Amazon Web Services ブログ
Amazon Personalize を使用してレコメンドエンジンを作成する
本日のブログは、Inawisdom より AWS ソリューションアーキテクトのリードである Phil Basford 氏によるゲストブログ投稿です。
re:Invent 2018 にて AWS は Amazon Personalize を発表しました。これは初めてのレコメンデーションエンジンを迅速に稼働させることを可能にし、エンドユーザーやビジネスが価値を即座に実現できるようにするものです。データサイエンスへの理解が深まるほど (すでに理解している場合でも)、Amazon Personalize が持つ層の厚い機能を活用してレコメンデーションを改善していくことが可能です。
Inawisdom で働いていているうちに、私は機械学習 (ML) とディープラーニングの用途がますます多様化していることに気付きました。私はほぼ毎日、エキサイティングな新しいユースケースに取り組んでいますが、とても楽しいです。
最もよく知られている ML のユースケースの成功例には、小売業のウェブサイト、音楽ストリーミングアプリ、ソーシャルメディアプラットフォームがあります。これまで何年にもわたり、これらの業界ではユーザーエクスペリエンスの中心に ML テクノロジーを組み込んでいます。通常、履歴データポイントとリアルタイムのアクティビティ (クリックデータなど) に基づき、各ユーザーにカスタマイズしたレコメンドをそれぞれ提供します。
Inawisdom は幸運にも早期アクセスを与えられ、プレビュー期間であった Amazon Personalize を試してみることができました。それも、データサイエンティストやデータエンジニアではなく、AWS ソリューションアーキテクトの私にアクセスをくれたのです。予備知識もないのに、ほんの数時間で Amazon Personalize からレコメンドを取得することができました。この記事では、私が行った方法について説明します。
概要
リコメンデーションエンジンを構築する上で一番大きな挑戦は、どこから手を付ければよいかの判断が難しいことでしょう。ML の経験が限られている、あるいはほとんど経験がない場合には、さらに困難となります。ただし、以下に挙げることを自分が知らない (そして理解する必要がある)ということを認識していることは重要です。たとえば、
- どのデータを使用するか。
- どうやって構造化するするか。
- どのようなフレームワークやレシピが必要か。
- データを使ってどのようにトレーニングするか。
- 正しいかどうかを、どうやって知るのか。
- リアルタイムアプリケーション内で、どのように使用するのか。
大筋で言うと、Amazon Personalize はしくみを提供し、上記の事項を使ってユーザーを誘導しながらサポートしてくれます。あるいはデータサイエンティストであれば、実装のためのアクセラレータとして Amazon Personalize を利用することも可能です。
Amazon Personalize リコメンデーションソリューションの作成
ほんの数時間で、独自にカスタマイズした Amazon Personalize リコメンデーションソリューションを作成できます。次の図のプロセスを実行します。
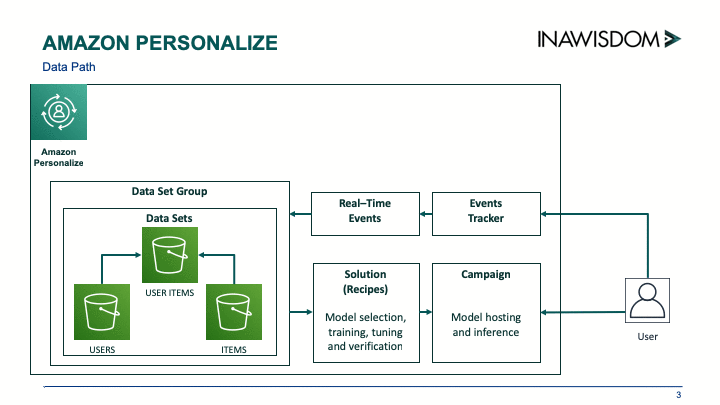
データセットグループとデータセットの作成
Amazon Personalize を開始する際にまず行うことは、データセットグループの作成です。履歴データの読み込み、またはリアルタイムイベントから収集したたデータから作成できます。Inawisdom で Amazon Personalize を評価するとき、履歴データのみを使用しました。
履歴データを使用すると、各データセットは Amazon S3 にある .csv ファイルからインポートしたデータになります。各データセットグループには 3 つのデータセットを含めることができます。
- ユーザー
- アイテム
- インタラクション
今回の簡単な例のために、インタラクションのデータファイルのみを用意しました。これは必須、かつ最も重要なファイルだからです。
インタラクションデータセットには、USER_ID を ITEM_ID にマッピングする多対多リレーションシップ (古いリレーショナルデータベースの用語) が含まれています。インタラクションは、それらの ID をリンクした追加データを含む任意のユーザーとアイテムデータセットでエンリッチ化することができます。映画ストリーミングのウェブサイトの場合だと、映画の年齢区分と視聴者の年齢を知り、どの年齢の視聴者がどの映画を視聴しているかを理解することは有益でしょう。
すべてのデータファイルを S3 で準備したら、それらをデータセットとしてデータグループにインポートします。これを行うには、各データセットに対して Apache Avro 形式のデータのスキーマを定義します。これで、Amazon Personalize はデータ形式を理解できるようになります。インタラクションのスキーマの例は、次のとおりです。
Amazon Personalize を評価する際、この段階でより多くの時間を費やすことになります。データの品質が使用可能で正確なモデルを作成する際の最大の要素であるため、これは重要なことなのです。この段階で、Amazon Personalize が即効性 (自分をサポートし、進歩を加速するのに重要な要素です) を持つものかどうかが決まるのです。
重要なのは識別したフィールドだけで、データ形式について心配する必要はありません。 使用するモデルや必要なデータに関しても、頭を悩ませる必要はありません。自分のデータをアクセス可能にすることだけに集中しましょう。ML を始めたばかりであれば、手際よく最小限のデータを使うだけでも基本的なデータセットグループを取得することができます。データサイエンティストであるなら、もう一度この段階に戻ってきて、もっと多くのデータポイント (データ機能) を追加することになるでしょう。
ソリューションの作成
データセットグループにデータが含まれている場合、ソリューションの作成が次のステップとなります。ソリューションはモデル (レシピ) を選択し、データを使ってそれをトレーニングするという 2 つの領域をカバーしています。レシピと Popularity-baseline から選択できます。以下では、レシピをいくつか提供しています。
- カスタマイズしたリランキング (検索)
- SIMS – 関連アイテム
- HRNN (Coldstart、Popularity-baseline、メタデータ) – ユーザーのカスタマイズ
データサイエンティストでなくても、心配ご無用です。AutoML を使用すれば、利用可能な各レシピに対するデータを実行できます。 次に、Amazon Personalize は取得した結果の正確性に基づいて、どれが最も良いレシピかを判断します。設定をいくつか変更することでも、より正確な結果 (ハイパーパラメータ) を得ることができます。 次の図の下部では、精度を示すメトリクスセクションを含むソリューションを示しています。
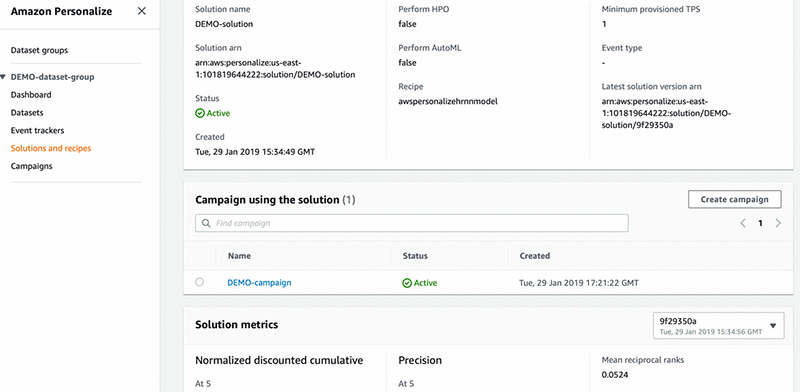
データサイエンティストでなくとも、Amazon Personalize ですばやい稼働が行えます。つまり Amazon Personalize を使うと、モデルの選択やトレーニングが必要でなくなるだけでなく、各レシピに必要なものにデータを再構築したり、トレーニングジョブを実行するのにサーバーをスピンアップする手間もなくなります。プロセスを完全に制御することができるようになるため、データサイエンティストにとってもよいことずくめです。
キャンペーンの作成
ソリューションバージョン (確認済みレシピとトレーニング済みアーティファクト) を入手したら、次は実行です。この部分は簡単ではなく、大規模に ML を稼働する上で考慮すべきことが数多くあります。
まず、Amazon Personalize でキャンペーン (レシピとトレーニング済みアーティファクトの推論エンジン) を PaaS としてデプロイします。キャンペーンは、レコメンドを作成するのに使用できる REST API を返します。以下に Python から API を呼び出す例を示します。
結果は次のようになります。
結論
Amazon Personalize は一連の AWS 機械学習サービスに追加できる優れた機能です。ご紹介したような Amazon Personalize の二面的アプローチにより、初めてのレコメンデーションエンジンの迅速かつ効率的な稼働が可能となり、その結果、お客様のエンドユーザーやビジネスが即座に価値を実現できるようになります。このようにして、Amazon Personalize の機能の深さと真の実力を活用し、より精度の高いレコメンドへ改善していくことができます。
Amazon Personalize は以下のリージョンで利用が可能となり、これらリージョンのあらゆる企業でレコメンデーションエンジンが利用できるようになりました。米国東部 (オハイオ)、米国東部 (バージニア北部)、米国西部 (オレゴン)、アジアパシフィック (東京)、アジアパシフィック (シンガポール)、および欧州 (アイルランド)。 おみごと、AWS!