Amazon Web Services ブログ

週刊生成AI with AWS – 2026/6/1 週
6月1日週の生成AI関連アップデートをまとめてお届けします。注目は、OpenAI の GPT-5.5・GPT-5.4・Codex が Amazon Bedrock で一般提供を開始したことです。各社のモデルを共通のセキュリティ・ガバナンスのもとで選べる環境が、さらに広がりました。あわせて、新しいコンソールや CloudWatch メトリクスといった Bedrock 周りの強化、SageMaker や Step Functions、HealthOmics の新機能も取り上げています。

キャパシティ対応推論:SageMaker AI エンドポイントにおけるインスタンスの自動フォールバック
本ブログは “Capacity-aware inference: Automatic instan […]

AI 時代におけるセキュリティ体制の強化
Anthropic が Claude Mythos Preview モデルを発表し、AWS およびその他の主要組織と共に Project Glasswing を立ち上げてから、まだ数週間しか経っていません。これにより、サイバーセキュリティの将来と、基盤モデルの能力が急速に向上することが組織にとって何を意味するのかについて、多くの議論が生まれています。
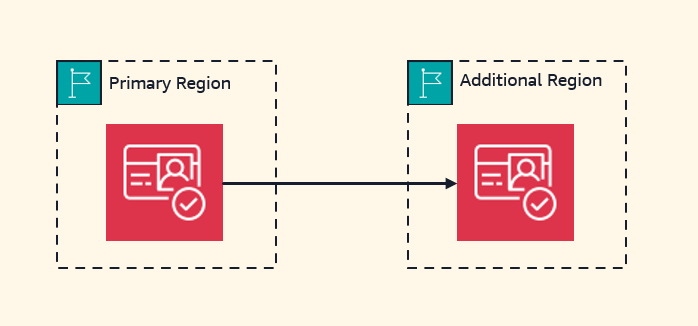
Amazon Cognito マルチリージョンレプリケーションを利用して、アプリケーションの回復力の向上を実現
ウェブアプリケーションおよびモバイルアプリのデベロッパーと連携するデベロッパーアドボケートとして、私は、リージ […]

Amazon Bedrock 上で OpenAI の GPT-5.5 モデル、GPT-5.4 モデル、Codex の使用を開始する
OpenAIの最先端モデルであるGPT-5.5とGPT-5.4、そしてOpenAIのコーディングエージェントであるCodexが、Amazon Bedrockで一般提供開始となりました。Bedrockの高性能推論エンジンに、セキュリティ、ガバナンス、トークン単位の料金体系を組み込んだ状態で、最先端モデルをデプロイできます。

ポスト量子暗号で将来の量子リスクからシークレットを守る
AWS Secrets Manager が ML-KEM を使用したハイブリッドポスト量子鍵交換をデフォルトで有効化しました。これにより harvest now, decrypt later (HNDL) 攻撃から将来の量子コンピュータの脅威に備えてシークレットを保護します。Secrets Manager Agent、Lambda 拡張機能、CSI Driver、各種 AWS SDK のアップグレード要件と、CloudTrail を使った接続検証手順を詳しく説明します。

2026年1月〜5月の AWS オブザーバビリティ関連リリースまとめ
AWS オブザーバビリティ関連リリースまとめの第1回へようこそ!2026年の最初の5か月間は、AWS オブザーバビリティにとって大きな変革をもたらした期間となり、 Amazon CloudWatch 、 AWS X-Ray 、 Amazon Managed Grafana 、 Amazon Managed Service for Prometheus にまたがって40を超えるリリースが行われました。この期間を特徴づける2つの大きなテーマは、統一された計装標準である OpenTelemetry 対応を強化したことと、オブザーバビリティを誰もが利用できるようにする AI 駆動のオペレーション です。EKS上でコンテナを実行している方も、複数リージョンにまたがるデータベースを管理している方も、AI 支援のワークフローを構築している方も、ここには役立つ情報があります。

Amazon ElastiCache for Valkey の耐久性機能のお知らせ
本ブログでは、Amazon ElastiCache for Valkey の新機能である耐久性(Durability)についてご紹介します。この機能により、ElastiCache をキャッシュだけでなく永続的なデータストアとしても利用できるようになります。同期書き込みではデータ損失ゼロを実現し、非同期書き込みではマイクロ秒の書き込みレイテンシーを維持しながら最大10秒のデータ損失リスクに抑えます。Multi-AZ トランザクションログを使用したアーキテクチャ、パフォーマンス測定結果、AWS CLI を使った具体的な設定方法まで詳しく解説します。

Amazon Auroraにおけるバックアップの仕組みを理解する
Amazon Aurora のバックアップアーキテクチャの内部メカニズム、Amazon RDS バックアップとの違い、CloudWatch メトリクスによる監視方法を解説します。ワークロードパターンと保持期間がバックアップコストに与える影響をシナリオで示し、クロスリージョンバックアップの選択肢とストレージ消費量の最適化プラクティスを紹介します。

月刊 AWS 製造 2026 年 6 月号
日本の製造業のお客様に向けて、AWS の最新情報を毎月お届けするブログシリーズです。今号では、6月開催の AWS Summit Japan 2026 の製造業向け展示の見どころを中心に、Hannover Messe 2026 のブースレポート、トヨタ・Volkswagen 等のグローバル事例など5月の製造業×クラウド関連トピックを幅広くまとめています。