Artificial Intelligence
Train faster, more flexible models with Amazon SageMaker Linear Learner
Today Amazon SageMaker is launching several additional features to the built-in linear learner algorithm. Amazon SageMaker algorithms are designed to scale effortlessly to massive datasets and take advantage of the latest hardware optimizations for unparalleled speed. The Amazon SageMaker linear learner algorithm encompasses both linear regression and binary classification algorithms. These algorithms are used extensively in banking, fraud/risk management, insurance, and healthcare. The new features of linear learner are designed to speed up training and help you customize models for different use cases. Examples include classification with unbalanced classes, where one of your outcomes happens far less frequently than another. Or specialized loss functions for regression, where it’s more important to penalize certain model errors more than others.
In this blog post we’ll cover three things:
- Early stopping and saving the best model
- New ways to customize linear learner models, including:
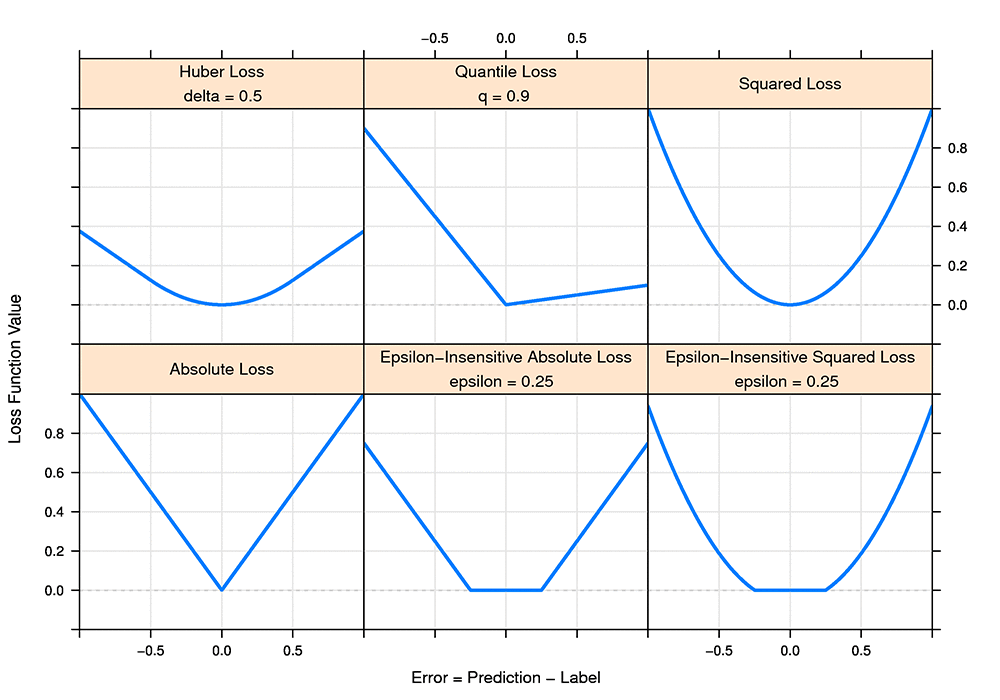
- Hinge loss (support vector machines)
- Quantile loss
- Huber loss
- Epsilon-insensitive loss
- Class weights options
- Then we’ll walk you through a hands-on example of using class weights to boost performance in binary classification
Early Stopping
Linear learner trains models using Stochastic Gradient Descent (SGD) or variants of SGD like Adam. Training requires multiple passes over the data, called epochs, in which the data are loaded into memory in chunks called batches, sometimes called minibatches. How do we know how many epochs to run? Ideally, we’d like to continue training until convergence – that is, until we no longer see any additional benefits. Running additional epochs after the model has converged is a waste of time and money, but guessing the right number of epochs is difficult to do before submitting a training job. If we train for too few epochs, our model will be less accurate than it should be, but if we train for too many epochs, we’ll waste resources and potentially harm model accuracy by overfitting. To remove the guesswork and optimize model training, linear learner has added two new features: automatic early stopping and saving the best model.
Early stopping works in two basic regimes: with or without a validation set. Often we split our data into training, validation, and testing data sets. Training is for optimizing the loss, validation is for tuning hyperparameters, and testing is for producing an honest estimate of how the model will perform on unseen data in the future. If you provide linear learner with a validation data set, training will stop early when validation loss stops improving. If no validation set is available, training will stop early when training loss stops improving.
Early Stopping with a validation data set
One big benefit of having a validation data set is that we can tell if and when we start overfitting to the training data. Overfitting is when the model gives predictions that are too closely tailored to the training data, so that generalization performance (performance on future unseen data) will be poor. The following plot on the right shows a typical progression during training with a validation data set. Until epoch 5, the model has been learning from the training set and doing better and better on the validation set. But in epochs 7-10, we see that the model has begun to overfit on the training set, which shows up as worse performance on the validation set. Regardless of whether the model continues to improve (overfit) on the training data, we want to stop training after the model starts to overfit. And we want to restore the best model from just before the overfitting started. These two features are now turned on by default in linear learner.
The default parameter values for early stopping are shown in the following code. To tweak the behavior of early stopping, try changing the values. To turn off early stopping entirely, choose a patience value larger than the number of epochs you want to run.
The parameter early_stopping_patience defines how many epochs to wait before ending training if no improvement is made. It’s useful to have a little patience when deciding to stop early, since the training curve can be bumpy. Performance may get worse for one or two epochs before continuing to improve. By default, linear learner will stop early if performance has degraded for three epochs in a row.
The parameter early_stopping_tolerance defines the size of an improvement that’s considered significant. If the ratio of the improvement in loss divided by the previous best loss is smaller than this value, early stopping will consider the improvement to be zero.
Early stopping without a validation data set
When training with a training set only, we have no way to detect overfitting. But we still want to stop training once the model has converged and improvement has levelled off. In the left panel of the following figure, that happens around epoch 25.
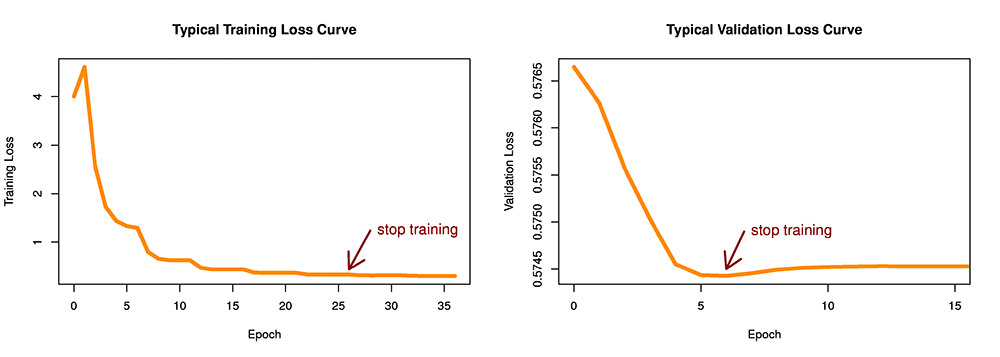
Figure 1: Early Stopping with and without a Validation Data Set
Early stopping and calibration
You may already be familiar with the linear learner automated threshold tuning for binary classification models. Threshold tuning and early stopping work together seamlessly by default in linear learner.
When a binary classification model outputs a probability (e.g., logistic regression) or a raw score (SVM), we convert that to a binary prediction by applying a threshold, for example:
Hands-on example: Detecting credit card fraud
In this section, we’ll look at a credit card fraud detection dataset. The data set (Dal Pozzolo et al. 2015) was downloaded from Kaggle. We have features and labels for over a quarter million credit card transactions, each of which is labeled as fraudulent or not fraudulent. We’d like to train a model based on the features of these transactions so that we can predict risky or fraudulent transactions in the future. This is a binary classification problem.
We’ll walk through training linear learner with various settings and deploying an inference endpoint. We’ll evaluate the quality of our models by hitting that endpoint with observations from the test set. We can take the real-time predictions returned by the endpoint and evaluate them against the ground-truth labels in our test set.
Next, we’ll apply the linear learner threshold tuning functionality to get better precision without sacrificing recall. Then, we’ll push the precision even higher using the new linear learner class weights feature. Because fraud can be extremely costly, we would prefer to have high recall, even if this means more false positives. This is especially true if we are building a first line of defense, flagging potentially fraudulent transactions for further review before taking actions that affect customers.
We’ve already done some preprocessing on this data set: we’ve shuffled the examples and split them into train and test sets. Data exploration showed that only 0.17% of the data have positive labels, making this a challenging classification problem. Now we’ll pick up where we left off, with the preprocessed data we wrote to Amazon S3. For details of the postprocessing, take a look at the full notebook associated with this blog post.
We’ll wrap the model training setup in a convenience function that takes in the Amazon S3 location of the training data, the model hyperparameters that define our training job, and the Amazon S3 output path for model artifacts. Inside the function, we’ll hardcode the algorithm container, the number and type of Amazon EC2 instances to train on, and the input and output data formats.
And add another convenience function for setting up a hosting endpoint, making predictions, and evaluating the model. To make predictions, we need to set up a model hosting endpoint. Then we feed test features to the endpoint and receive predicted test labels. To evaluate the models we create in this exercise, we’ll capture predicted test labels and compare them to actuals using some common binary classification metrics.
And finally we’ll add a convenience function to delete prediction endpoints after we’re done with them:
Let’s begin by training a binary classifier model with the linear learner default settings. Note that we’re setting the number of epochs to 40, which is much higher than the default of 10 epochs. With early stopping, we don’t have to worry about setting the number of epochs too high. Linear learner will stop training automatically after the model has converged.
And now we’ll produce a model with a threshold tuned for the best possible precision with recall fixed at 90%:
Improving recall with class weights
Now we’ll improve on these results using a new feature added to linear learner: class weights for binary classification. We introduced this feature in the Class Weights section, and now we’ll look into its application to the credit card fraud dataset by training a new model with balanced class weights:
The first training examples used the default loss function for binary classification, logistic loss. Now let’s train a model with hinge loss. This is also called a support vector machine (SVM) classifier with a linear kernel. Threshold tuning is supported for all binary classifier models in linear learner.
And finally, let’s see what happens with balancing the class weights for the SVM model:
Now we’ll make use of the prediction endpoint we’ve set up for each model by sending them features from the test set and evaluating their predictions with standard binary classification metrics.
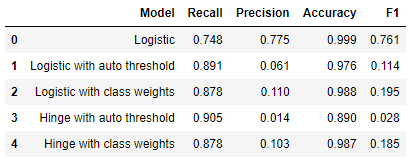
The results are in! With threshold tuning, we can accurately predict 89% of the fraudulent transactions in the test set (recall = 0.89). But in addition to those true positives, we’ll have a high number of false positives: 94% of the transactions we predict to be fraudulent are in fact not fraudulent (precision = 0.06). This model would work well as a first line of defense, flagging potentially fraudulent transactions for further review. If we instead want a model that gives very few false alarms, at the cost of catching far fewer of the fraudulent transactions, then we should optimize for higher precision:
And what about the results of using our new feature, class weights for binary classification? Training with class weights has made a huge improvement to this model’s performance! The precision has doubled to 11%, while recall is still held constant at 88%.
Balancing class weights improved the performance of our SVM predictor, but it still does not match the corresponding logistic regression model for this dataset. Comparing all of the models we’ve fit so far, logistic regression with class weights and tuned thresholds did the best.
Note on target vs. observed recall
It’s worth taking some time to look more closely at these results. If we asked linear learner for a model calibrated to a target recall of 0.9, then why did we get only 89% recall on the test set? The reason is the difference between training, validation, and testing. Linear learner calibrates thresholds for binary classification on the validation data set when one is provided, or else on the training set. Since we did not provide a validation data set, the threshold were calculated on the training data. Since the training, validation, and test data sets don’t match exactly, the target recall we request is only an approximation. In this case, the threshold that produced 90% recall on the training data happened to produce only 89% recall on the test data. The variation of recall in the test set versus the training set is dependent on the number of positive points. In this example, although we have over 280,000 examples in the entire dataset, we only have 337 positive examples, hence the large difference. The accuracy of this approximation can be improved by providing a large validation data set to get a more accurate threshold, and then evaluating on a large test set to get a more accurate benchmark of the model and its threshold. For even more fine-grained control, we can set the number of calibration samples to a higher number. It’s default value is already quite high at 10 million samples:
Clean Up
Finally we’ll clean up by deleting the prediction endpoints we set up:

Summary
We have shown you how to use the linear learner new early stopping feature, new loss functions, and new class weights feature to improve credit card fraud prediction. Class weights can help you optimize recall or precision for all types of fraud detection, as well as other classification problems with rare events, like ad click prediction or mechanical failure prediction. Try using class weights in your binary classification problem, or try one of the new loss functions for your regression problems: use quantile prediction to put confidence intervals around your predictions by learning 5% and 95% quantiles. For more information about new loss functions and class weights, see the linear learner documentation.
References
Andrea Dal Pozzolo, Olivier Caelen, Reid A. Johnson and Gianluca Bontempi. Calibrating Probability with Undersampling for Unbalanced Classification. In Symposium on Computational Intelligence and Data Mining (CIDM), IEEE, 2015. See link to full license text on Kaggle.
About the Authors
 Philip Gautier is an Applied Scientist for the Amazon AI Algorithms group, which is responsible for the machine learning algorithms in Amazon SageMaker. His background is in scalable optimization for statistical models and data visualization.
Philip Gautier is an Applied Scientist for the Amazon AI Algorithms group, which is responsible for the machine learning algorithms in Amazon SageMaker. His background is in scalable optimization for statistical models and data visualization.
 Cyrus Vahid is a Principal Solution Architect at AWS Deep Learning. Cyrus is an AI specialist, proficient in artificial neural networks and platforms such as Apache MXNet. He has been working on various stages of software development from engineering to leadership. His current interests include natural language processing, recommender systems, and reinforcement learning.
Cyrus Vahid is a Principal Solution Architect at AWS Deep Learning. Cyrus is an AI specialist, proficient in artificial neural networks and platforms such as Apache MXNet. He has been working on various stages of software development from engineering to leadership. His current interests include natural language processing, recommender systems, and reinforcement learning.
 Zohar Karnin is a Principal Scientist in Amazon AI. His research interests are in the area of large scale and online machine learning algorithms. He develops infinitely scalable machine learning algorithms for Amazon SageMaker.
Zohar Karnin is a Principal Scientist in Amazon AI. His research interests are in the area of large scale and online machine learning algorithms. He develops infinitely scalable machine learning algorithms for Amazon SageMaker.
 Saswata Chakravarty is a Software Engineer in the AWS Algorithms team. He works on bringing fast and scalable algorithms to SageMaker and making them easy to use for customers. In his spare time, he watches lot of political satire and is a big fan of a John Oliver.
Saswata Chakravarty is a Software Engineer in the AWS Algorithms team. He works on bringing fast and scalable algorithms to SageMaker and making them easy to use for customers. In his spare time, he watches lot of political satire and is a big fan of a John Oliver.