Amazon Web Services ブログ
AWS上でSustainability Insights Framework (SIF) を使う方法
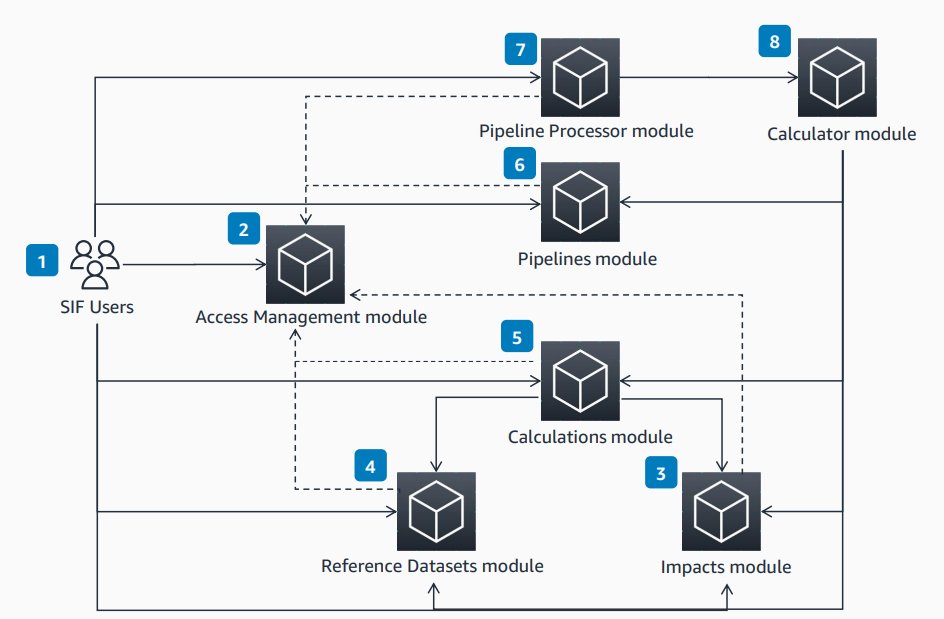
AWS Sustainability Insights Framework(SIF)は、組織がAWS上で炭素排出量を自動的に追跡し、気候関連レポートを作成するためのスケーラブルなソフトウェアプラットフォームです。従来の手動プロセスに代わり、モジュラーアーキテクチャを通じてデータ収集・計算・報告を自動化します。人的エラーの削減、動的なスケーリング、進化する規制への適応という3つの利点を提供し、あらゆる規模の組織のサステナビリティ報告を支援します。

Amazon RDS ブルー/グリーン デプロイを使用した Amazon Aurora PostgreSQL アップグレードのロールバック戦略の実装
本記事は、2025 年 6 月 20 日に公開された Implement a rollback strateg […]

ランサムウェア対策ワークショップ開催報告 & Claude Mythos をテーマにしたワークショップ緊急開催のご案内
みなさん、こんにちは。ソリューションアーキテクトの田村です。 サイバー攻撃の脅威は質的に変化しています。AI […]

AWS 初学者向けの勉強方法 7 ステップ ! 2026 年版 !
みなさん、もしくはみなさんの周りで「AWS を勉強したいんだけど何から勉強すればよいだろう。どこかに勉強方法がまとまってないかな ?」「同僚や部下に AWS の勉強を促しているけど、ちょうど良い教材とか無いかな ?」という悩みを抱えている方はいませんか ? このブログはそういった AWS を勉強する際の悩みを抱えた AWS 初学者の方や、AWS 初学者を育成する立場にある方を対象にしています。
どのような段取りで知識を深めていけばよいのか、この勉強方法がなぜおすすめなのか、疑問点やハマりどころに直面した際にどこのサイトをチェックすればいいのか、など納得しながら勉強を進められるように具体的な情報を含めながら 7 ステップで紹介していきます。

Kiro アンバサダープログラムのご紹介
先日、開発者コミュニティが互いに発見し、つながり、よりよいものを作るための場として Kiro コミュニティハブと Kiro Labs をローンチしました。すでにギャラリーにプロジェクトを投稿したり、これから開催するイベントをシェアしたりする動きが始まっています。今日はそこからもう一歩踏み込みます。Kiro Ambassadors は、フィードバックを寄せ、コンテンツを発信し、他のビルダーを支えてくれる、最もアクティブな開発者のみなさんとの関係を公式なプログラムにしたものです。すでに Kiro を前に進めてくれていて、これからの方向性にも直接関わりたいと考えている開発者のための仕組みです。Kiro を実際のワークフローの一部として使っている開発者の影響力とインパクトを、さらに広げていきたいと考えています。

AI エージェントアプリケーションを構築する次世代 Amazon OpenSearch Serverless の発表
AI エージェント向けにフルマネージドの検索およびベクトルエンジン、次世代 Amazon OpenSearch Serverless を発表します。コンピューティングリソースをゼロから 1 秒あたり数千リクエストを処理できる規模までスケールアップし、アイドル時はゼロまでスケールダウン。ピーク容量にプロビジョニングしたクラスターと比べて最大 60% のコスト削減を実現します。

次世代の Amazon OpenSearch Serverless: エージェント向けにゼロから構築
Amazon OpenSearch Serverless のアーキテクチャをゼロから刷新し、オートスケーリングが従来比で最大 20 倍に高速化、コンピューティングをゼロまでスケール可能、ピーク負荷に合わせたプロビジョニングと比べて最大 60% のコスト削減を実現した次世代アーキテクチャ NextGen を発表します。コンピューティングとストレージを完全に分離し、エージェントワークロードに最適化されました。本記事ではアーキテクチャの仕組みと、ハンズオンチュートリアルでの使い始め方を解説します。

Chronos-2 の紹介:単変量予測の先へ — 多変量も共変量もゼロショットで
Chronos-2は、Amazonが開発した時系列予測の基盤モデルです。従来の単変量予測に加え、多変量予測や共変量を活用した予測をゼロショットで実現します。コンテキスト内学習により、追加学習なしで多様な予測タスクに対応し、既存モデルを大幅に上回る性能を達成しました。

Physical AIのためのデータ収集基盤を構築する①:模倣学習データの完全性を保証させるエッジシステム
みなさん、こんにちは。株式会社 APTO で Physical AI のデータ基盤を構築している田中です。 近 […]

AWS Weekly Roundup: イスタンブールの AWS ローカルゾーン、オープンソースの ExtendDB、Kiro Web など (2026 年 5 月 25 日)
スタートアップとの仕事には、本当に刺激的な何かがあります。私は 2 年以上にわたって、このような仕事に精力的に […]