Amazon Web Services ブログ
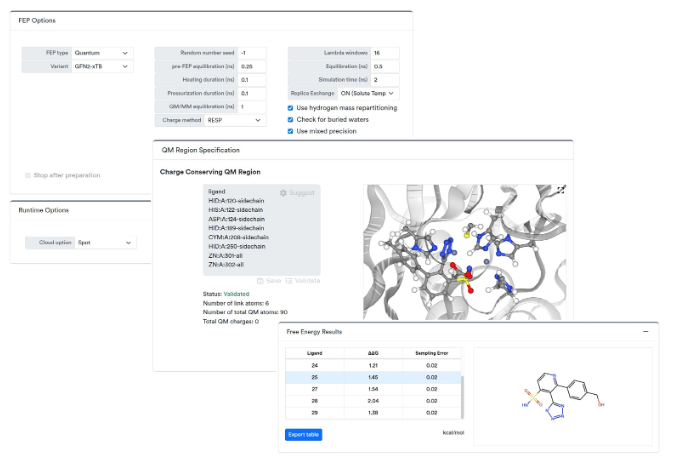
第一三共株式会社 × QSimulate: データ駆動型創薬 (D4) における QM-FEP 活用 — QSimulate × AWS で切り拓く親和性予測の高度化
このブログは、第一三共株式会社 スマートリサーチ第二研究所と QSimulate による共著です。 はじめに […]

AWS Summit Japan 2026 ブース紹介 生産ラインの未来
急な需要の変化に対して、工場の生産ラインをもっと柔軟に変更したいと言う困りごとはないでしょうか。このブログでは、AWS Summit Japan 2026 の 製造展示の中から生産ラインの未来のテーマをご紹介しています。 AI エージェント、デジタルツイン、ソフトウェアで定義された工場のキーワードで、需要の変化に追随できる新しい工場の姿をご紹介しています。

生成AIで開発ツール操作を自動化 – Kiro × MCP Server × dSPACE ControlDesk
はじめに SIL/HIL(Software/Hardware-in-the-Loop)などのシミュレーションを […]

Amazon DynamoDB グローバルテーブルのベストプラクティス – パート 1: 運用準備
あなたがグローバルな e コマースプラットフォームを運営していると想像してみてください。北米、ヨーロッパ、アジ […]

AWS DevOps Agent によるネットワークインシデント対応の自動化
本記事は、2026 年 4 月 21 日に Networking & Content Delivery […]

Kiro の Spec が速く、そしてスマートになりました
Kiro IDE に 3 つの新機能が追加されました。並列タスク実行では、Spec 内の独立したタスクを依存グラフに基づいて同時実行し、実装時間を大幅に短縮します。クイックプランモードでは、事前の確認質問を通じて要件・設計・タスクを一括生成し、Spec 作成を高速化します。要件分析では、ニューロシンボリック AI を活用して要件の曖昧さや矛盾を自動検出し、実装前に問題を解消できます。

Amazon DynamoDB グローバルテーブルのベストプラクティス – パート 3: AWS Fault Injection Service によるリージョナルレジリエンスの検証
この投稿は、Amazon DynamoDB グローバルテーブルのベストプラクティスに関するシリーズのパート 3 […]
Amazon DynamoDB グローバルテーブルのベストプラクティス – Part 2: フェイルオーバー戦略
このシリーズの パート 1 では、Amazon DynamoDB グローバルテーブルによるリージョナルレジリエ […]
Amazon Redshift Data Sharing を活用した位置情報ビッグデータ分析基盤の進化 ~KDDI Location Analyzer の新機能開発事例~
本ブログは、KDDI株式会社 高山 伸也 氏、アマゾン ウェブ サービス ジャパン合同会社 ソリューションアー […]

AWS FinOps Agent のパブリックプレビュー提供開始のお知らせ
本日 AWS は、AWS FinOps Agent のパブリックプレビューを発表します。これは、コスト異常を調 […]