Amazon Web Services ブログ
Category: AWS Glue

Apache Iceberg V3 の deletion vectors と row lineage でデータレイク操作を高速化する
Apache Iceberg V3 では deletion vectors と row lineage が導入されました。AWS は Amazon EMR、AWS Glue、Amazon SageMaker、Amazon S3 Tables、AWS Glue Data Catalog でこの機能を提供しています。本記事では、新機能の概要、業界横断のユースケース、AWS サービスでの実装方法を紹介します。

Amazon SageMaker レイクハウスアーキテクチャによる Amazon S3 上の Apache Iceberg テーブルの最適化設定の自動化
本記事は、2025 年 8 月 8 日に公開された The Amazon SageMaker lakehous […]
Zero-ETL: AWS によるデータ統合の課題への取り組み
このブログ記事では、Amazon Web Services (AWS) の Zero-ETL を活用することで、データ統合を簡素化すると同時に、パフォーマンスの向上やコストの最適化も実現する方法を紹介します。
AJA SSP が Apache Iceberg と AWS Glue Data Catalog でペタバイトスケールのデータ基盤の柔軟なクエリエンジンの選択とクエリの高速化を実現
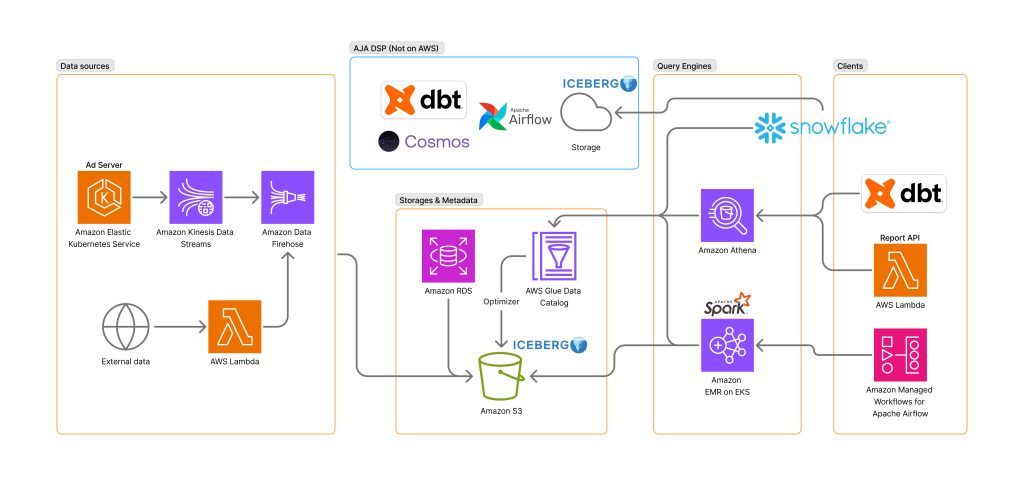
※ この記事はお客様に寄稿いただき、AWS が加筆・修正したものとなっています。 株式会社 AJA は、株式会 […]
物流業界のチャレンジを支えるデータ活用 – Nippon Express の事例から
物流業界において、特にデータを活用した改善は、物流DXとして総合物流施策大綱でも長年にわたり強く推奨されてきました。このような状況を受けて多くの物流企業がデータ活用を経営戦略の重要項目として位置付けているものの、実態としては有効な施策が打ち出せずにいるケースが多く見受けられます。
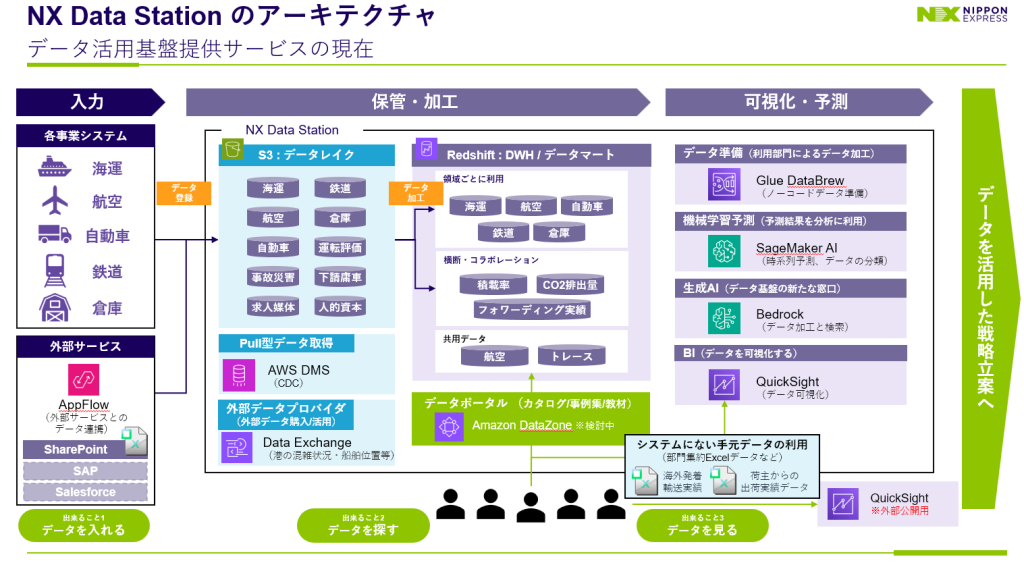
本記事ではそういった課題に悩まれる物流事業担当者向けに、データ活用の成功モデルとして日本通運株式会社(以下Nippon Express)のデータ分析基盤「NX Data Station」を解説します。同社は既存リソースを最大限に活用しながら、コスト効果の高いデータ分析基盤を構築し、データを基に業務効率化と意思決定の質向上を実現しています。
記事は2025年7月15日に開催された Amazon SageMaker Roadshow でのNX情報システム および キヤノンITソリューションズ のセッション内容をもとに記載しています。

【開催報告 & 資料公開】Apache Iceberg on AWS ミートアップ開催報告
2025 年 5 月 14 日に「Apache Iceberg on AWS ミートアップ ~話題のIcebergをAWSで徹底活用~」と題したイベントを開催しました。ご参加いただきました皆様には、改めて御礼申し上げます。
本セミナーでは、AWS における Iceberg の活用についてさまざまな角度からご紹介しました。Iceberg 活用の全体像に加えて、マネージドな Iceberg のストレージである Amazon S3 Tables Bucket、既存データレイクからの移行における考え方、リアルタイムデータ処理を実現するストリーミングワークロードの実装方法、更には機械学習における活用まで、幅広いトピックをご紹介しました。本ブログでは、その内容を簡単にご紹介しつつ、発表資料を公開致します。
すでに Iceberg を活用されている方も、これからはじめる方も是非ご確認下さい!

新機能: sort コンパクションと z-order コンパクションで Amazon S3 内での Apache Iceberg クエリパフォーマンスを向上
sort コンパクションと z-order コンパクションを使用して、Amazon S3 Tables と 汎 […]

ファーストパーティデータによる D2C (Direct-to-Consumer) マーケティングの実現:生成 AI によるパーソナライズされた体験の提供
消費財 (Consumer Packaged Goods) 企業が長期的な成功を収めるためには、考慮すべき点がたくさんあります。とりわけ、ブランドコントロールを維持し、利益率を改善し、顧客との良い関係を築く新しい方法を見つける必要があります。幸いなことに、生成 AI の出現により、消費財企業がこれらすべての課題に対処できるようになりました。。ただし、これは万能のアプローチではありません。AI を組織に導入するだけでは、最大のメリットは得られません。ビジネス目標に沿った戦略的アプリケーションを採用する必要があります。

AWS Lambda と AWS Glue Iceberg REST エンドポイントを使用した PyIceberg による軽量な分析環境の実現
Apache Iceberg は、データレイクで人気の選択肢となっています。ACID (原子性、一貫性、独立性、永続性) トランザクション、スキーマ進化、タイムトラベル機能を提供します。Iceberg テーブルは、Apache Spark や Trino などの様々な分散データ処理フレームワークからアクセスできるため、多様なデータ処理のニーズに対して柔軟なソリューションとなります。そのような Iceberg を扱うためのツールの中で、PyIceberg は分散コンピューティングリソースを必要とせずに、Python スクリプト上でテーブルのアクセスと管理を可能にします。
この投稿では、AWS Glue Data Catalog と AWS Lambda と統合された PyIceberg が、直感的な Python インターフェースを通じて Iceberg の強力な機能を活用するための軽量なアプローチを提供する方法を示します。この統合により、チームはほとんどセットアップやインフラストラクチャの依存関係の設定を行わずとも Iceberg テーブルの操作や利用を開始できることを説明します。

Apache Iceberg on AWS Glue Data Catalog における同時書き込み競合の管理
この記事では、Iceberg テーブルで信頼性の高い同時書き込み処理メカニズムを実装する方法を示します。Iceberg の同時実行モデルを探り、一般的な競合シナリオを検討し、自動再試行メカニズムと、カスタムの競合解決ロジックが必要な状況の両方の実用的な実装パターンを提供して、レジリエントなデータパイプラインを構築します。また、AWS Glue Data Catalog テーブル最適化による自動コンパクションのパターンについても説明します。