Amazon Web Services ブログ
AWS Data Exchange と Amazon SageMaker による機械学習ワークフローの構築
Amazon SageMaker や AWS Data Exchange などのクラウドサービスのおかげで、機械学習 (ML) がこれまで以上に簡単になりました。この記事では、AWS Data Exchange と Amazon SageMaker を使用して、NYC レストランのレストラングレードを予測するモデルを構築する方法について説明します。Amazon SageMaker とともに、AWS Data Exchange の 23,372 のレストラン検査グレードとスコアのデータセットを使用して、線形学習アルゴリズムによりモデルをトレーニングしてデプロイします。
バックグラウンド
ML ワークフローは反復プロセスであり、トレーニングデータが必要かどうか、どの属性をキャプチャするか、どのアルゴリズムを使用するか、トレーニング済みモデルをどこにデプロイするかなど、多くの決定が必要です。これらの決定はすべて、学習システムの結果に影響します。問題が定義されたら、4 種類の学習システムから選択する必要があります。一部の学習システムは完全にトレーニングデータに依存していますが、他のトレーニングシステムではトレーニングデータをまったく必要とせず、むしろ明確に定義された環境とアクションスペースが必要です。アルゴリズムがトレーニングデータに依存する場合、最終モデルの品質と感度はトレーニングセットの特性に大きく左右されます。ここで多くの人が、機能の適切なバランスを見つけてバランスのとれた正確なモデルを得ようとする退屈なループに入ります。各学習システムの概要を以下に示します。
- 教師あり – 教師あり学習では、トレーニングセットにラベルが含まれているため、アルゴリズムは属性セットが与えられると正しいラベルを認識します。たとえば、ラベルが魚の一種である場合、属性は魚の色と重さである可能性があります。モデルは最終的に、正しいか、最も可能性の高いラベルを割り当てる方法を学習します。典型的な教師あり学習タスクは分類です。これは、テキストや画像などの入力情報をいくつかの定義済みカテゴリの 1 つに割り当てるタスクです。たとえば、メッセージヘッダーとコンテンツに基づいてスパム E メールを検出し、MRI スキャンの結果に基づいて悪性または良性としてセルを分類し、その形状に基づいてギャラクシーを分類します (Tan et al.2006)。このカテゴリで使用するアルゴリズムは通常、k 最近傍、線形回帰、ロジスティック回帰、サポートベクターマシン、およびニューラルネットワークで構成されています。
- 教師なし – 教師なし学習では、ラベルなしデータの関係を発見するアルゴリズムを使用します。アルゴリズムは、データを探索し、既知の特徴に基づいて関係を見つける必要があります。教師なし学習で使用される一般的なアルゴリズムには、同様のデータポイントをグループ化するクラスタリング (K-means、DBSCAN、階層クラスター分析)、異常値を見つけようとする異常検出、それに特徴間の相関を発見しようとする相関ルール学習が含まれます (Aurélien 2019)。実際には、これは犯罪率に基づいて都市をクラスタリングして類似する都市を見つけたり、顧客の年齢に基づいて食料品店で製品をクラスタリングしてパターンを発見したりすることで確認できます。
- 半教師あり – 半教師あり学習では、ラベル付きデータとラベルなしデータの両方で構成されるトレーニングデータを使用します。アルゴリズムは、多くの場合、教師なしアルゴリズムと教師ありアルゴリズムの両方の組み合わせです。ラベルなしデータを含むデータセットがある場合、最初のステップは、データにラベル付けすることです。データセットにラベルを付けたら、従来の教師ありの学習手法でアルゴリズムをトレーニングして、特徴を既知のラベルにマッピングできます。フォトホスティングサービスは、多くの場合、スキルを活かすことでこのワークフローを使用して、未知の顔にラベルを付けます。顔がわかると、別のアルゴリズムがすべての写真をスキャンして、現在既知の顔を特定できます。
- 強化 – 強化学習 (RL) は、トレーニングデータから学習する必要がないため、上記の学習システムとは異なります。代わりに、モデルは、明確に定義された環境のコンテキストにおける独自の経験から学習します。学習システムはエージェントと呼ばれ、エージェントは環境を観察し、ポリシーに基づいてアクションを選択および実行し、見返りに報酬を取得します。エージェントは、最終的にその以前の経験に基づいて、時間をかけてその報酬を最大化することを学習します。RL の詳細、またはその説明については、Amazon SageMaker RL 上のドキュメントを参照してください。
レストラングレードの予測モデルを構築する手順
ML プロジェクトを開始するときは、最終製品だけでなくプロセス全体について考えることが重要です。このプロジェクトでは、次の手順を実行します。
- 解決したい問題を定義します。この場合、清潔さに基づいて NYC で食事をするレストランを決定するのに、より多くの情報に基づいて選択したいと考えています。
- モデルをトレーニングするデータセットを検索します。NYC のレストランの検査グレードとスコアを含むデータセットが必要です。
- データを確認します。必要なデータが存在し、モデルをトレーニングするのに十分なデータがあるようにします。
- Amazon SageMaker でのトレーニング用にデータセットを準備してクリーンアップします。地区や食品カテゴリなどの必要なデータのみを含め、正しい形式が確実に使用されるようにします。
- マルチクラス分類のモデルを選択します。この例では、線形学習アルゴリズムを使用してトレーニングしています。
- Amazon SageMaker にモデルをデプロイします。モデルを Amazon SageMaker にデプロイすると、エンドポイントを呼び出して予測を取得できます。
データは ML の基盤です。最終モデルの品質は、トレーニングに使用するデータの品質に左右されます。この記事のワークフローでは、手順の半分はデータの収集と準備に関するものです。このテーマはほとんどの ML プロジェクトで見ることができ、多くの場合、最も難しい部分です。さらに、データの特性を考慮して、過度に機密性の高いモデルや機密性の低いモデルを防ぐ必要があります。さらに、すべてのデータが内部にあるわけではありません。無料または有料のサードパーティデータを使用して内部データセットを充実させ、モデルの品質を向上させる必要があるかもしれません。けれども、このサードパーティデータの検索、ライセンス供与、消費は長年の課題でした。さいわい、今は AWS Data Exchange があります。
AWS Data Exchange の使用
AWS Data Exchange では、クラウド内のサードパーティのデータを簡単に検索、購読、使用できるようにすることで、データ収集プロセスを簡素化できます。AWS Marketplace で 90 を超える認定データプロバイダーの 1,500 を超えるデータ製品を閲覧できます。以前は、分析を促進し、ML モデルをトレーニングし、データ駆動型の意思決定を行うために、より多くのデータにアクセスする必要がありましたが、AWS Data Exchange では、すべてを 1 か所にまとめることができます。詳細については、「AWS Data Exchange – データ製品の検索、サブスクライブ、使用」を参照してください。
AWS Data Exchange により、ML を簡単に開始できます。利用可能な数百のデータセットの 1 つまたはその組み合わせを使用して、プロジェクトをすぐに開始できます。また、外部のサードパーティのデータを使用して内部データを豊かにすることもできます。Amazon S3 にデータを直接配信する単一のクラウドネイティブ API を使用して、すべてのデータセットを利用できます。これは、以下のワークフローに示されています。これにより、ユーザーとそのチームの貴重な時間とリソースを節約できます。節約した時間とリソースは、より付加価値の高い活動に当てられます。この組み合わせにより、AWS Data Exchange からデータを取得して Amazon SageMaker にフィードし、モデルをトレーニングしてデプロイできます。
Amazon SageMaker の使用
Amazon SageMaker は、ML モデルをすばやく簡単に構築、トレーニング、デプロイできるようにする完全マネージド型のサービスです。NYC レストランのデータを AWS Data Exchange から取得し、Amazon SageMaker の機能を使用してモデルをトレーニングしてデプロイできます。Jupyterノートブックを実行する完全マネージド型のインスタンスを使用して、トレーニングデータを探索および前処理します。これらのノートブックには、一般的なディープラーニングプラットフォーム用の CUDA と cuDNN ドライバー、Anaconda パッケージ、および TensorFlow、Apache MXNet、PyTorch 用のライブラリがプリロードされています。
また、線形学習アルゴリズムなどの教師付きアルゴリズムを使用して、モデルをトレーニングします。最後に、モデルを Amazon SageMaker エンドポイントにデプロイして、リクエストのサービスとレストランのグレードの予測を開始します。AWS Data Exchange の力と Amazon SageMaker を組み合わせることで、最も困難な ML 問題の解決を開始するための強力なツールセットを手に入れることができます。そしてマルチクラス分類子の構築を開始するのに最適な位置にいます。
ソリューションの概要
この記事のソリューションでは、地区と食品カテゴリに基づいてニューヨーク市のレストランのグレードを予測できるマルチクラス分類子を生成します。次の図は、アーキテクチャの全体像を示しています。

まず、AWS Data Exchange からデータを取得し、S3 バケットに配置します。AWS Glue クローラを指して、このデータのデータカタログを作成します。データカタログを配置したら、Amazon Athena を使用して、トレーニングのためにデータをクエリ、クリーンアップ、フォーマットします。データが変換されたら、トレーニングセットを S3 にロードし直します。最後に、Amazon SageMaker で Jupyter ノートブックを作成して、予測子をトレーニング、デプロイ、および呼び出します。
S3 にデータを保存する
トレーニングデータの取得は、多くの場合、ML プロジェクトの時間のかかる困難な部分です。この場合、NYC のレストランの検査情報を含む十分な大きさのデータセットが実際に見つかり、適切な属性が含まれるようにする必要があります。さいわい、AWS Data Exchange では、製品カタログでデータの検索を開始できます。この場合、ニューヨーク市のレストランの質に関心があるため、検索バーに「New York Restaurant Data」と入力し、無料のデータセットをフィルタリングします。Intellect Design Arena, Inc. の製品が、NY City Restaurant Data with Inspection grade & score (Trial) というタイトルで無料で提供されています。
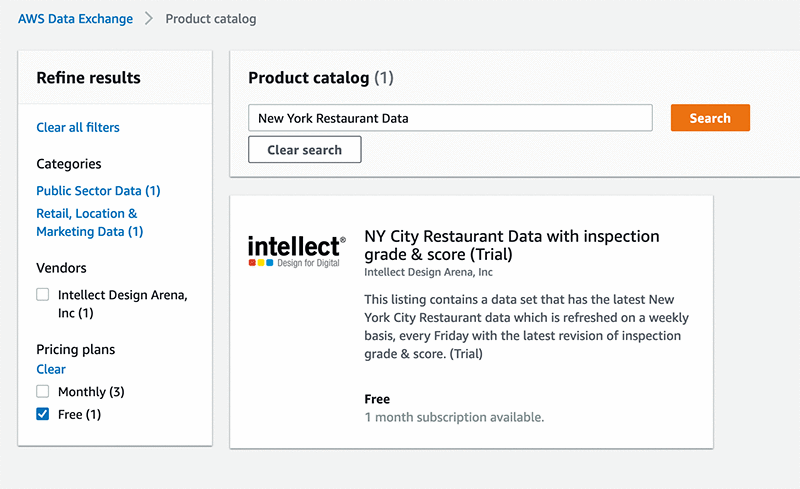
データセットをサブスクライブした後、他の AWS のサービスにデータを公開する方法を見つける必要があります。これを実現するには、サブスクリプション、データセット、リビジョン、S3 へのエクスポートを選択して、データを S3 にエクスポートします。データが S3 にあると、ファイルをダウンロードしてデータを調べ、どの機能がキャプチャされているかを確認できます。次のスクリーンショットは改訂ページを示していて、「Amazon S3 にエクスポート」ボタンを使用してデータをエクスポートできます。

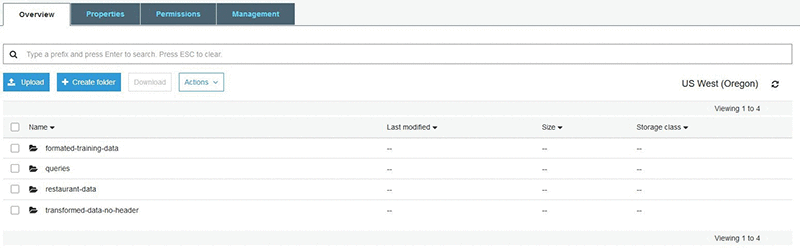
これで、ファイルをダウンロードして内容を確認し、データの量とキャプチャされる属性を理解できます。この例で関心があるのは、地区 (BORO とラベル付け)、料理の説明、グレードの 3 つの属性のみです。このユースケースに関連するデータのみを含む新しいファイルが作成され、S3 にロードし直されます。データが S3 にあることで、他の AWS のサービスは、迅速かつ安全にデータにアクセスすることができます。次のスクリーンショットは、フォルダとデータが読み込まれた後の S3 バケットの様子を例示しています。
AWS Glue クローラを使用してデータカタログを作成する
現在のフォームのデータは Amazon SageMaker でのトレーニング用に正しくフォーマットされていません。そのため、このデータセットを適切なフォーマットにするには、抽出、変換、ロード (ETL) パイプラインを構築する必要があります。パイプラインの後半で、Athena を使用してこのデータをクエリし、フォーマット済みのトレーニングセットを生成しますが、現在のデータはバケット内の CSV ファイルであり、データとやり取りする方法が必要です。AWS Glue クローラを使用してデータをスキャンし、Athena が S3 内のデータをクエリできるようにするデータカタログを生成できます。詳細については、「クローラの定義」を参照してください。AWS Glue クローラの実行後、Athena がデータのクエリに使用できるデータカタログが作成されました。データの詳細がキャプチャされ、新しく作成されたデータカタログをクリックして表示できます。以下のスクリーンショットは、データに関するすべての情報を含むデータカタログインターフェイスを示しています。

Athena のデータのクエリとトレーニングセットの作成
S3 にデータセットと AWS Glue クローラのデータカタログができたので、Athena を使用してデータのクエリとフォーマットを開始できます。統合されたクエリエディタを使用して、データを探索および変換できる SQL クエリを生成できます。この例では、SQL クエリを作成して、次のトレーニングセットを生成しました。これは、テキストベースの属性から数値ベースの属性に移行しているため、トレーニングプロセスを簡素化するためです。マルチクラス分類に線形学習アルゴリズムを使用する場合、クラスラベルは 0〜N-1 の数値である必要があります。N は可能なクラスの数です。Athena でクエリを実行した後、結果をダウンロードし、新しいデータセットを S3 に配置できます。これで、Amazon SageMaker でモデルのトレーニングを開始する準備ができました。次のコードを参照してください。
SQL クエリは、属性とクラスラベルの数値表現を作成します。これは、次のテーブルに示されています。
| boro_label | cat_label | class_label | |
| 1 | 5 | 8 | 0 |
| 2 | 5 | 8 | 0 |
| 3 | 5 | 8 | 0 |
| 4 | 5 | 8 | 0 |
| 5 | 5 | 8 | 0 |
| 6 | 5 | 8 | 0 |
| 7 | 5 | 8 | 0 |
| 8 | 5 | 8 | 0 |
| 9 | 5 | 8 | 0 |
| 10 | 5 | 8 | 0 |
| 11 | 5 | 8 | 0 |
| 12 | 5 | 8 | 0 |
| 13 | 5 | 8 | 0 |
| 14 | 5 | 8 | 0 |
| 15 | 5 | 8 | 0 |
Amazon SageMaker でモデルをトレーニングおよびデプロイする
クリーンなデータが得られたので、Amazon SageMaker を使用してモデルを構築、トレーニング、デプロイします。最初に、Amazon SageMaker で Jupyter ノートブックを作成して、コードの作成と実行を開始します。次に、S3 から Jupyter ノートブック環境にデータをインポートし、モデルのトレーニングに進みます。モデルをトレーニングするには、Amazon SageMaker に含まれている線形学習アルゴリズムを使用します。線形学習アルゴリズムは、分類と回帰の両方の問題に対するソリューションを提供していますが、この記事では、分類に焦点を当てます。次の Python コードは、モデルをロード、フォーマット、トレーニングする手順を示しています。
トレーニングジョブが完了したら、モデルをインスタンスにデプロイできます。これにより、予測リクエストをリッスンするエンドポイントを取得できます。次の Python コードを参照してください。
Amazon SageMaker エンドポイントの呼び出し
トレーニング済みのモデルがデプロイされたので、エンドポイントを呼び出して予測を取得する準備ができました。エンドポイントは、各クラスタイプのスコアと、最高スコアに基づいた予測ラベルを提供します。これで、アプリケーションに統合できるエンドポイントがあります。次の Python コードは、Amazon SageMaker ノートブックでエンドポイントを呼び出す例です。
エンドポイントが呼び出された後、応答が提供され、読み取り可能な予測にフォーマットされます。次のコードを参照してください。
クリーンアップ
続けて請求されるのを防ぐには、リソースをクリーンアップする必要があります。AWS Data Exchange から始めます。この例で使用するデータセットをサブスクライブした場合は、1 か月の試用期間の終了時に終了するようにサブスクリプションを設定します。この例で使用されているデータを保存している S3 バケットを削除します。AWS Glue クローラの結果として作成した AWS Glue データカタログを削除します。また、モデルのデプロイから作成した Amazon SageMaker ノートブックインスタンスとエンドポイントを削除します。
まとめ
この記事では、AWS Data Exchange と Amazon SageMaker を使用してマルチクラス分類子を構築、トレーニング、デプロイするワークフローの例を示しました。AWS Data Exchange を使用して、サードパーティのデータを使用して ML プロジェクトを開始し、Amazon SageMaker を使用して、組み込みのツールとアルゴリズムを利用して ML タスクのソリューションを作成できます。ML プロジェクトの初期段階にいる場合、または既存のデータセットを改善する方法を探している場合は、AWS Data Exchange をチェックしてみてください。データに取り組む時間を何時間も節約できることでしょう。
参考文献
- Géron Aurélien.Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems.OReilly, 2019.
- Tan, Pang-Ning, et al.Introduction to Data Mining.Pearson, 2006.
著者について
 Ben Fields は、ワシントン州シアトルに拠点を置くストラテジックアカウントのソリューションアーキテクトです。彼は AI/ML、コンテナ、ビッグデータに興味があり、その分野の経験を持っています。彼はよく、最寄りのクライミングジムでクライミングをしたり、近場のリンクでアイスホッケーをプレイしたり、温かい家の中でゲームをプレイしたりしています。
Ben Fields は、ワシントン州シアトルに拠点を置くストラテジックアカウントのソリューションアーキテクトです。彼は AI/ML、コンテナ、ビッグデータに興味があり、その分野の経験を持っています。彼はよく、最寄りのクライミングジムでクライミングをしたり、近場のリンクでアイスホッケーをプレイしたり、温かい家の中でゲームをプレイしたりしています。