Amazon Web Services ブログ
Category: Analytics

Amazon MSK Express ベースのクラスターのオンデマンドスケーリングとスケジュールスケーリング
Amazon MSK Express ブローカーのインテリジェントリバランシング機能を活用して、CloudWatch メトリクスや事前定義されたスケジュールに基づいて Kafka クラスターを動的にスケーリングするソリューションを紹介します。オンデマンドスケーリングとスケジュールスケーリングの 2 つのアプローチで、パフォーマンスを維持しながらコスト効率を最適化できます。

リクルート『ホットペッパーグルメ』が Amazon OpenSearch Service で Hybrid Search を実現し検索体験を革新
株式会社リクルートは、日本国内で HR・販促事業を行う事業会社です。リクルートでは、満足度No1(*1)を誇る […]
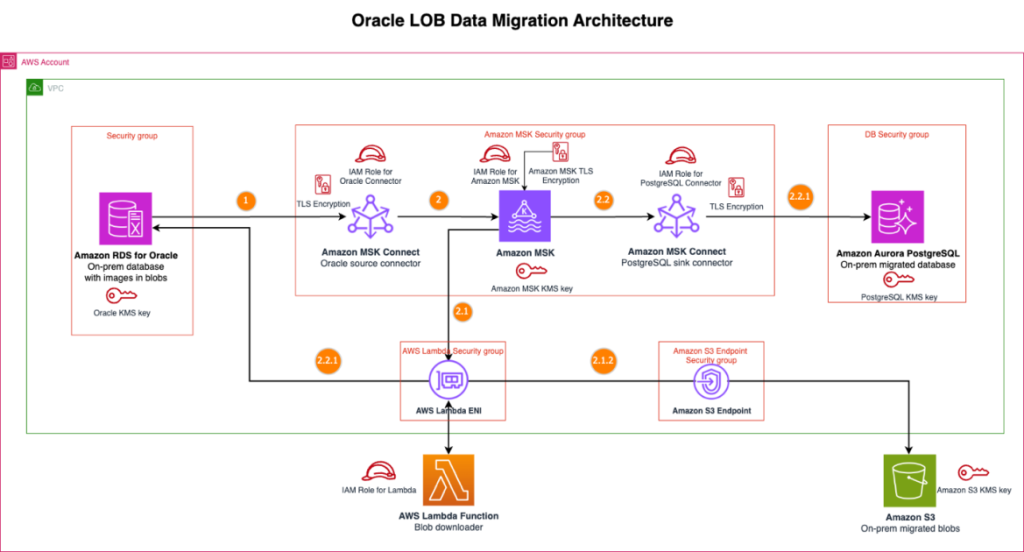
Oracle から Amazon Aurora PostgreSQL および Amazon S3 への大容量バイナリオブジェクト移行を効率化する Kafka ベースのソリューション
Amazon MSK、Amazon Aurora PostgreSQL-Compatible Edition、Amazon MSK Connect を使用して、Oracle データベースから AWS への大容量バイナリオブジェクト (LOB) 移行を効率化するストリーミングソリューションを紹介します。

Bazaarvoice が Amazon MSK で Apache Kafka インフラストラクチャをモダナイズした方法
Bazaarvoice は、セルフホスト型 Kafka から Amazon MSK に移行し、運用オーバーヘッドを削減しながら、セキュリティ、信頼性、パフォーマンスを向上させました。この記事では、移行プロセスと得られた教訓を紹介します。
寄稿:東京証券取引所が挑む膨大な取引データの処理 – AWS 活用で実現した次世代データ分析基盤
本稿は、株式会社日本取引所グループ(以下「JPX」)傘下の株式会社東京証券取引所(以下「東証」)による「膨大な […]
Amazon Q Business と Amazon Bedrock によるSAP データ価値の最大化 – パート 2
このシリーズのパート1では、Amazon Q BusinessとAmazon Bedrockの力を組み合わせて、SAP Early Watch Reportsから実用的なインサイトを得る方法、およびBusiness Data Automationを使用したIntelligent Document ProcessingをSAPシステムの請求書データ処理に使用する方法を検討しました。この投稿では、Amazon Bedrock Knowledge Bases for Structured Dataを使用して、SAPデータに関する質問に自然言語形式で回答する方法を実演します。

Amazon Kinesis Video Streams の warm ストレージ階層で長期動画保存コストを最適化
本記事は 2026年 1 月 4 日に公開された Optimize long-term video stora […]

AWS でのブロックチェーンインデクサーの構築
分散型金融 (DeFi) の取引判断には、ブロックチェーンの価格と流動性データが必要です。 しかし、ブロックチ […]

Amazon Redshift フェデレーテッドアクセス許可でマルチウェアハウスのデータガバナンスを簡素化する
Amazon Redshift フェデレーテッドアクセス許可を使用すると、複数の Redshift ウェアハウス間でデータアクセス許可を一度定義するだけで、自動的に適用できます。本記事では、RLS と DDM ポリシーを設定し、ウェアハウス間で一貫したセキュリティを実現する方法を紹介します。

Precisely を用いた Data Replication 構成例
AWS Mainframe Modernization Data Replicationは、Precisely社のCDC技術を活用し、メインフレーム(Db2、IMS、VSAM等)のデータをAWSクラウドへニアリアルタイムで同期するソリューションです。Apply EngineとAmazon MSKを組み合わせることで、メインフレームへの負荷を最小限に抑えながら、S3データレイクやRedshiftへの連携を実現します。