Amazon Web Services ブログ

株式会社八十二長野銀行の AWS 人材育成: 4 ヶ月間の伴走支援型人材育成で実現したクラウド人材の輩出 (AWS Certified Solutions Architect – Associate に 17 名合格)
本稿は株式会社八十二長野銀行と AWS Japan の共同執筆により、AWS 人材育成プロジェクトを通じて得ら […]

AWS オムニチャネルフォールバックソリューションへの LINE Messenger の追加
AWS オムニチャネルフォールバックソリューションに LINE Messenger を統合する方法を解説します。アーキテクチャの変更点、LINE Messaging API チャネルの作成手順、デプロイとテストの手順を説明します。LINE をプライマリまたはフォールバックチャネルとして活用することで、日本・台湾・タイの主要市場のユーザーへのリーチを拡大できます。

2026 AWS Life Sciences Symposium ハイライト:創薬研究領域
英語版ブログ: “ Highlights from the 2026 AWS Life Sciences Sy […]

AWS Lambda durable functionsを使用した耐障害性アプリケーションの構築
お知らせ 2026年7月からオンラインでサーバーレスに関するワークショップを4件開催します。ぜひ、ご参加くださ […]

AWS Summit Japan 2026 〜 流通小売・消費財・飲食業界向けブースのご案内
こんにちは。流通小売・消費財・飲食業界を担当するソリューションアーキテクトチームです。いよいよ 6 月 25 […]

AWS Weekly Roundup: BYOM for Amazon RDS for SQL Server、AWS IoT Device SDK for Swift など (2026 年 6 月 8 日)
2026 年 6 月 8 日週、AWS IoT Device SDK for Swift が一般公開されました […]
-1-1024x538.png)
広告取引のデータ転送コストを80%削減 — fluctとUNICORNがAWS RTB Fabricで挑んだ広告配信ビジネスのジレンマ解消の軌跡
プログラマティック広告(※)に携わる DSP(Demand-Side Platform)・SSP(Supply […]
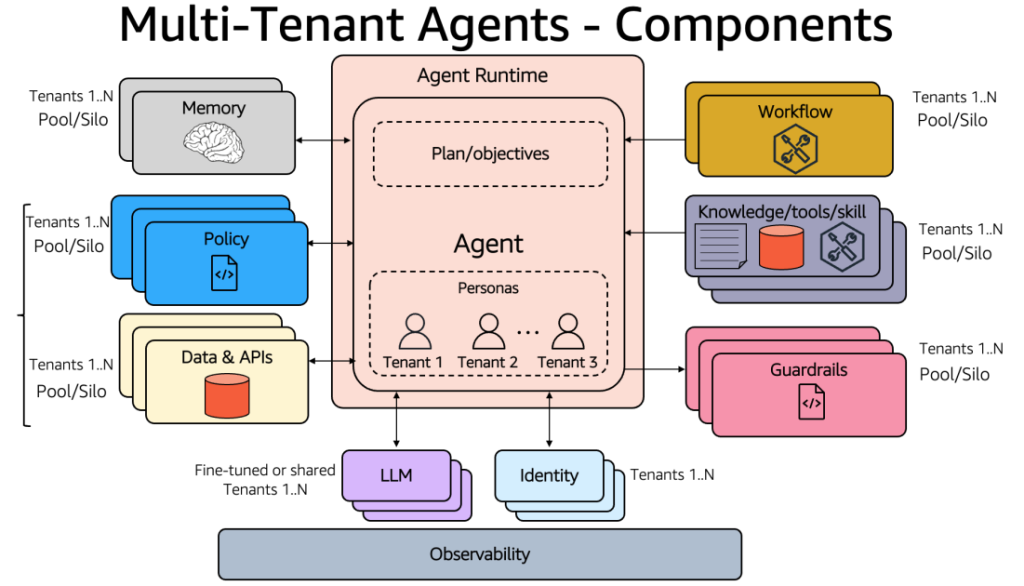
Amazon Bedrock AgentCore でマルチテナントエージェントを構築する
マルチテナントのエージェント型アプリケーションを構築する SaaS プロバイダーは、テナント分離、ID 管理、コスト配分、ノイジーネイバーの緩和といった課題に取り組む必要があります。本シリーズ第 1 回となる本記事では、Amazon Bedrock AgentCore でマルチテナントエージェントを設計する際の検討事項と、サイロ、プール、ブリッジの各デプロイモデルの実装を解説します。

週刊AWS – 2026/6/1週
Amazon Bedrock で OpenAI の GPT-5.5、GPT-5.4、Codex が一般提供開始, Amazon Bedrock AgentCore Identity で AWS Secrets Manager の既存シークレットを利用可能に, Amazon Quick が MCP 接続で VPC connectivity をサポート, Amazon RDS for SQL Server が Bring Your Own Media をサポート, Amazon ElastiCache for Valkey の durability サポートを発表, AWS Config が internal service linked rules をサポート開始, AWS Config が 9 つの新しいリソースタイプに対応, AWS Step Functions が AgentCore を活用したエージェント推論ステップに対応, Amazon Bedrock が OpenAI および Anthropic 互換 API に最適化された再設計コンソールを発表, Amazon Cognito がマルチリージョンレプリケーションに対応, Amazon SageMaker Data Agent がビジネスコンテキストを会話に統合, AWS MCP Server が cross-account および cross-role アクセスに対応, Amazon Bedrock AgentCore Runtime に対話型シェル (インタラクティブターミナル) 機能を導入
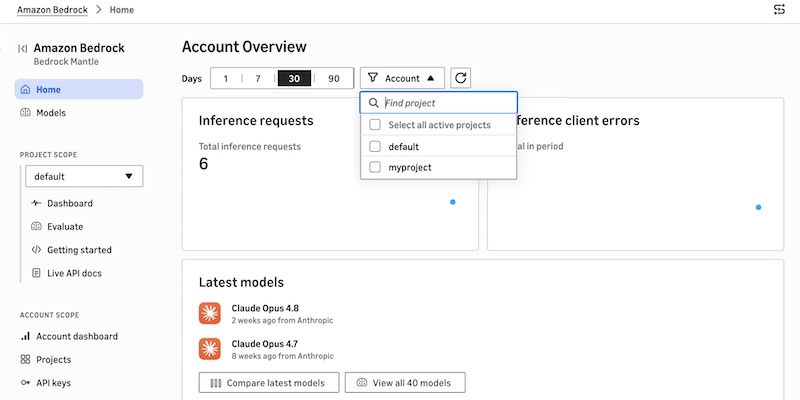
Anthropic および OpenAI 互換 API 向けに最適化された、Amazon Bedrock における新しいコンソールエクスペリエンスをお試しください
2026 年 6 月 5 日、Amazon Bedrock における新しいコンソールエクスペリエンスをお知らせ […]