Amazon SageMaker は、機械学習モデルのスケーラブルな訓練とホスティングのための完全マネージド型サービスです。Amazon SageMaker の線形学習者アルゴリズムにマルチクラス分類のサポートが追加されます。線形学習者は、広告のクリック予測、不正検出、またはその他の分類問題のロジスティック回帰や売上予測、配達時間の予測、または数値の予測を目的とした線形回帰などの線形モデルに利用できる API を既に提供しています。線形学習者を利用したことがない場合は、本アルゴリズムに関するドキュメントまたはこれまでのブログ投稿をご参考にして使い始めて下さい。Amazon SageMaker が初めての場合は、ここから始めて下さい。
このブログ記事では、マルチクラス分類を線形学習者で訓練する 3 つの側面について説明します。
- マルチクラス分類器の訓練
- マルチクラス分類メトリクス
- バランスの取れたクラス毎の重み付けを使った訓練
マルチクラス分類器の訓練
マルチクラス分類は、機械学習タスクの一つで、出力がラベルの有限集合に入ることで知られています。たとえば、電子メールを分類するには、それぞれに受信トレイ、仕事、ショッピング、スパムの中のいずれかのラベルを割り当てます。あるいは、顧客が shirt、mug、bumper_sticker、no_purchase の中から何を購入するかを予測しようとするかもしれません。それぞれの例が数値的な特徴や既に知っているカテゴリのラベルがある場合、マルチクラス分類器を訓練することができます。
マルチクラス分類は、バイナリ分類およびマルチラベル問題の 2 つの機械学習タスクに関連します。線形学習者はすでにバイナリ分類をサポートしてましたが、マルチクラス分類も利用できるようになりました。ただし、マルチラベルサポートはまだサポートされてません。
データセットに可能性のあるラベルが 2 つしかない場合は、バイナリ分類問題になります。例としては、取引や顧客のデータに基づいて取引が不正であるかどうかを予測することや、写真から抽出された特徴に基づいて人が笑顔であるかどうかを検出することなどがあります。データセットの各例では、可能性のあるラベルの 1 つが正しく、もう 1 つが間違っています。その人物は笑顔なのか、笑顔でないのか。
あなたのデータセットに 3 つ以上の可能性のあるラベルがある場合、マルチクラス分類問題になります。たとえば、トランザクションが詐欺、キャンセル、返品、または通常どおりに完了するかどうかを予測します。また、写真の人物が笑っている、悩んでいるのか、驚いているのか、あるいは恐れているのかを検出することもできます。可能性のあるラベルは複数ありますが、一度に付けられる正しいラベルは 1 つだけです。
複数のラベルがあり、1 つの訓練サンプルに複数の正しいラベルがある場合は、マルチラベル問題になります。たとえば、既知のセットから画像にタグを付けるなどです。公園でフリスビーを追っている犬の画像は、屋外、犬、および公園でラベル付けするかもしれません。どんな画像でも、これらの 3 つのラベルがすべて真、すべてが偽、あるいは何らかの組み合わせになるはずです。マルチラベル問題のサポートはまだ追加されていませんが、現状の線形学習でマルチラベル問題を解決する方法がいくつかあります。ラベルごとに別々のバイナリ分類器を訓練することができます。または、マルチクラス分類器を訓練して、最上位クラスだけでなく、最上位の k クラス、または確率スコアがあるしきい値を超えるすべてのクラスを予測できます。
線形学習者は、softmax 損失関数を使用してマルチクラス分類器を訓練します。アルゴリズムは、各クラスの重みの集合を学習し、各クラスの確率を予測します。これらの確率を直接使用することができます。たとえば、電子メールを受信トレイ、仕事、ショッピング、スパムに分類して、クラスの確率が 99.99% を超える場合にのみスパムとしてフラグを立てるポリシーを検討します。しかし、多くのマルチクラス分類のユースケースでは、予測ラベルとして最も高い確率を持つクラスを取り上げます。
実例:森林被覆の種類を予測する
マルチクラス予測の例として、Covertype データセット (著作権: Jock A. Blackard とコロラド州立大学) を見てみましょう。このデータセットには、米国地質調査所および米国森林局がコロラド州北部の荒野について収集した情報が含まれています。特徴を土壌タイプ、標高、水との距離などの測定値とし、ラベルを基に各場所の樹木の種類 (森林被覆の種類) をエンコードします。機械学習のタスクは、特徴を使用して所定の場所での被覆の種類を予測することです。データセットをダウンロードして探索し、Python SDK を使用して線形学習者でマルチクラス分類器を訓練します。この例を自分で実行するには、このブログ記事のメモを見てみましょう。
# import data science and visualization libraries
%matplotlib inline
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
import seaborn as sns
# download the raw data and unzip
!wget https://archive.ics.uci.edu/ml/machine-learning-databases/covtype/covtype.data.gz
!gunzip covtype.data.gz
# read the csv and extract features and labels
covtype = pd.read_csv('covtype.data', delimiter=',', dtype='float32').as_matrix()
covtype_features, covtype_labels = covtype[:, :54], covtype[:, 54]
# transform labels to 0 index
covtype_labels -= 1
# shuffle and split into train and test sets
np.random.seed(0)
train_features, test_features, train_labels, test_labels = train_test_split(
covtype_features, covtype_labels, test_size=0.2)
# further split the test set into validation and test sets
val_features, test_features, val_labels, test_labels = train_test_split(
test_features, test_labels, test_size=0.5)
ラベルを 1 から始まるインデックスではなく、0 から始まるインデックスに変換したことに注意してください。この処理は重要です。何故なら線形学習者は、クラスラベルが [0, k-1] の範囲内に入っていることを期待してるからです。ここで、k はラベルの数を表します。Amazon SageMaker のアルゴリズムは、dtype (すべての特徴とラベル値) が float32 であることを期待します。また、訓練セットでは、例の順序を入れ替えていることにも注意してください。numpy の train_test_split メソッドを使います。numpy 配列に対応しているので、デフォルトで縦の列をシャッフルします。これは、確率的勾配降下法を用いて訓練されたアルゴリズムにとって重要です。線形学習者や最も深く学習するアルゴリズムでは、確率的勾配降下法を用いて最適化してます。訓練サンプルをシャッフルします。ただし、訓練サンプルにテストサンプルよりも前のタイムスタンプがあることを予測する問題など、データを自然な順序に保持する必要がある場合は除きます。
データを 80/10/10 の比率で訓練、検証、テストセットに分割しました。検証セットを使用すると、訓練が改善されます。これは、過学習が検出されると、線形学習者が訓練を中止するからです。つまり、訓練時間が短縮され、より正確な予測が可能になります。また、線形学習者にテストセットを与えることもできます。テストセットは最終モデルには影響しませんが、アルゴリズムのログにはテストセット上の最終モデルのパフォーマンスのメトリックが含まれます。この記事の後半では、テストセットをローカルで使用して、モデルのパフォーマンスについて少し掘り下げてみましょう。
データの調査
訓練データに含まれるクラスラベルの組み合わせを見てみましょう。データセットのドキュメントに記載したマッピングを使って、意味のあるカテゴリ名を追加します。
# assign label names and count label frequencies
label_map = {0:'Spruce/Fir', 1:'Lodgepole Pine', 2:'Ponderosa Pine', 3:'Cottonwood/Willow',
4:'Aspen', 5:'Douglas-fir', 6:'Krummholz'}
label_counts = pd.DataFrame(data=train_labels)[0].map(label_map).value_counts(sort=False).sort_index(ascending=False)
label_counts.plot('barh', color='tomato', title='Label Counts')
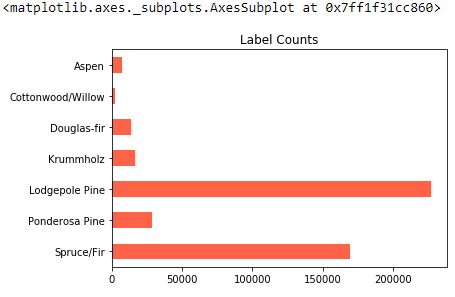
いくつかの森林被覆の種類は他よりもはるかに一般的であることがわかります。Lodgepole Pine と Spruce/Fir の両方が頻繁に現れます。Cottonwood/Willow のようなラベルは非常にまれです。この記事の後半では、これらのまれなカテゴリがユースケースにとって重要であるかどうかに応じて、アルゴリズムを微調整する方法を見ていきます。しかし、まず最高のオールアラウンドモデルのデフォルトを訓練します。
Amazon SageMaker Python SDK を使用した分類器の訓練を行う
高レベルのエスティメーターのクラスである LinearLearner を使って訓練ジョブと推論のエンドポイントをインスタンス化します。Python SDK の一般的な Estimator クラスをこの前の投稿で見てみましょう。一般的な Python SDK エスティメーターにはいくつかの制御オプションがありますが、高レベルのエスティメーターはより簡潔で、利点がいくつかあります。1 つは、訓練に使用するアルゴリズムコンテナの場所を指定する必要がないということです。これは、線形学習者アルゴリズムの最新バージョンを指定するからです。もう 1 つの利点は、訓練クラスタを起動する前に、コードエラーを発見することです。たとえば、誤りである n_classes=7 を正しい num_classes=7 の代わりに入力すると、高レベルのエスティメーターすぐに失敗しますが、一般的な Python SDK エスティメーターは失敗する前にクラスタを起動させます。
import sagemaker
from sagemaker.amazon.amazon_estimator import RecordSet
import boto3
# instantiate the LinearLearner estimator object
multiclass_estimator = sagemaker.LinearLearner(role=sagemaker.get_execution_role(),
train_instance_count=1,
train_instance_type='ml.m4.xlarge',
predictor_type='multiclass_classifier',
num_classes=7)
線形学習者は、protobuf または csv のコンテンツタイプの訓練データを受け取り、protobuf、csv、または json のコンテンツタイプの推論リクエストを受入れます。訓練データにはフィーチャーラベルとグラウンドトルースラベルが含まれますが、推論リクエストのデータにはフィーチャラベルのみになります。プロダクションパイプラインでは、データを Amazon SageMaker の protobuf 形式に変換して S3 に格納することをお勧めします。ただし、素早く起動して実行するために、便利なメソッド record_set を用意しています。データセットがローカルメモリに収まるように十分小さい場合に、変換およびアップロードを行うメソッドです。本メソッドは、numpy 配列に対応しているので、ここで使用します。この RecordSet はデータの一時的な S3 の保存場所を追跡します。
# wrap data in RecordSet objects
train_records = multiclass_estimator.record_set(train_features, train_labels, channel='train')
val_records = multiclass_estimator.record_set(val_features, val_labels, channel='validation')
test_records = multiclass_estimator.record_set(test_features, test_labels, channel='test')
# start a training job
multiclass_estimator.fit([train_records, val_records, test_records])
マルチクラス分類メトリクス
これで、訓練されたモデルが得られたので、テストセットで予測を行い、モデルのパフォーマンスを評価したいと思います。そのためには、エスティメーター API を使用して推論リクエストを受け入れるためのモデルホスティングエンドポイントをデプロイする必要があります。
# deploy a model hosting endpoint
multiclass_predictor = multiclass_estimator.deploy(initial_instance_count=1, instance_type='ml.m4.xlarge')
予測を解析し、モデルメトリックを評価するための便利な関数を追加します。この関数は、試験のための特徴をエンドポイントに与え、予測された試験ラベルを受け取ります。私たちが作成したモデルを評価するには、予測された試験ラベルを取り込み、何らかの一般的なマルチクラスメトリックスを用いて、それらを実際の結果と比較します。先に述べたように、predicted_label を各レスポンスペイロードから取得します。これは予測確率が最も高いクラスです。1 つの例につき 1 つのクラスラベルを取得します。各例につき 7 種類の確率ベクトル (各クラスの予測確率) を得るには、score をレスポンスペイロードから抽出します。線形学習者のレスポンス形式の詳細は、ドキュメントを参照ください。
def evaluate_metrics(predictor, test_features, test_labels):
"""
所定の予測エンドポイントを使用してテストセット上のモデルを評価します。分類メトリックを表示します。
"""
# split the test dataset into 100 batches and evaluate using prediction endpoint
prediction_batches = [predictor.predict(batch) for batch in np.array_split(test_features, 100)]
# parse protobuf responses to extract predicted labels
extract_label = lambda x: x.label['predicted_label'].float32_tensor.values
test_preds = np.concatenate([np.array([extract_label(x) for x in batch]) for batch in prediction_batches])
test_preds = test_preds.reshape((-1,))
# calculate accuracy
accuracy = (test_preds == test_labels).sum() / test_labels.shape[0]
# calculate recall for each class
recall_per_class, classes = [], []
for target_label in np.unique(test_labels):
recall_numerator = np.logical_and(test_preds == target_label, test_labels == target_label).sum()
recall_denominator = (test_labels == target_label).sum()
recall_per_class.append(recall_numerator / recall_denominator)
classes.append(label_map[target_label])
recall = pd.DataFrame({'recall': recall_per_class, 'class_label': classes})
recall.sort_values('class_label', ascending=False, inplace=True)
# calculate confusion matrix
label_mapper = np.vectorize(lambda x: label_map[x])
confusion_matrix = pd.crosstab(label_mapper(test_labels), label_mapper(test_preds),
rownames=['Actuals'], colnames=['Predictions'], normalize='index')
# display results
sns.heatmap(confusion_matrix, annot=True, fmt='.2f', cmap="YlGnBu").set_title('Confusion Matrix')
ax = recall.plot(kind='barh', x='class_label', y='recall', color='steelblue', title='Recall', legend=False)
ax.set_ylabel('')
print('Accuracy: {:.3f}'.format(accuracy))
# evaluate metrics of the model trained with default hyperparameters
evaluate_metrics(multiclass_predictor, test_features, test_labels)
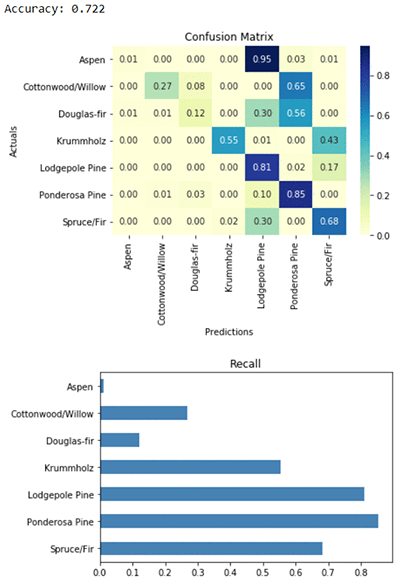
報告された最初のメトリックは正確です。マルチクラス分類の精度は、バイナリ分類の場合と同じ意味になります。つまり、グランドトゥルースラベルに一致する予測ラベルのパーセントです。私たちのモデルでは、適切な種類の森林が 72% 以上を占めている予測しています。
次に、混同行列と各ラベルのクラスリコールのプロットを見てみましょう。リコールはマルチクラス設定でも便利なバイナリ分類メトリクスです。これは、真のラベルが第 1 クラス、第 2 クラス、その他クラスに属している場合に、モデルの精度を測定します。すべてのクラスのリコール値の平均をとると、マクロリコールと呼ばれるメトリクスを得ることができます。これはアルゴリズムログに記録されています。また、マクロ精度やマクロ F -スコアも記録されています。
モデルによって得られたリコールは、クラスによって大きく異なります。リコールは最も一般的なラベルでは高くなりますが、Aspen や Cottonwood/Willow のような希少ラベルの場合は非常に低くなります。私たちの予測はほとんどの場合当てはまりますが、真の被覆タイプが Aspen、Cottonwood/Willow など稀なものである場合、モデルは間違った予測をする傾向があります。
混同行列は、マルチクラスモデルのパフォーマンスを視覚化するためのツールです。混同行列には、正しい予測と誤った予測のすべての可能な組み合わせのエントリーを含み、モデルによって作成されたそれぞれの頻度がわかります。混同行列の行は正規化されています。各行の合計は 1 であるため、対角線に沿ったエントリはリコールに対応します。たとえば、最初の行は、真のラベルが Aspen の場合、モデルは時間の 1% で正しく予測し、Lodgepole Pine は 95% の時間を誤って予測することを示しています。2 番目の行は、真の森林被覆タイプが Cottonwood/Willow であるとき、モデルは 27% のリコールを有し、Ponderosa Pine を 65% 間違って予測することを示しています。モデルの精度が 100% で、すべてのクラスで 100% のリコールがあった場合、すべての予測は混同行列の対角線に沿って行われます。
非常にまれなクラスではモデルのパフォーマンスは低くなります。それらについて学習したデータは少なく、全体的なパフォーマンスに合わせて最適化されています。線形学習者は、デフォルトでは多項分布の確率を最適化する softmax 損失関数を使用します。原理において、全体的な精度を最適化することに似ています。
しかし、希少なクラスラベルの 1 つがユースケースにとって特に重要な場合はどうでしょうか?たとえば、顧客ゲットの成果を予測するとして、不満を持った顧客が潜在的な成果をもたらす場合です。これは稀なケースであることを望みますが、この成果を予測することが特に重要で、直ちに行動する必要がある場合もあります。その場合、希少クラスのリコールを大幅に改善する代わりに、全体的な精度が犠牲になるなるかもしれません。その改善方法を見てみましょう。
バランスの取れたクラス毎の重み付けを使った訓練
クラス毎の重み付けで、線形学習者アルゴリズムによって最適化された損失関数を変更します。各クラスの重要性が等しくなるように、希少クラスに重み付けします。クラスの重みがない場合は、訓練セットの各例は等しく扱われます。これらの例の 80% が大きな比率を占める 1 つクラスの場合、モデル訓練中に注意の 80% はこのクラスに集中します。バランスの取れたクラスの重み付けの場合は、訓練中各クラスは同等の影響力を持ちます。
平均のとれたクラス毎の重み付けの場合、線形学習者は訓練セットのラベルの頻度をカウントします。これは、訓練セットのサンプルを使用して効率的に行われます。重みは頻度の逆数になります。サンプリングされた訓練例の 1/3 に存在するあるラベルは、3 の重みを持ち、訓練例のわずか 0.001% に存在する希少なラベルは 100,000 の重みを与えられます。サンプリングされた訓練例に存在しないラベルは、デフォルトで 1,000,000 の重みを与えられます。クラスの重みを有効にするには、balance_multiclass_weights hyperparameter:
# instantiate the LinearLearner estimator object
balanced_multiclass_estimator = sagemaker.LinearLearner(role=sagemaker.get_execution_role(),
train_instance_count=1,
train_instance_type='ml.m4.xlarge',
predictor_type='multiclass_classifier',
num_classes=7,
balance_multiclass_weights=True)
# start a training job
balanced_multiclass_estimator.fit([train_records, val_records, test_records])
# deploy a model hosting endpoint
balanced_multiclass_predictor = balanced_multiclass_estimator.deploy(initial_instance_count=1,
instance_type='ml.m4.xlarge')
# evaluate metrics of the model trained with balanced class weights
evaluate_metrics(balanced_multiclass_predictor, test_features, test_labels)
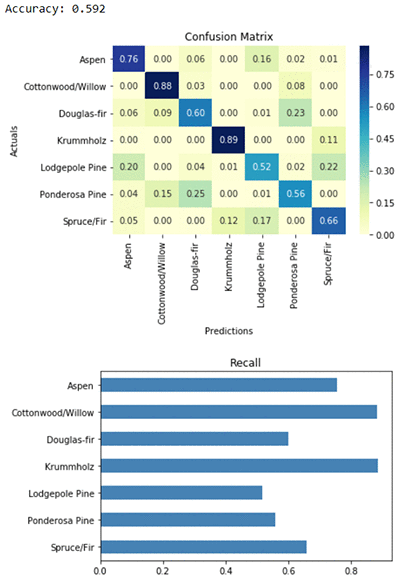
クラスの重みによって行われる違いは、混同行列を見れば明らかです。予測はマトリクスの対角線に沿ってきっちり整列します。予測されたラベルは実際のラベルと一致します。希少な Aspen クラスのリコールはたったの 1% でしたが、今はすべてのクラスのリコールが 50% を超えています。稀なラベルを正しく予測する能力が大幅に向上しました。
しかし、混同行列は、各行の合計値が1に正規化されていることを忘れないでください。診断ツールにおいて視覚的に各クラスに等しい重みを与えました。これは、希少クラスで得る改善を強調していますが、一般的なクラスを予測するためにかかるコストの強調が抑えられてます。最も一般的なクラスの Lodgepole Pine のリコールが、81% から 52% に減少しました。これによって、全体的な精度も 72% から 59% に低下しました。アプリケーションにバランスの取れたクラス毎の重み付けを適用するかどうかを判断するには、一般的なケースで予測エラーが発生した場合のビジネスへの影響と、希少なエラーが発生した場合の影響を比較します。
ホスティングのエンドポイントの削除
最後に、ホスティングのエンドポイントを削除します。訓練に使用したマシンは自動的にシャットダウンしますが、ホスティングのエンドポイントはシャットダウンしない限りアクティブ状態のままです。
# delete endpoints
multiclass_predictor.delete_endpoint()
balanced_multiclass_predictor.delete_endpoint()
まとめ
この記事では、Amazon SageMaker 線形学習アルゴリズムの新しいマルチクラス分類機能を紹介しました。便利で高レベルのエスティメーター API を使用してマルチクラスモデルを適合させる方法と、モデルメトリックを評価して解釈する方法を示しました。また、線形学習者の自動クラス重み付け計算を使用して、希少クラスのリコール率を上げる方法を示しました。Amazon SageMaker と分類問題において線形学習者を今すぐお試しください!
今回のブログ投稿者について
 Philip Gautier は Amazon AI アルゴリズムグループの応用科学者です。このグループは、Amazon SageMaker での機械学習アルゴリズムに対して責任を負っています。統計的モデルのスケーラブルな最適化とデータ可視化に関連するバックグラウンドを持っています。
Philip Gautier は Amazon AI アルゴリズムグループの応用科学者です。このグループは、Amazon SageMaker での機械学習アルゴリズムに対して責任を負っています。統計的モデルのスケーラブルな最適化とデータ可視化に関連するバックグラウンドを持っています。
 Zohar Karnin は、Amazon AI のプリンシパルサイエンティストです。研究分野として、大規模およびオンライン機械学習アルゴリズムに関心を持っています。彼は、Amazon SageMaker のために、スケールの限界のない機械学習アルゴリズムを開発しました。
Zohar Karnin は、Amazon AI のプリンシパルサイエンティストです。研究分野として、大規模およびオンライン機械学習アルゴリズムに関心を持っています。彼は、Amazon SageMaker のために、スケールの限界のない機械学習アルゴリズムを開発しました。
 Saswata Chakravarty は、AWS アルゴリズムチームのソフトウェアエンジニアです。SageMaker に高速でスケーラブルなアルゴリズムを持ち込み、顧客の使いやすいものとするために働いています。余暇には政治風刺の番組を沢山視聴しており、John Oliver の熱烈なファンです。
Saswata Chakravarty は、AWS アルゴリズムチームのソフトウェアエンジニアです。SageMaker に高速でスケーラブルなアルゴリズムを持ち込み、顧客の使いやすいものとするために働いています。余暇には政治風刺の番組を沢山視聴しており、John Oliver の熱烈なファンです。