sus relaciones semánticas.
Hay dos variantes de Word2Vec: Continuous Bag of Words (CBOW) y Skip-gram. El CBOW permite al modelo predecir una palabra a partir de un contexto dado, mientras que Skip-gram deriva el contexto de una palabra determinada. Aunque Word2Vec es una técnica eficaz de incrustación de palabras, no puede distinguir con precisión las diferencias contextuales de una misma palabra que se utiliza para implicar significados diferentes.
BERT
BERT es un modelo de lenguaje basado en transformadores y entrenado con conjuntos de datos masivos para comprender los lenguajes como lo hacen los humanos. Al igual que Word2Vec, BERT puede crear incrustaciones de palabras a partir de los datos de entrada con los que se entrenó. Asimismo, BERT puede diferenciar los significados contextuales de las palabras cuando se aplica a diferentes frases. Por ejemplo, BERT crea diferentes incrustaciones para “jugar”, como en “Fui a una obra” y “Me gusta jugar”.
¿Cómo se crean las incrustaciones?
Los ingenieros utilizan redes neuronales para crear incrustaciones. Las redes neuronales constan de capas neuronales ocultas que toman decisiones complejas de forma iterativa. Al crear incrustaciones, una de las capas ocultas aprende a factorizar las características de entrada en vectores. Esto ocurre antes de las capas de procesamiento de características. Los ingenieros supervisan y guían este proceso con los siguientes pasos:
- Los ingenieros alimentan la red neuronal con algunas muestras vectorizadas preparadas manualmente.
- La red neuronal aprende de los patrones descubiertos en la muestra y usa el conocimiento para hacer predicciones precisas a partir de datos invisibles.
- Ocasionalmente, es posible que los ingenieros necesiten ajustar el modelo para garantizar que distribuya las características de entrada en el espacio dimensional apropiado.
- Con el tiempo, las incrustaciones funcionan de forma independiente, lo que permite a los modelos de ML generar recomendaciones a partir de las representaciones vectorizadas.
- Los ingenieros siguen monitoreando el rendimiento de la incrustación y realizando ajustes con los nuevos datos.
¿Cómo puede ayudarle AWS con sus requisitos de incrustación?
Amazon Bedrock es un servicio totalmente gestionado que ofrece una selección de modelos básicos (FM) de alto rendimiento de las principales empresas de IA, junto con un amplio conjunto de funciones para crear aplicaciones de inteligencia artificial generativa (IA generativa). Amazon Nova es una nueva generación de modelos básicos (FM) de última generación (SOTA) que ofrecen inteligencia de vanguardia y una relación precio-rendimiento líder en el sector. Son modelos potentes de uso general diseñados para soportar una variedad de casos de uso. Utilícelos tal como son o personalícelos con sus datos propios.
Titan Embeddings es un LLM que traduce texto en una representación numérica. El modelo Titan Embeddings admite la recuperación de textos, la similitud semántica y la agrupación en clústeres. El texto de entrada máximo es de 8K tokens y la longitud máxima del vector de salida es de 1536.
Los equipos de aprendizaje automático también pueden usar Amazon SageMaker para crear incrustaciones. Amazon SageMaker es un centro en el que puede crear, entrenar e implementar modelos de ML en un entorno seguro y escalable. Proporciona una técnica de incrustación llamada Object2Vec, con la que los ingenieros pueden vectorizar datos de alta dimensión en un espacio de baja dimensión. Puede utilizar las incrustaciones aprendidas para calcular las relaciones entre los objetos para tareas posteriores, como las clasificaciones y la regresión.
Cree una cuenta hoy mismo para comenzar con las incrustaciones en AWS.
Siguientes pasos en AWS
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages