Amazon Web Services ブログ

EngineLab AI: スタジオとクリエイターのための AWS 上のプロダクション環境対応 AI
スタジオは難しいジレンマに直面しています。AI ツールは制作ワークフローの効率化を約束する一方で、導入にあたってはセキュリティ、知的財産 (IP) の保護、制作の安定性に関する現実的な懸念と向き合わなければなりません。本記事では、このトレードオフを解消するソリューションを紹介します。AI コンテンツ生成向けのオープンソースなノードベースインターフェースである ComfyUI などの AI ツールを活用することで、[…]
Outpost VFX が ビジュアルエフェクト向けに AI モデルのトレーニングを AWS で加速した方法
本記事では、Outpost VFX が AWS インフラを活用してトレーニング速度を 8 倍に向上させ、顔置換ワークフローを刷新した方法、単一 GPU の限界を克服するために実装した技術アーキテクチャ、そして AWS マルチ GPU トレーニングで得られた具体的な成果について紹介します。

全従業員の行動変容を目指すAstemo が自己破壊を経て見つけたAI駆動開発の実効性
2026年6月10日〜12日、AWS Japan オフィスにて「AI-DLC UnicornGym」を開催しま […]

【開催報告】AWS Summit Japan 2026 物流業界向けブース展示「スマートグラス×生成AIエージェントで倉庫業務を革新」
こんにちは、ソリューションアーキテクトの田邊です。2026 年 6 月 25 日から 26 日にかけて幕張メッ […]

エージェンティック AI と AWS Transform でメインフレームアプリケーションを再構想 (reimagine) する
本ブログでは、reimagine パターンによってメインフレームのレガシーアプリケーションをモダナイズする AWS のアプローチの概要を説明し、組織がレガシー COBOL アプリケーションをモダンなクラウドネイティブアーキテクチャに変換する方法を紹介します。

週刊生成AI with AWS – 2026年7月20日週
週刊生成AI with AWS, 事例と Summit 開催報告が揃った 2026 年 7 月 20 日号 – 弁護士ドットコム株式会社様の AWS DevOps Agent 活用事例と、株式会社NTTドコモ様・KDDI株式会社様・ソフトバンク株式会社様の展示レポートを紹介。また、9 社合同 AI-DLC Unicorn Gym や Claude・Kiro 実践ワークショップなどのブログ記事も。サービスアップデートでは Claude Opus 5 の AWS 提供開始や Amazon CloudWatch のコーディングエージェントインサイトをはじめとする 12 件を紹介。
Amazon GuardDuty 調査エージェントのご紹介: オンデマンドの AI を活用した脅威評価
Amazon GuardDuty 調査エージェントのパブリックプレビューを発表しました。AI を活用してセキュリティ検出結果の調査を自動化し、調査時間を数時間から数分に短縮します。リスクレベル、信頼度スコア、MITRE ATT&CK 手法マッピング、推奨アクションを含む構造化された評価を提供します。本記事では、コンソールと AWS CLI による有効化と調査の実行手順、AWS MCP サーバーとの統合、AWS Security Incident Response との使い分けを解説します。

Security Hub が AI ワークロード保護と Microsoft Azure 対応のマルチクラウドサポートを追加
AWS Security Hub の 2 つの大きな拡張を発表します。マルチクラウドセキュリティ管理の対象を Microsoft Azure に拡大し、Azure の検出結果を AWS と統合して優先順位付けできるようになりました。さらに GuardDuty AI Protection による Amazon Bedrock や SageMaker の脅威検出、GuardDuty AI-powered investigations による調査の自動化、Security Hub AI inventory による AI 資産の可視化など、AI ワークロード保護の新機能も紹介します。

AWS Summit Japan 2026:完全自律型 AI Agent が変える SaaS の世界
AWS Summit Japan 2026 のブース展示にて、Amazon Bedrock AgentCore を活用したマルチテナント AI CRM のデモを展示しました。AI Agent の台頭により SaaS に求められる要素が変わりつつある中、SaaS に AI Agent を組み込むことで顧客体験をどう変えられるか、その設計上の 4 つのポイントを動くデモを通じて具体的に示しています。
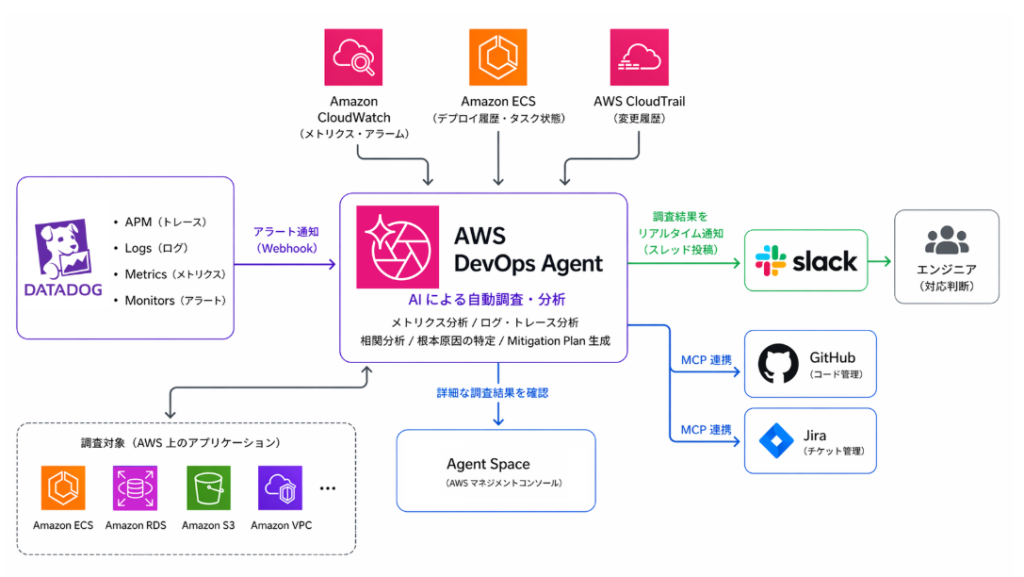
寄稿:弁護士ドットコムにおける AWS DevOps Agent の活用事例 – インシデント対応の自動化と属人化の解消
弁護士ドットコム株式会社は、『「プロフェッショナル・テック」で、次の常識をつくる。』というミッションのもと、国内最大級の法律相談ポータルサイト「弁護士ドットコム」や契約マネジメントプラットフォーム「クラウドサイン」などを運営しています。また、最近ではリーガル特化型 AI エージェント「Legal Brain エージェント」を開発し、AI を活用したリーガルサービスの進化にも取り組んでいます。PRE 部は、これらのサービスを支えるインフラの信頼性と運用効率の向上を担っています。本記事では、AWS DevOps Agent を用いたインシデント対応の自動化と運用組織のあり方の見直しを進めている事例を紹介します。