Amazon Web Services ブログ

ExtendDB のご紹介: プラガブルなストレージバックエンドを備えたオープンソースの DynamoDB 互換アダプター
本記事は 2026 年 05 月 20 日に公開された “Introducing ExtendDB […]

学生たちが8週間で築いた確かな成長──大学生プログラミングコミュニティ 「POSSE」2026年チーム開発決勝レポート
大学生向けのプログラミング学習コミュニティ「POSSE」では、実践的な開発スキルやチームワークの向上を目指して […]
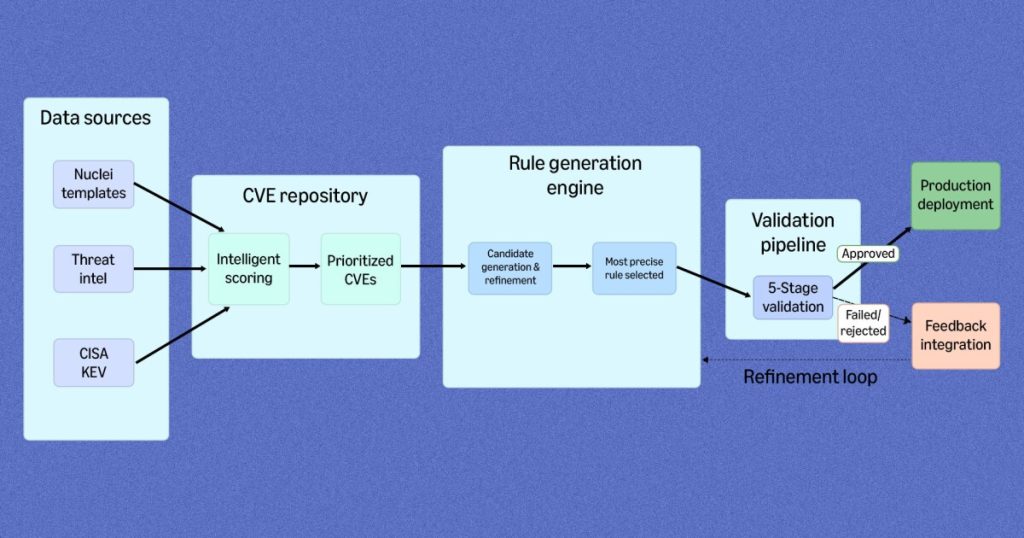
エージェンティック AI でグローバル規模の脆弱性検出を加速
Amazon が開発した RuleForge は、エージェンティック AI を活用して脆弱性検出ルールを自動生成するシステムです。ルール生成エージェントとジャッジモデルを分離するアーキテクチャにより、誤検知を 67% 削減しつつ、従来の手動プロセスと比較して 336% 速くルールを生成・検証できるようになりました。CVE 開示から防御までのギャップを埋め、AWS のお客様のワークロード保護を強化する仕組みを解説します。

Amazon Connect Customer: 中国への発信におけるコンプライアンスのベストプラクティス
Amazon Connect Customer を使用して中国 (国番号 +86) へコンプライアンスに準拠した発信を行うための 5 つのベストプラクティスを紹介します。承認済み DID 番号の設定、禁止番号タイプの排除、レート制限、発信者 ID の設定、番号検証の実装について説明します。

生成 AI を活用した SRE レジリエンスジャーニーを支援する次世代 AWS Resilience Hub のご紹介
2026 年 5 月 28 日、各種機能を大幅に強化した次世代の AWS Resilience Hub を発表 […]

最新の AWS ヒーローのご紹介 – 2026 年 5 月
4 名の傑出したコミュニティリーダーを、最新の AWS ヒーローとしてお迎えできることを大変うれしく思います。 […]

週刊生成AI with AWS – 2026/5/25週
週刊生成AI with AWS,AWS Summit Japan まで1ヶ月を切った2026年6月1日号 – JPX総研様がAmazon BedrockとOpenSearch Serviceで構築したAI開示情報検索サービス「J-LENS」の寄稿記事、Physical AIのためのデータ収集基盤の解説記事含む5件のブログ記事を紹介。サービスアップデートでは、Claude Opus 4.8の提供開始、次世代Amazon OpenSearch Serverlessの一般提供開始、P5.48xl/P4deインスタンスの東京リージョン拡大含む9件を紹介。

週刊AWS – 2026/5/25週
Amazon OpenSearch Serverless 次世代版が GA、Amazon WorkSpaces Applications が Windows Desktop OS をサポート、Claude Opus 4.8 が Amazon Bedrock および Claude Platform on AWS で利用可能に、AWS Organizations がアカウントメンバーシップ変更の CloudTrail イベントを自動記録、AWS Interconnect multicloud に 500 Mbps の無料枠を提供開始等

AWS Transform と MGN レプリケーションエージェントインストール自動化による VMware マイグレーションの加速
オンプレミスの VMware 環境から AWS への数百台のサーバー移行には、チーム、アカウント、ツール間の調整が必要です。ターゲット環境のセットアップ、ウェーブの計画、レプリケーションエージェントのデプロイ、進捗の監視、テストの実行、カットオーバーの実施が必要であり、多くの場合、複数の AWS アカウントにまたがります。各ステップはそれ自体が困難であり、マイグレーションを成功させるためには全体を通じた慎重な計画と調整が求められます。
AWS Transform は、これらのステップを単一の AI アシスト付きリホスト (リフトアンドシフト) ワークフローに統合します。AWS Transform は AWS Transform for VMware のマイグレーションライフサイクル全体のオーケストレーション機能を基盤とし、プロセスの各ステップで対話型 AI ガイダンスを提供します。
満員御礼! Claude Code による開発体験ワークショップ【イベントレポート】
アマゾン ウェブ サービス ジャパンのソリューションアーキテクト、齋藤です。 NHN テコラス様が主催する「は […]