Basis Pengetahuan Amazon Bedrock
Dengan Basis Pengetahuan Amazon Bedrock, Anda dapat memberikan informasi kontekstual kepada model fondasi dan agen dari sumber data perusahaan Anda sendiri guna memberikan respons yang lebih relevan, akurat, dan disesuaikan
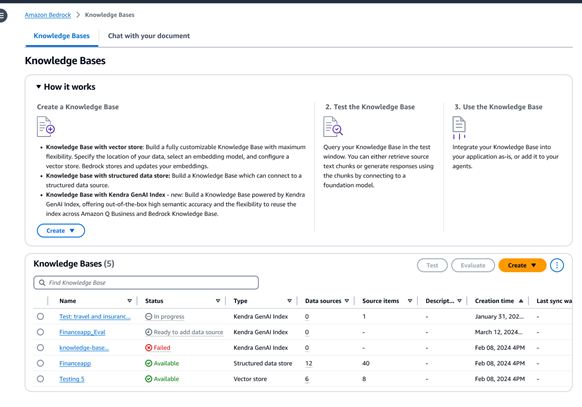
Dukungan terkelola penuh untuk alur kerja RAG menyeluruh
Untuk melengkapi model fondasi (FM) dengan informasi terkini dan milik sendiri, organisasi menggunakan Retrieval Augmented Generation (RAG), yaitu sebuah teknik mengambil data dari sumber data perusahaan dan memperkaya prompt untuk memberikan respons yang lebih relevan serta akurat. Basis Pengetahuan Amazon Bedrock adalah kemampuan terkelola sepenuhnya dengan manajemen konteks sesi dan atribusi sumber bawaan yang membantu Anda mengimplementasikan seluruh alur kerja RAG, mulai dari penyerapan hingga pengambilan dan augmentasi prompt tanpa harus membangun integrasi kustom ke sumber data dan mengelola alur data. Anda juga dapat mengajukan pertanyaan dan meringkas data dari satu dokumen, tanpa menyiapkan basis data vektor. Jika data Anda berisi sumber terstruktur, Basis Pengetahuan Amazon Bedrock menyediakan solusi terkelola bawaan yang mengubah bahasa alami ke bahasa kueri terstruktur untuk membuat perintah kueri pengambilan data, tanpa harus memindahkannya ke penyimpanan lain.
Hubungkan FM dan agen ke sumber data dengan aman
Jika Anda memiliki sumber data tidak terstruktur, Basis Pengetahuan Amazon Bedrock secara otomatis mengambil data dari sumber-sumber seperti Amazon Simple Storage Service (Amazon S3), serta Confluence, Salesforce, SharePoint, atau Web Crawler, dalam pratinjau. Selain itu, Anda juga menerima penyerapan dokumen terprogram agar pelanggan dapat menyerap data streaming atau data dari sumber yang tidak didukung. Setelah konten diserap, Basis Pengetahuan Amazon Bedrock mengubahnya menjadi beberapa blok teks, teks menjadi sematan, dan menyimpan sematan dalam basis data vektor Anda. Anda dapat memilih dari beberapa penyimpanan vektor yang didukung, termasuk Amazon Aurora, Amazon OpenSearch Nirserver, Analitik Amazon Neptune, MongoDB, Pinecone, dan Redis Enterprise Cloud. Anda juga dapat memilih untuk terhubung ke indeks pencarian hibrida Amazon Kendra untuk pengambilan terkelola.
Dengan Basis Pengetahuan Amazon Bedrock, Anda juga dapat terhubung ke penyimpanan data terstruktur untuk menghasilkan respons yang berdasarkan data. Hal ini dapat sangat berguna terutama jika Anda memiliki sumber data seperti detail transaksional yang disimpan di gudang data dan danau data. Basis Pengetahuan Amazon Bedrock menggunakan Bahasa Alami ke SQL untuk mengubah kueri ke perintah SQL dan menjalankan perintah untuk mengambil data, tanpa perlu memindahkannya dari sumber Anda.
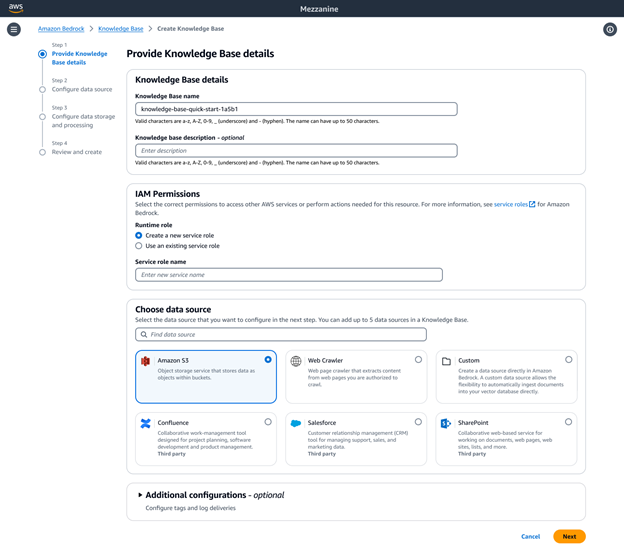
Kustomisasikan Basis Pengetahuan Amazon Bedrock untuk memberikan respons yang akurat saat runtime
Dengan Basis Pengetahuan Amazon Bedrock sebagai solusi RAG terkelola penuh, Anda memiliki fleksibilitas untuk menyesuaikan dan meningkatkan akurasi pengambilan data. Untuk sumber data tidak terstruktur yang berisi data multimodal, seperti gambar dan dokumen yang kaya visual dengan tata letak yang kompleks (misalnya, dokumen yang berisi tabel, gambar, bagan, dan diagram), Anda dapat mengonfigurasi Basis Pengetahuan untuk mengurai, menganalisis, dan mengekstrak wawasan yang bermakna. Anda dapat memilih Otomatisasi Data Bedrock atau model fondasi sebagai pengurai. Hal ini memungkinkan pemrosesan data multimodal kompleks yang lancar, sehingga Anda dapat membangun aplikasi GenAI dengan tingkat akurasi tinggi.
Basis Pengetahuan Amazon Bedrock menawarkan berbagai opsi pembagian data tingkat lanjut, termasuk pembagian berdasarkan semantik, hierarki, dan ukuran tetap. Untuk kontrol penuh, Anda dapat menulis kode pembagian sendiri sebagai fungsi Lambda, dan bahkan menggunakan komponen yang sudah tersedia dari kerangka kerja seperti LangChain dan LlamaIndex. Jika Anda memilih Analitik Amazon Neptune sebagai penyimpanan vektor, Basis Pengetahuan Amazon Bedrock secara otomatis membuat sematan, serta grafik yang menautkan konten terkait di seluruh sumber data Anda. Basis Pengetahuan Bedrock memanfaatkan hubungan konten ini dengan GraphRAG untuk meningkatkan akurasi pengambilan data sehingga dapat memberikan respons yang lebih komprehensif, relevan, dan dapat dijelaskan kepada pengguna akhir.
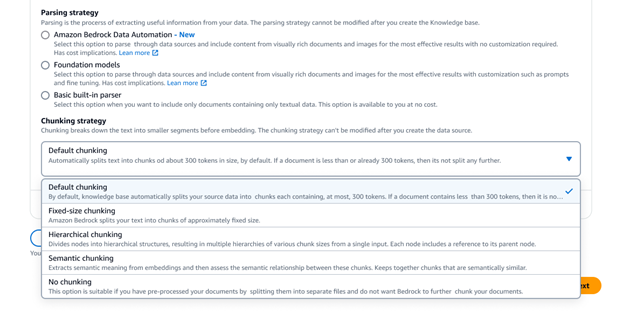
Ambil data dan lengkapi prompt
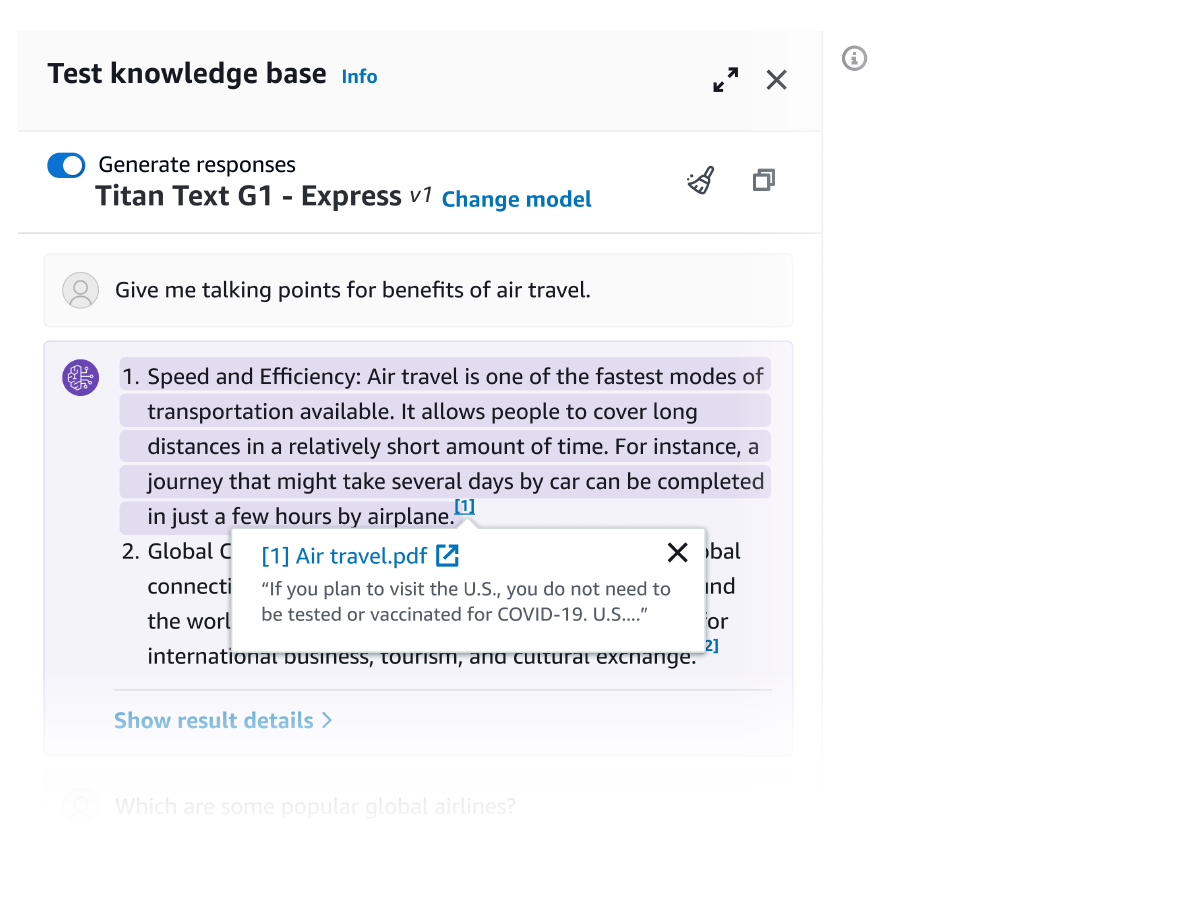
Menggunakan API Retrieve, Anda dapat mengambil hasil yang relevan untuk mengueri pengguna dari basis pengetahuan, termasuk elemen visual, seperti gambar, diagram, grafik, tabel, konten audio dan video, atau data terstruktur dari basis data jika tersedia. API RetrieveAndGenerate memiliki proses yang lebih canggih dengan langsung menggunakan hasil multimodal yang diambil untuk melengkapi prompt FM dan mengembalikan responsnya. Anda juga dapat menyediakan filter atau menggunakan FM untuk membuat filter implisit guna membatasi hasil yang ditampilkan sehingga hanya menyediakan konten yang relevan. Basis Pengetahuan Amazon Bedrock menawarkan model reranker untuk meningkatkan relevansi potongan dokumen yang diambil di seluruh konten teks, visual, dan multimedia.
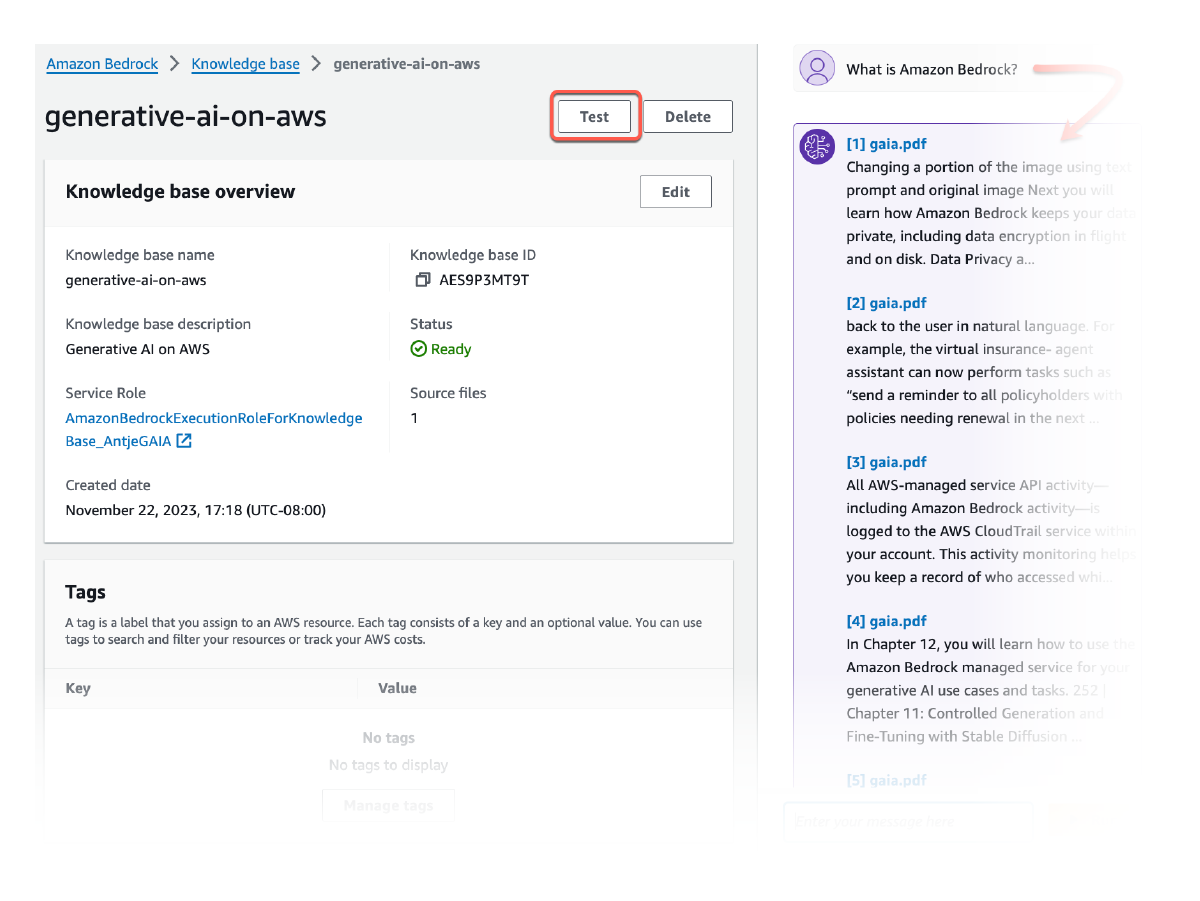
Sertakan atribusi sumber
Semua informasi yang diambil dari Basis Pengetahuan Amazon Bedrock dilengkapi dengan kutipan (yang juga menyertakan visual) untuk meningkatkan transparansi dan meminimalkan halusinasi.
Cara memulai
Apakah Anda sudah menemukan yang Anda cari?
Beri tahu kami agar kami dapat meningkatkan kualitas konten di halaman kami