Amazon Web Services ブログ

【開催報告】ランサムウェアに備える「防御」と「復旧」— AWS で実現するセキュリティ対策セミナーを開催しました!(2026 年 5 月 21 日)
2026年5月21日、「ランサムウェアに備える『防御』と『復旧』— AWS で実現するセキュリティ対策」セミナーを開催しました。AWS サービスによる防御・検知・復旧の具体策と、パートナー3社によるエンドポイント・ネットワーク・運用支援をご紹介。各セッションの概要をレポートします。
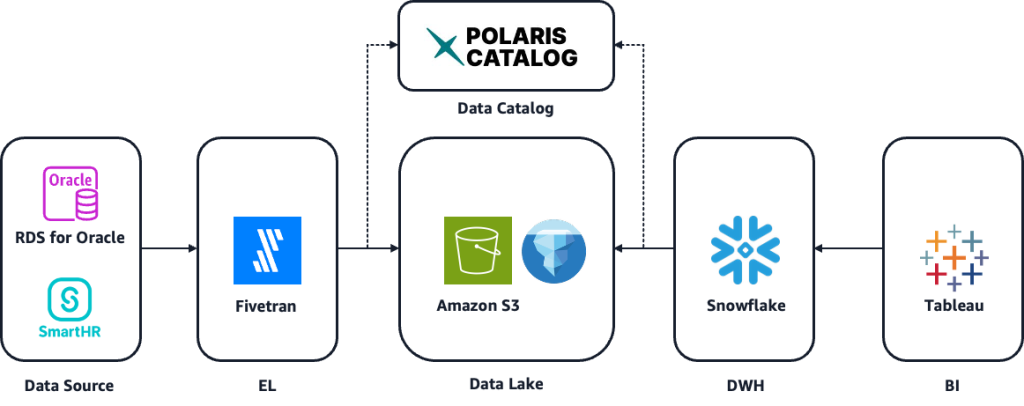
Fivetran の CDC 機能で実現するラーメン山岡家の Iceberg on AWS データパイプライン
ラーメンチェーン「山岡家」を展開する株式会社丸千代山岡家が、Fivetran の CDC(Change Data Capture)機能を活用して Amazon RDS for Oracle から Amazon S3 上の Apache Iceberg テーブルへのデータ同期を実現した事例をご紹介します。アーキテクチャの検討プロセスや Fivetran 採用の理由、約 5 分のデータ反映、月あたりの運用工数を 6 日から 0.5 日に削減、PoC から本番稼働まで約 1 ヶ月という短期導入といった導入効果を解説します。
AWS KMS と AWS Encryption SDK が対称暗号化の境界を克服する仕組み
大量のデータを暗号化する大規模アプリケーションでは、AES-GCM の暗号化限界の追跡や鍵のローテーションが課題になります。本記事では、AWS KMS と AWS Encryption SDK が派生鍵方式を用いて、暗号化のたびに一意の鍵を生成し、AES-GCM の呼び出し限界やデータ境界を自動的に処理する仕組みを解説します。鍵導出関数 (KDF) やノンスの活用により、手動管理を不要にする方法を詳しく説明します。

サーバーレス関連の見逃し情報 2025 年第 4 四半期
お知らせ 2026年7月からオンラインでサーバーレスに関するワークショップを4件開催します。ぜひ、ご参加くださ […]

【開催報告】データから業務アクション、展開まで繋げる Amazon Quick ワークショップ in 大阪
2026 年 5 月 29 日、AWS ジャパン 大阪オフィスにて「AWS Business Innovation Series – West Japan」の第 2 回を開催しました。AI ワークアシスタント「Amazon Quick」をテーマに、座学・ハンズオン・ハッカソンの 3 ステップでデータ接続からエージェント構築までを体験いただき、参加者全員が半日で自社業務に活用できるチャットエージェントを作り上げました。当日の様子と参加者の声をお届けします。

AWS Transform Custom を使用した VB6 アプリケーションのモダナイズ
この記事では、AWS Transform custom のエージェンティック AI 機能を活用して、組織固有のビジネスルールを維持しながら VB6 アプリケーションを大規模にモダナイズする方法を紹介します。

AWS Weekly Roundup: AWS での Claude Opus 4.8、Kiro Powers を利用する Aurora MySQL など (2026 年 6 月 1 日)
私の前回の Week in Review の記事では、私が開催している AI-Driven Developme […]

AI の脅威からオープンソースを守るため 1,250 万ドルを AWS など複数社が拠出
AWS、Anthropic、Google、Microsoft、OpenAI は Linux Foundation と共同で 1,250 万ドルを拠出し、AI による脆弱性レポートの急増からオープンソースエコシステムを守る取り組みを発表しました。基盤モデルが重大な脆弱性発見でセキュリティ研究者を上回り始めるなか、AWS は Alpha Omega を通じてメンテナーがバグを迅速に検証・修正できるツールと自動化を提供します。
AWS Summit Japan 2026 における Database 関連の注目セッションのご紹介
日本最大の「AWS を学ぶイベント」、AWS Summit Japan が 2026年6月25日(木)、26日 […]

9 社合同 AI-DLC Unicorn Gym 大阪 ── AI と開発した 3 日間で見えた、人間の仕事
みなさん、こんにちは。ソリューションアーキテクトの池田、ポール、佐山です。 2026 年 5 月 18 日〜2 […]