Apa Perbedaan Antara Cassandra dan HBase?
Apa perbedaan antara Cassandra dan HBase?
Apache Cassandra dan Apache HBase adalah dua basis data NoSQL yang menyimpan data dalam format non-tabular. Keduanya menyimpan data sebagai penyimpanan nilai kunci pada infrastruktur big data untuk mengelola volume data besar secara akurat dan efisien. Namun, keduanya memiliki perbedaan arsitektur yang lebih sesuai dengan kasus penggunaan yang berbeda. Misalnya, Cassandra menyediakan performa baca dan tulis yang cepat, dan HBase menyediakan konsistensi data yang lebih besar. HBase juga lebih efektif untuk menangani set data yang besar dan jarang. Organisasi menggunakan Cassandra dan HBase untuk kasus penggunaan big data yang berbeda.
Kesamaan: Cassandra dan HBase
Cassandra dan HBase adalah dua database NoSQL yang dapat menyimpan, memproses, dan mengambil miliaran dataset. Cassandra dan HBase memiliki kesamaan yang tumpang tindih di bidang-bidang berikut.
Aplikasi big data
Anda dapat menyimpan data non-relasional tidak terstruktur dalam volume besar dengan Cassandra dan HBase. Cassandra dan HBase berbeda dari sistem basis data tradisional, yang menyimpan data dalam baris kolom sederhana. Anda dapat menggunakan Cassandra dan HBase untuk menyimpan gambar, audio, video, dan tipe data tidak terstruktur lainnya untuk pemrosesan skala besar.
Sumber terbuka
Apache Software Foundation menerbitkan dan mengelola Cassandra dan HBase sebagai proyek sumber terbuka. HBase dikembangkan dari konsep yang diperkenalkan oleh Google BigTable dan dirilis secara publik oleh Apache pada tahun 2008. Cassandra adalah inisiatif yang dibuat untuk memecahkan masalah pencarian kotak masuk Facebook. HBase menggunakan fitur khusus BigTable dan lainnya dari Amazon Dynamo.
Skalabilitas
Anda dapat menskalakan HBase untuk memenuhi permintaan data yang terus meningkat dengan menambahkan lebih banyak server wilayah ke klaster HBase. Sistem basis data NoSQL kemudian dapat mendistribusikan simpul data ke wilayah baru jika melebihi kapasitas tertentu. Klaster Cassandra juga dapat mendukung banyak simpul untuk menskalakan kemampuan manajemen datanya. Dengan menambahkan lebih banyak simpul, Anda dapat mendistribusikan data secara efektif dan merata serta mencegah kemacetan lalu lintas.
Pemulihan data
Simpul data di Cassandra dan HBase toleran terhadap kesalahan. Di Cassandra, setiap simpul mendukung replikasi data. Operasi tulis secara otomatis dikeluarkan untuk semua simpul yang ditetapkan ke data tertentu. HBase memiliki pendekatan duplikasi data serupa, yang diotomatiskan oleh Hadoop Distributed File System (HDFS) yang dijalankannya. HDFS membuat dan mempertahankan duplikat data di server yang berbeda. Kedua basis data NoSQL ini menduplikasi simpul data dalam jaringan fisik yang berbeda berdasarkan faktor replikasi untuk mengurangi risiko kegagalan di seluruh jaringan.
Jalur tulis
Baik Cassandra maupun HBase mengatur data ke dalam kolom. Saat menyimpan data, setiap basis data mencari kelompok kolom yang sesuai, yang menyimpan informasi terkait bersama-sama. Kedua basis data ini juga menulis data ke file log saat basis data menambahkan atau menyimpannya ke kolom.
Perbedaan arsitektur: Cassandra vs. HBase
Cassandra dan HBase beroperasi dengan karakteristik yang berbeda dari teorema CAP. Teorema CAP menetapkan bahwa sistem terdistribusi dapat memiliki dua sifat berikut pada waktu tertentu:
- Konsistensi
- Ketersediaan
- Toleransi partisi
Karena toleransi partisi wajib untuk basis data yang menyimpan set data besar, Cassandra dan HBase memiliki perbedaan dalam ketersediaan dan konsistensi. Cassandra memiliki ketersediaan tinggi dan toleransi partisi karena susunan simpul peer-to-peer. HBase memberikan konsistensi dengan toleransi partisi karena satu primer HBase mereplikasi data ke semua simpul.
Berikutnya, kami akan menjelaskan lebih lanjut tentang perbedaan arsitektur dalam cara kedua basis data mengelola permintaan data.
Model data
Cassandra dan HBase mengatur data ke dalam grup, baris, dan kolom, namun setiap basis data membuatnya dengan layout yang berbeda. Di Cassandra, kolom data terkait disimpan dalam baris di bawah kategori yang lebih luas yang disebut ruang kunci. Misalnya, basis data Cassandra mungkin berisi keyspace berikut, rangkaian kolom, dan susunan sel:
- Keyspace : CustomerOrders
- Kelompok kolom: Klien
- ID, Nama Depan, Nama Belakang
- Kelompok kolom: Pesanan
- ID, Item, Harga
- Kelompok kolom: Klien
Kelompok kolom Klien berada di partisi di atas kelompok kolom Pesanan. Dalam aplikasi praktis, keyspace menumpuk beberapa kolom kelompok bersama-sama.
Arsitektur HBase memiliki layout yang menyerupai basis data relasional tradisional. HBase menggunakan kunci baris berurutan dalam tabel, alih-alih memiliki ID untuk setiap kelompok kolom. HBase kemudian mengatur kolom yang termasuk dalam kelompok kolom yang sama secara bersebelahan untuk memudahkan pengambilan data. Berikut ini adalah contohnya:
- Tabel; CustomerOrders
- Kunci Baris, Kelompok Kolom: Klien {Nama Depan, Nama Belakang}, Kelompok Kolom: Pesanan {Barang, Harga}
Baca tentang basis data relasional
Komponen utama
Cassandra menggunakan teknik yang disebut hashing konsisten untuk memungkinkan setiap node menemukan data tertentu dengan cepat di jaringan peer-to-peer-nya. Komponen utamanya termasuk tabel memtable, commit log, dan tabel SS. Komponen tersebut bersama-sama membentuk jalur penulisan untuk simpul, pusat data, dan klaster dalam arsitektur Cassandra.
HBase berada di atas HDFS. Basis data ini menggunakan primer HBase, server wilayah, dan Zookeeper untuk menyediakan manajemen data.
Cassandra menyediakan manajemen data dan penyimpanan data secara independen, dan HBase memerlukan sistem eksternal untuk kemampuan penyimpanan data.
Desain inti
Cassandra berjalan pada arsitektur aktif-aktif, tempat setiap simpul merespons penulisan dan permintaan. Bahkan jika simpul tertentu tidak menyimpan data yang diminta, simpul tersebut mengambilnya dari simpul lain dengan metode komunikasi peer-to-peer yang disebut protokol gosip.
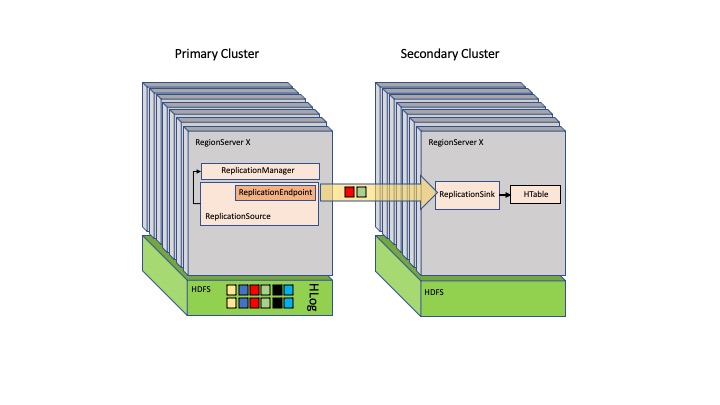
HBase menggunakan pengaturan primer-sekunder, tempat primer HBase mengontrol server wilayah simpul lain. Arsitektur HBase memberikan satu titik kegagalan jika tidak ada replika dari primer HBase. Anda dapat menduplikasi beberapa simpul primer HBase, tetapi hanya satu yang bertanggung jawab atas semua server wilayah.
Gambar berikut menunjukkan pengaturan primer-sekunder di HBase.
Bahasa kueri
Cassandra memungkinkan manipulasi data dalam basis data dengan Bahasa Kueri Cassandra (CQL). Anda menggunakan CQL untuk menambah, menghapus, atau memperbarui catatan dalam instruksi deskriptif yang mirip dengan SQL. Bahasa kueri HBase terdiri dari perintah shell dasar yang membutuhkan lebih banyak upaya untuk dipelajari.
Performa: Cassandra vs. HBase
Baik Cassandra maupun HBase menyediakan akses berkecepatan tinggi ke set data besar untuk analitik big data. Basis data menunjukkan perbedaan performa dalam aspek-aspek berikut.
Latensi
Latensi adalah kesenjangan waktu antara mengirim instruksi ke sistem database dan menyimpan atau mengambil data. Umumnya, HBase menunjukkan latensi yang lebih rendah karena jumlah data yang dibaca dan ditulis meningkat. Kebalikannya berlaku untuk Cassandra, yang menunjukkan penundaan yang lebih besar karena mengambil lebih banyak data.
Throughput
Th roughput mengukur jumlah operasi baca atau tulis yang ditangani database setiap detik. HBase mempertahankan throughput yang konsisten sebanyak 100.000–200.000 operasi, tetapi menunjukkan peningkatan setelah mencapai 250.000 operasi. Throughput Cassandra meningkat saat menulis atau membaca lebih banyak data.
Performa baca
Operasi baca di Cassandra melibatkan penemuan lokasi yang tepat dari data yang disimpan pada tabel partisi. Jika pencarian melibatkan kunci sekunder atau tabel non-partisi, Cassandra membutuhkan waktu lebih lama untuk mencari setiap simpul di klaster. Selain itu, inkonsistensi data terjadi ketika beberapa simpul berisi versi yang berbeda dari data yang sama.
HBase memiliki performa baca yang lebih baik daripada Cassandra karena HBase menulis semua data ke satu server. Tidak seperti di Cassandra, pembacaan data di HBase tidak memerlukan sistem basis data untuk mencari melalui tabel partisi. HDFS yang digunakan HBase untuk menyimpan data menyediakan filter bloom dan cache blok, yang mempercepat pengambilan data.
Performa tulis
Cassandra menyelesaikan operasi tulis lebih cepat dari HBase. Dengan Cassandra, Anda dapat menulis data ke log dan cache secara bersamaan. HBase tidak mendukung penulisan bersamaan. Aplikasi klien HBase melewati Zookeeper untuk memulai operasi tulis, dengan primer HBase menyediakan alamat untuk menyimpan data. Langkah-langkah tambahan di HBase memperlambat proses penulisan data.
Perbedaan utama lainnya: Cassandra vs. HBase
Anda dapat menggunakan Cassandra dan HBase untuk membangun aplikasi ilmu data, tetapi sedikit perbedaan memengaruhi keputusan untuk memilih salah satunya.
Keamanan
Dengan Cassandra, Anda dapat mengatur akses ke tingkat baris catatan. Cassandra juga menyediakan enkripsi SSL untuk melindungi pertukaran data antarsimpul. Tidak seperti Cassandra, HBase menyediakan enkripsi tingkat sel tambahan dan enkripsi serta fitur autentikasi.
Partisi data
Cassandra mendukung partisi berurutan, dan dapat memindai catatan yang disusun secara berurutan menggunakan kolom sebagai kunci partisi. Meskipun mungkin membantu, partisi berurutan mempersulit penyeimbangan beban, dengan beberapa penulisan terjadi pada satu simpul. Tabel HBase tidak mendukung partisi berurutan.
Komunikasi simpul
Dalam arsitektur Cassandra, simpul awal adalah titik utama untuk komunikasi antarklaster. Simpul ini menggunakan protokol gosip untuk memindahkan data antara klaster yang berbeda. HBase menggunakan simpul primer HBase aktif untuk mengoordinasikan komunikasi antara beberapa server wilayah. Dalam arsitektur ini, perpindahan data dinegosiasikan oleh protokol Zookeeper.
Kapan perlu menggunakan: Cassandra vs. HBase
Basis data Cassandra dan HBase dapat membantu berbagai tipe aplikasi big data. Selanjutnya, kami membagikan basis data terdistribusi mana yang akan bekerja lebih baik dibandingkan yang lain dalam kondisi yang berbeda.
Ketersediaan vs. konsistensi
Cassandra sangat cocok untuk kasus penggunaan yang memerlukan penulisan data yang sering, tetapi tidak dioptimalkan untuk pembaruan yang sering atau penghapusan data. Misalnya, organisasi menggunakan Cassandra untuk membangun sistem perpesanan, solusi pemrosesan data interaktif, dan penyimpanan data sensor waktu nyata. HBase lebih cocok untuk aplikasi yang membutuhkan konsistensi data dan pemrosesan yang sering. Misalnya, solusi perbankan, layanan kesehatan, dan telekomunikasi menggunakan HBase untuk menganalisis volume data yang besar.
Pengaturan basis data
Cassandra lebih mudah diatur karena merupakan produk mandiri dengan semua komponen basis data yang diperlukan. Tidak seperti Cassandra, HBase bergantung pada beberapa komponen Hadoop—seperti Zookeeper, primer HDFS, dan HDFS DataNode—untuk menjalankannya. Pengaturannya mungkin sederhana, tetapi mempertahankan beberapa interdependensi dapat terbukti menantang dalam aplikasi di kehidupan nyata. Jika Anda sudah menggunakan infrastruktur Hadoop, bermigrasi ke HBase mungkin terasa lebih mudah daripada bermigrasi ke Cassandra.
Ringkasan perbedaan: Cassandra vs. HBase
|
Cassandra |
HBase |
|
|
Desain inti |
Menggunakan arsitektur aktif-aktif. Semua simpul memproses permintaan baca/tulis. |
Menggunakan arsitektur primer-sekunder. HBase primer mengontrol beberapa server wilayah. |
|
Komponen utama |
Memtable, commit log, dan tabel SS. |
HBase primer, server wilayah, dan Zookeeper. |
|
Model data |
Simpan baris rangkaian kolom terkait di ruang kunci. |
Rangkaian kolom disusun secara horizontal dengan kunci baris berurutan. |
|
Bahasa kueri |
Menggunakan Cassandra Query Language. |
Menggunakan perintah shell. |
|
Latensi |
Latensi yang lebih tinggi dengan lebih banyak pengambilan data. |
Latensi yang lebih rendah dengan lebih banyak operasi data. |
|
Throughput |
Throughput meningkat dengan lebih banyak operasi data. |
Throughput meningkat setelah sejumlah operasi tertentu. |
|
Performa baca |
Baca perlahan. Mengacu pada tabel partisi untuk lokasi baca. Ketidakkonsistenan data dapat terjadi. |
Performa baca dan konsistensi data yang lebih baik. |
|
Performa tulis |
Performa tulis yang lebih baik. Menulis ke log dan cache secara bersamaan. |
Langkah-langkah tambahan. Melewati Zookeeper dan HBase primer. |
|
Keamanan |
Atur akses hingga tingkat peran. |
Atur akses hingga tingkat sel. |
|
Partisi data |
Mendukung partisi yang diurutkan. |
Tidak mendukung partisi yang diurutkan. |
|
Komunikasi simpul |
Menggunakan protokol gosip. |
Menggunakan protokol Zookeeper. |
Bagaimana AWS dapat membantu memenuhi kebutuhan Cassandra dan HBase Anda?
Amazon Web Services (AWS) menyediakan layanan basis data cloud yang dapat diskalakan yang dapat Anda gunakan untuk mengimplementasikan teknologi ilmu data secara efisien dan terjangkau. Alih-alih menyediakan infrastruktur yang mendasarinya secara manual, Anda dapat menggunakan layanan AWS berikut untuk mendukung basis data Cassandra dan HBase Anda:
- Amazon Keyspaces (untuk Apache Cassandra) adalah layanan database online untuk menjalankan beban kerja Cassandra throughput tinggi. Dengan Amazon Keyspaces, Anda dapat menskalakan aplikasi sambil mempertahankan waktu respons dalam waktu respons milidetik satu digit.
- Dengan Amazon EMR, Anda dapat menerapkan cluster HBase untuk aplikasi pemrosesan data skala besar. Menjalankan HBase di EMR meningkatkan kemampuan pemulihan data dengan membuat cadangan data yang disimpan di Amazon Simple Storage Service (Amazon S3).
Mulailah dengan analisis data besar di AWS dengan membuat akun hari ini.
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages