Batch Upload Files to Amazon S3 Using the AWS CLI
HOW-TO GUIDE
Overview
In this how-to guide, we are going to help you use the AWS Command Line Interface (AWS CLI) to access Amazon Simple Storage Service (Amazon S3). We will do this so you can easily build your own scripts for backing up your files to the cloud and easily retrieve them as needed. This will make automating your backup process faster, more reliable, and more programmatic. You can use this information to build a scheduled task (or cron job) to handle your backup operations.
Note: This guide builds upon the concepts from the Store and Retrieve a File with Amazon S3 how-to guide. If you haven't done that guide yet, you should complete it first.
AWS experience
Beginner
Time to complete
10 minutes
Cost to complete
Free Tier eligible
Requires
- AWS Account
- Recommended browser: The latest version of Chrome or Firefox
[**]Accounts created within the past 24 hours might not yet have access to the services required for this tutorial.
Last updated
Aug 9, 2022
Step 1: Create an AWS IAM User
In this step, you will use the IAM service to create a user account with administrative permission. In later steps, you will use this user account to securely access AWS services using the AWS CLI.
a. Click on the AWS Management Console home to open the console in a new browser window, so you can keep this step-by-step guide open. When this screen loads, enter your user name and password to get started. Then type IAM in the search bar and select IAM to open the Identity and Access Management dashboard.
.d6b99e45c987658d514976021bc0ff477a1ada75.png)
b. From the AWS Identity and Access Management dashboard, click on Users on the left side.
.e13506d7aa4b5b72e2b9e8571d660628f31e4eef.png)
c. Click the Add user button.
.f68cfa24dd9570ff109ae4d38047c31c1306c4a9.png)
d. Enter a user name in the textbox next to User name: (we’ll use AWS_Admin for this example) and select Programmatic access in the Select AWS Access Type section. Click the Next: Permissions button.
.0f3326392cdfab2c60cc91c203f98e78179a98ac.png)
e. Click on Attach existing policies directly option. Select AdministratorAccess then click Next: Tags.
.84c2664cf3fb28211c156e47b4e7a8c35d4bb56f.png)
f. IAM tags are key-value pairs you can add to your user. We’ll skip this step for this example. Click the Next: Review button.
.f3b5994be10d09f0e3fb3457c9444b406b4294ff.png)
g. Take this opportunity to review that all settings are correct. When you are ready, click on Create user.
.8a627c1fc14c8697009412eb4d47fa509207dde8.png)
h. Click the Download Credentials button and save the credentials.csv file in a safe location (you’ll need this later in step 3) and then click the Close button.
.ed3b6285adce894011edd15cde85b7ae4edb6a56.png)
Step 2: Install and Configure the AWS CLI
Now that you have your IAM user, you need to install the AWS CLI. Below are instructions based on the kind of operating system you are using; please select the tab that corresponds to your operating system.
Select PC from the tabs below if you are using a Windows-based computer.
Select Mac/Linux from the tabs below if you are using a machine running MacOS or Linux.
-
PC
-
Mac / Linux
-
PC
-
a. Download and run the Windows installer (64-bit, 32-bit).
Note: Users of Windows Server 2008 v6.0.6002 will need to use a different install method, listed in the AWS Command Line Interface User Guide.
b. Open a command prompt by pressing the Windows Key + r to open the run box and enter cmd and press the OK button.

c. Type aws configure and press enter. When prompted, enter the following:
AWS Access Key ID [None]: Enter the Access Key Id from the credentials.csv file you downloaded in step 1, part d
Note: This should look something like AKIAPWINCOKAO3U4FWTN
AWS Secret Access Key [None]: Enter the Secret Access Key from the credentials.csv file you downloaded in step 1, part d
Note: This should look something like 5dqQFBaGuPNf5z7NhFrgou4V5JJNaWPy1XFzBfX3
Default region name [None]: Enter us-east-1
Default output format [None]: Enter json

-
Mac / Linux
-
a. Follow these directions for installing the AWS CLI bundled installer.
b. MacOS users: Open a terminal window by pressing Command + Space and typing terminal in the search window. Then press enter to open the terminal window.
Linux users: Open a terminal window.

c. Type aws configure and press enter. Enter the following when prompted:
AWS Access Key ID [None]: Enter the Access Key Id from the credentials.csv file you downloaded in step 1, part d
Note: This should look something like AKIAPWINCOKAO3U4FWTN
AWS Secret Access Key [None]: Enter the Secret Access Key from the credentials.csv file you downloaded in step 1, part d
Note: This should look something like 5dqQFBaGuPNf5z7NhFrgou4V5JJNaWPy1XFzBfX3
Default region name [None]: Enter us-east-1
Default output format [None]: Enter json

Step 3: Using the AWS CLI with Amazon S3
In this step, you will use the AWS CLI to create a bucket in Amazon S3 and copy a file to the bucket.
a. Creating a bucket is optional if you already have a bucket created that you want to use. To create a new bucket named my-first-backup-bucket type:
aws s3 mb s3://my-first-backup-bucketNote: Bucket naming has some restrictions; one of those restrictions is that bucket names must be globally unique (e.g., two different AWS users can not have the same bucket name); because of this, if you try the command above you will get a BucketAlreadyExists error.

b. To upload the file my first backup.bak located in the local directory (C:\users) to the S3 bucket my-first-backup-bucket, you would use the following command:
aws s3 cp “C:\users\my first backup.bak” s3://my-first-backup-bucket/Or, use the original syntax if the filename contains no spaces.

c. To download my-first-backup.bak from S3 to the local directory we would reverse the order of the commands as follows:
aws s3 cp s3://my-first-backup-bucket/my-first-backup.bak ./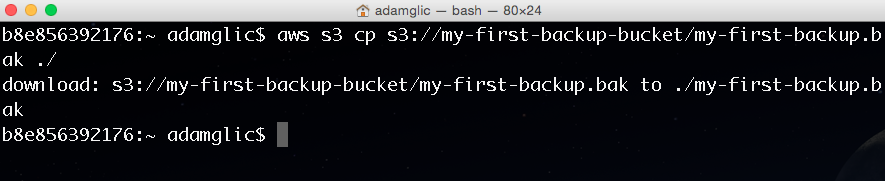
d. To delete my-first-backup.bak from your my-first-backup-bucket bucket, use the following command:
aws s3 rm s3://my-first-backup-bucket/my-first-backup.bak
Conclusion
Congratulations! You have set up an IAM user, configured your machine for use with the AWS command line interface, and learned how to create, copy, retrieve, and delete files from the cloud.
Next steps
Get Connected with the AWS Community
Find the hands-on tutorials for your AWS needs