Amazon Web Services ブログ
初めてのPerformance Insights入門 – その2
テクニカルソリューションアーキテクトの笹川です。
前回は初めてのPerformance Insights入門と題してPerformance Insightsの基本的な見方や使い方をご紹介させて頂きました。Performance Insightsで何が確認できるのか、待機イベントとは何か、Performance Schemaと何が違うのか、少しでもイメージできるようになって頂けていれば幸いです。
今回は少し進んでPerformance Insightsを使ってデータベースのパフォーマンスチューニングを行ってみましょう。データベースのパフォーマンスチューニングを行ったことがない、どう考えれば良いかわからない、どこから手をつけたら良いのかイメージできない、という方の為に比較的簡単な例をご紹介して説明して行きたいと思います。
検証環境と注意事項
本記事では下記の環境で検証を行なっていきます。
- RDS MySQL8.0.23
- db.m3.medium (1vCPU, メモリ3.75GiB)
- プロビジョンドIOPS (3000IOPS)
- マルチAZ設定有
尚、前回同様待機イベントはDBエンジン毎に異なり、バージョン間でも差異があります。また、Aurora MySQLとRDS MySQLでも異なる場合があるので今回の検証の結果がそのままAurora MySQLでも出力される訳ではないのでご注意下さい。インスタンスタイプも結果に大きく影響してくるため、その点もご注意下さい。
テストデータは前回ご紹介したこちらを引き続き使用していきます。既にデータがインポート済みの前提で進めますので、データのインポート方法について知りたい方は前回の記事をご覧ください。また、今回は検証の為に事前に下記SQLを流してemployeesテーブルのfirst_nameカラムにインデックスを追加しています。
OSで見える負荷とデータベースで見える負荷
実際に検証を進める前に、OSやデータベースのレイヤ毎に見える負荷について整理してみましょう。まずはOSで見える負荷を表すメトリクスについて考えます。OSの場合、CPUの使用率、メモリの使用率、ロードアベレージなどに当たります。例えば1vCPUのインスタンスでロードアベレージが3となっている場合、単純に解釈すると1つのvCPUに対して処理を行いたいプロセスが3つ存在している状態なので、プロセスの処理待ちが発生し全体として遅延している可能性があります。ここまでがOSである程度見えてくる負荷の状態となります。なぜプロセスが常時3つも待ってしまっている状態なのか、データベースのような複雑なソフトウェアでは、単純にロードアベレージだけを見ていても処理の遅延の原因は見えてきません。データベースの中でどのような理由で遅延が発生しているのか、これを詳細に確認できるのが前回ご紹介したPerformance Insightsで確認できる待機イベントとなってきます。待機イベントによってはトランザクションのロック待ちであったり、ストレージからのIO待ちだったり、状況によって様々なイベントが発生します。これをPerformance Insightsを使って発生している待機イベントと、それが起きる原因となっているクエリを特定することでチューニングすべき箇所について当たりを付けることができるようになってきます。
拡張モニタリング
OSのモニタリングをする為に今回は拡張モニタリングを使用していきます。拡張モニタリングを使用するとRDSのDBインスタンスで動いているOSのメトリクスをAWSコンソール上でリアルタイムにモニタリングすることができます。グラフの管理ボタンから表示させたいOSのメトリクスを選択して表示を絞ることも可能です。今回の例ではグラフの管理を使って必要なメトリクスに絞って検証を行なっていきます。OSとデータベース、それぞれのモニタリングでどこまで負荷の状況を確認できるか確かめながら検証を進めたい為、OSのモニタリングを拡張モニタリングで行い、データベースのモニタリングをPerformance Insightsで行いながらクエリのパフォーマンスチューニングを行なってみましょう。


シナリオ1 – CPU使用率が高く、ロードアベレージも高い状態

グラフの管理から未使用のメモリ、アクティブなメモリ、CPU合計、ロード平均5分(※ロード平均はロードアベレージのことです)の4つの項目に絞って拡張モニタリングを表示しています。OSの状態を確認すると、CPUをほぼ使い切っている状態で、ロードアベレージも1を超えています。1vCPUに対して平均4プロセス程度待っている状態となっている為、処理が遅延しているのではないかと考えられます。メモリも常に消費している状態となっています。拡張モニタリングによるOSレベルのメトリクスではここまで確認できたので、Performance Insightsでデータベースの詳細な状態を確認してみましょう。

 カウンターメトリクスから
カウンターメトリクスから600kもの大量の行が平均で取得されていることが確認できます。データベースのロードからも、大量の待機イベントが頻繁に発生していることが確認できます。大半を占めているのがwait/io/table/sql/handlerで、何らかの処理がテーブルに対するI/Oを頻繁に実行している為待機が発生していると考えられます。このグラフからCPUを消費していたのはI/Oの待機だったことが分かりました。問題となっているクエリを確認してみましょう。

トップSQLを確認すると、二つのパターンのクエリが確認できます。一つはLIKE句を使ったクエリ、もう一つはBETWEEN句を使っているクエリです。明らかにLIKE句のクエリの待機イベントが大きくなっている為こちらのクエリが原因となっていると考えられます。ここで、パフォーマンスチューニングに慣れている方はこのクエリの実行計画を確認すると思います。現在(2021年11月)Performance Insights上では実行計画を確認することができませんので、Performance Insights上で確認できる情報を頼りにパフォーマンスチューニングを進めます。Performance Insights上でクエリの構造を確認してみましょう。
first_nameカラムには検証環境と注意事項でご説明したように事前にインデックスを作成しています。インデックスが作成されているカラムに対して絞り込みを行っているのに、待機イベントが大きくなっているのはなぜでしょうか。実はLIKE句の場合、先頭にワイルドカード(%)が付いているとインデックスが作成されていたとしても使用されず、結局テーブルのフルスキャンが発生するようになってしまいます。クエリを下記のように修正して処理を流し直し、結果がどのように変わるか確認してみましょう。
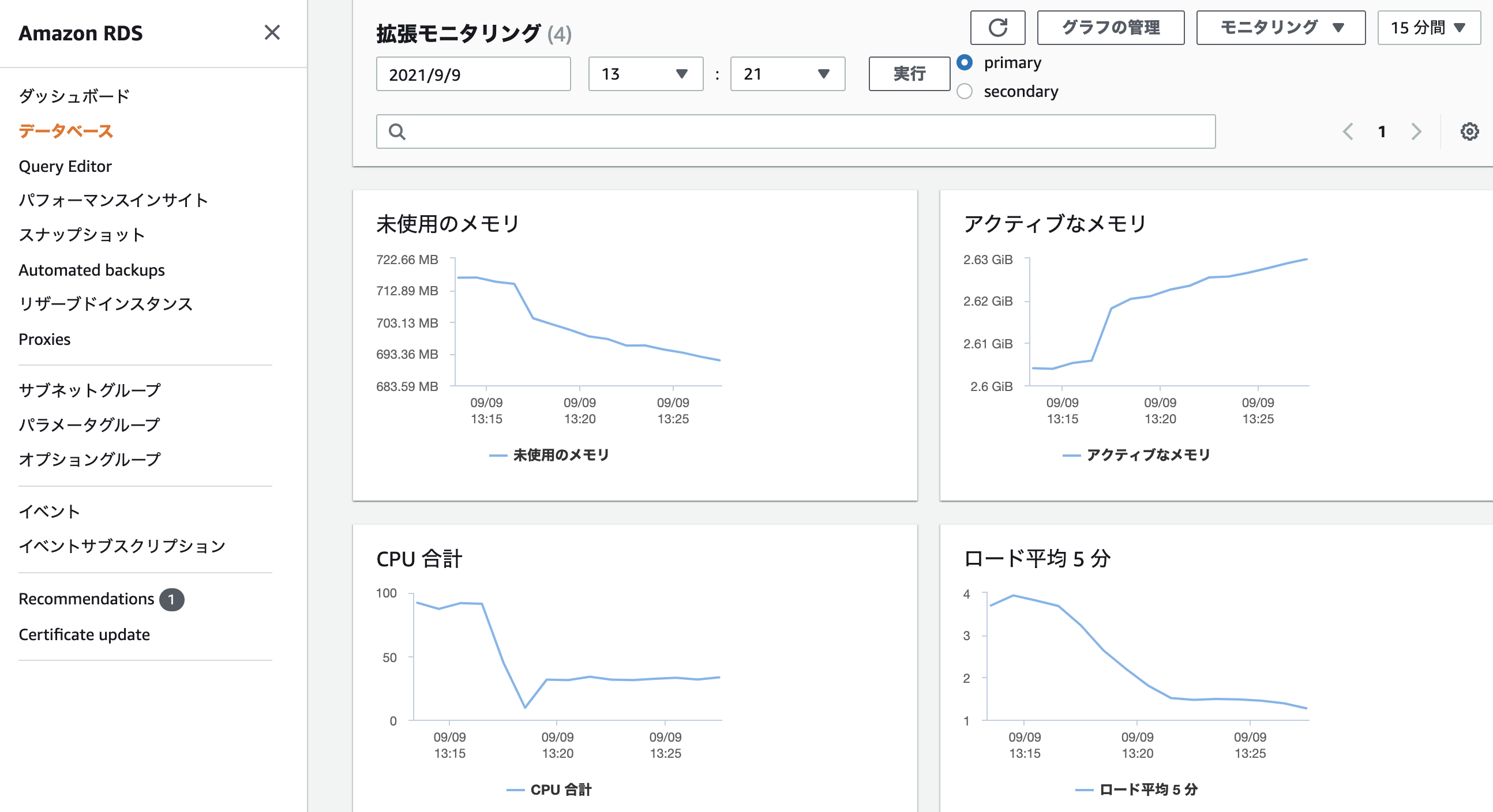
まずは拡張モニタリングを確認します。CPU合計が100近かったのが30程度に改善され、ロード平均5分も2以下までに下がり大幅に改善されています。メモリは引き続き消費し続けています。Performance Insightsも確認しましょう。



インデックスにより取得対象の行が絞り込まれて600kから40kにまで減っています。待機イベントもまだ発生していますが、頻度が大幅に改善されています。トップSQLの結果が特に顕著で、待機イベントの数値が3.42から0.33にまで大幅に改善されています。先の拡張モニタリングでも確認できたように、I/Oの待機が解消されることでCPUの消費も改善されることがわかりました。今回のLIKE句のように、インデックスが作成されているカラムを指定して絞り込んでいたとしても、インデックスが正しく使われない場合があります。そのようなケースに該当して待機イベントが発生してしまっていないか、Performance Insightsを活用して見直しを行ってみて下さい。
尚、先に記載した通り現在(2021年11月)Performance Insights上では実行計画を確認することができません。Performance Insightsで待機イベントを確認し、より詳細に実行されているクエリの情報も確認したい場合は実行計画も合わせて確認することを検討してみて下さい。
シナリオ2 – CPU使用率が一時的に高く、ディスクI/O待ちが発生している状態

今回はグラフの管理から未使用のメモリ、ディスクI/O待ち、CPU合計、ロード平均5分の4つの項目に絞って拡張モニタリングを表示しています。確認してみると、一時的にCPUが100近くまで跳ね上がっており、ロードアベレージも1に近い(今回の検証環境はdb.m3.medium (1vCPU))です。CPU消費が上がったタイミングでメモリも消費されています。さらに今回特徴的なことはディスクI/O待ちが上がっていることです。負荷が上がったタイミングで何か大きな処理が実行されたようですので、詳細を確認する為にPerformance Insightsを確認しましょう。


様々な待機イベントが表示されています。今回注目したい点はwait/io/file/innodb/innodb_data_fileやwait/io/file/sql/io_cache等、fileのI/Oに関する待機イベントが発生していることです。先程のOSのメトリクスから判断できる通りディスクに対するI/O待ちが発生していた為、何かメモリに収まりきらない大きなデータのロードやそのデータに対する処理が実行されてディスクIOが発生したのではないかと推測してみます。問題となったSQLを確認してみましょう。
前回も登場した、employeesテーブル, dept_empテーブル, departmentsテーブル, salariesテーブル, titlesテーブルを結合した上で従業員の指名, 所属部門, 給与, 役職名を表示させるクエリに、追加で入社日の取得、さらに入社日を昇順でソートさせています。ここでソートについて考えてみます。MySQLはソート用のメモリ領域を確保してソート処理を実行するのですが、データが大きすぎてメモリに収まりきらない場合は一時ファイルを作成してソート処理を行います(filesort)。ソート用のメモリ領域の大きさを指定できるsort_buffer_sizeパラメータを確認してどれくらいのメモリがソート処理に使われるのか確認してみましょう。
このインスタンスの場合、検証時では特に設定を変えなかった場合sort_buffer_sizeは262144(262k)程度だということがわかりました。前回この大きなクエリ実行時の取得行の合計数は500万行程だったことを思い出すとsort_buffer_sizeは少なく見えます。前述したように、sort_buffer_sizeはMySQLがソートの際に使用するバッファで、この値が実際にソートする量よりも小さいと何度もディスクにI/Oしながら処理することになります。クエリ実行時の取得行が多くても、バッファに収まるようにsort_buffer_sizeを大きくすべきと考えました。そこで、思い切ってsort_buffer_sizeに20971520(20MB)くらい大きな値を設定して結果がどう変わるか検証してみましょう。RDSではパラメータグループを使ってsort_buffer_sizeを変更できます。パラメータグループからsort_buffer_sizeを変更し、インスタンスを再起動してから再度クエリを実行して結果を確認してみます。
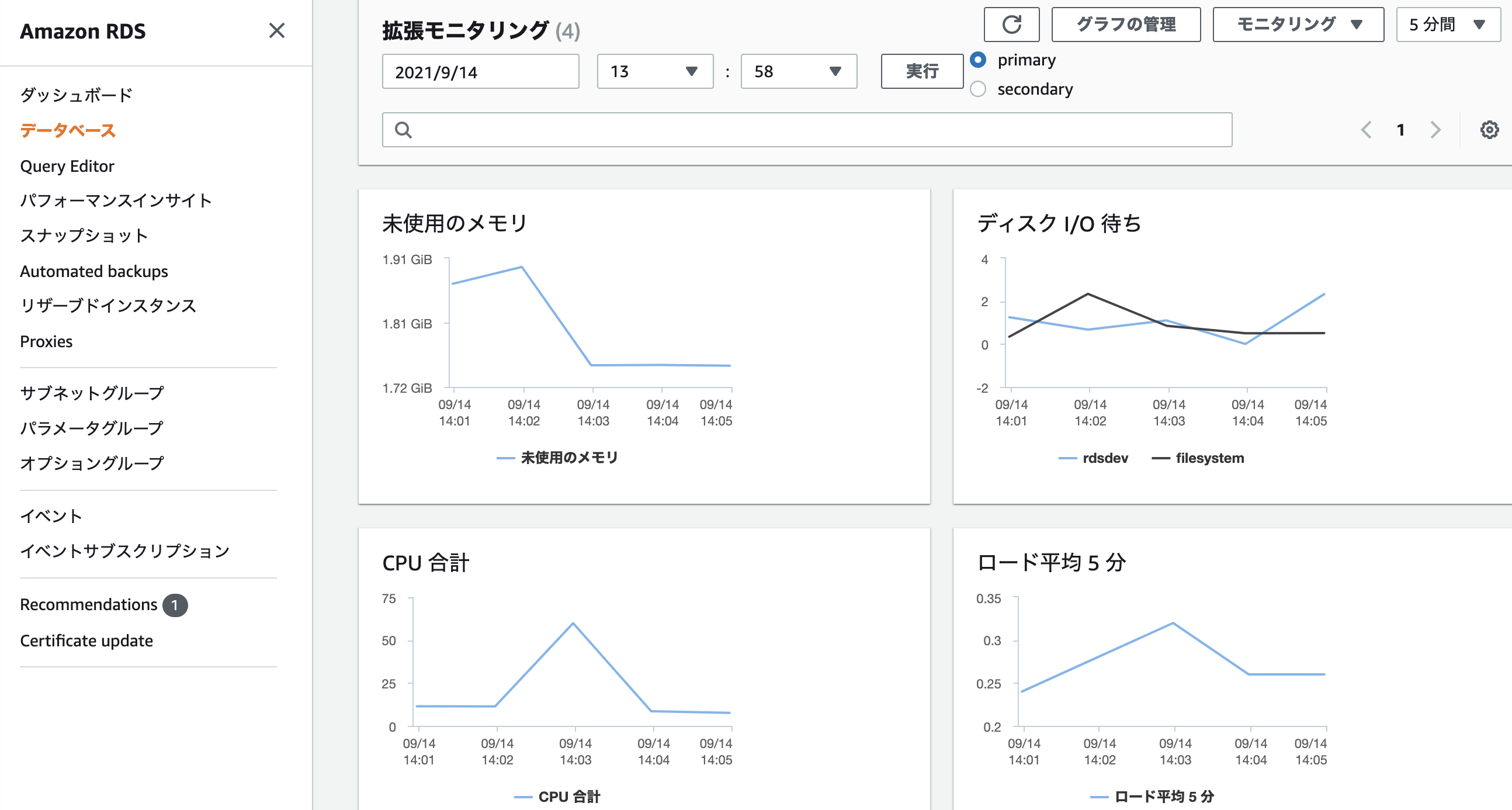
まずは拡張モニタリングから確認すると、CPU合計も最大で60程、ロード平均5分も最大で0.3程度と改善されています。特にディスクI/O待ちがほとんど発生しなくなり、大幅に改善されているようです。次にPerformance Insightsで待機イベントがどのように変わったか確認してみましょう。

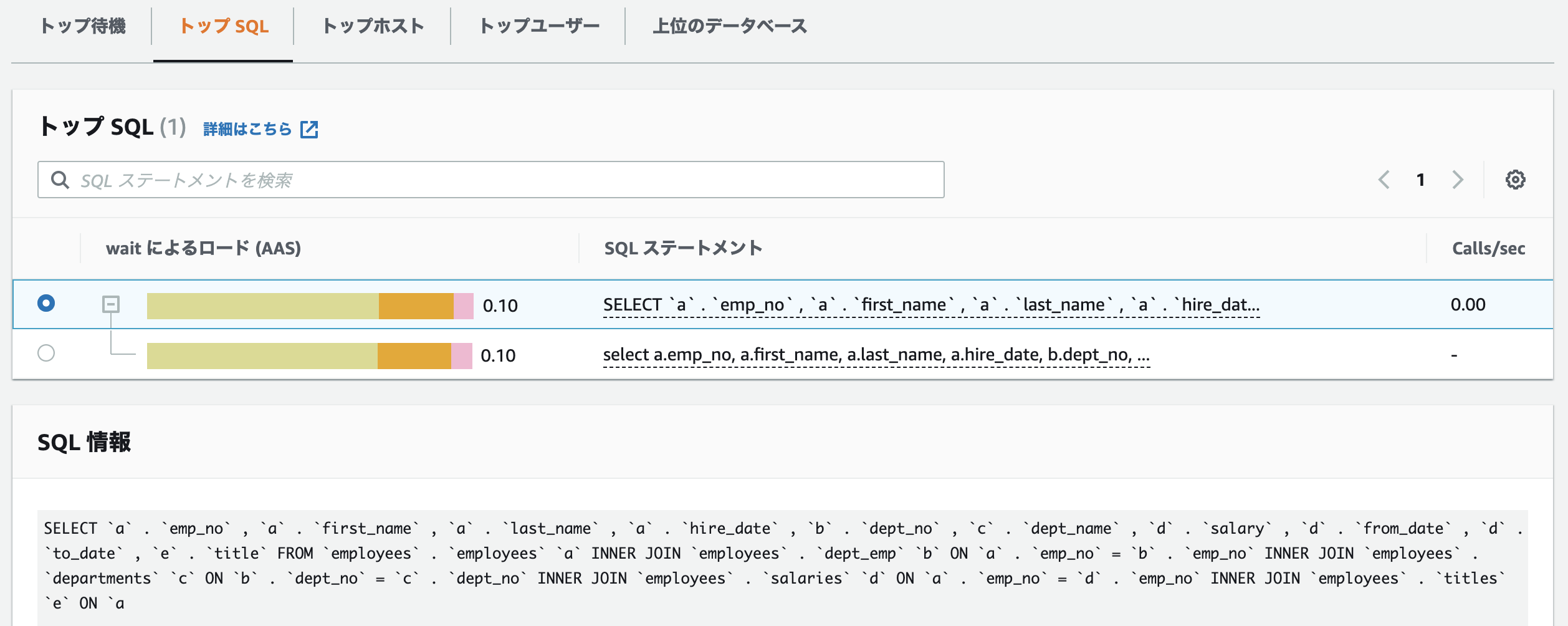
Performance Insightsを確認すると、wait/io/file/innodb/innodb_data_fileはまだ多少発生しているもののwait/io/file/sql/io_cacheは表示されなくなりました。待機イベントの数値も0.38から0.10に改善されています。どうやら今回はsort_buffer_sizeを調節することがパフォーマンスの改善に繋がりそうなことが分かりました。
このシナリオではクエリのチューニングでは無く、MySQL自体のパラメータのチューニングを行い結果がどう変わるか検証してみました。実際のwebシステム等ではこれほど大量のデータをソートするのではなく、件数を絞ってソートをすることの方が多いと思います。ですがバッチ処理や分析系のクエリなどでは大量のデータに対してソート処理を行うということも考えられそうです。そういった時はクエリのチューニングも行いつつsort_buffer_size等のMySQL自体のパラメータをチューニングしてみるというアプローチも効果的なことがあります。その際は今回の検証の様に拡張モニタリングやPerformance Insightsの結果を確認しながらチューニングを行なえば効率的に作業を進められることでしょう。
尚、今回は検証の為sort_buffer_sizeだけに大きな値を設定しましたが、一つのパラメータの変更が他の処理に予期しない影響を与える可能性があります。その為、パラメータの変更は必ず検証しながら慎重に設定することを心がけて下さい。細かいパラメータのチューニングはAWSのブログでも解説しておりますので、ご興味を持った方は是非確認してみて下さい。
まとめ
拡張モニタリングとPerformance Insightsを使ってパフォーマンスチューニングをしてみましたが、いかがでしたでしょうか。今回のシナリオは二つともCPUを使い切るシナリオだった為、OSの状態からなんとなく問題が起きていそうかもしれないと推測できるものでした。次回はOSのメトリクスだけ見ても問題が起きているのか判断が難しいパターンのシナリオを考察しながら、Performance Insightsを活用してパフォーマンスチューニングを行ってみたいと思います。