Amazon Web Services ブログ
Category: Learning Levels

AWS 初学者向けの勉強方法 7 ステップ ! 2026 年版 !
みなさん、もしくはみなさんの周りで「AWS を勉強したいんだけど何から勉強すればよいだろう。どこかに勉強方法がまとまってないかな ?」「同僚や部下に AWS の勉強を促しているけど、ちょうど良い教材とか無いかな ?」という悩みを抱えている方はいませんか ? このブログはそういった AWS を勉強する際の悩みを抱えた AWS 初学者の方や、AWS 初学者を育成する立場にある方を対象にしています。
どのような段取りで知識を深めていけばよいのか、この勉強方法がなぜおすすめなのか、疑問点やハマりどころに直面した際にどこのサイトをチェックすればいいのか、など納得しながら勉強を進められるように具体的な情報を含めながら 7 ステップで紹介していきます。

次世代の Amazon OpenSearch Serverless: エージェント向けにゼロから構築
Amazon OpenSearch Serverless のアーキテクチャをゼロから刷新し、オートスケーリングが従来比で最大 20 倍に高速化、コンピューティングをゼロまでスケール可能、ピーク負荷に合わせたプロビジョニングと比べて最大 60% のコスト削減を実現した次世代アーキテクチャ NextGen を発表します。コンピューティングとストレージを完全に分離し、エージェントワークロードに最適化されました。本記事ではアーキテクチャの仕組みと、ハンズオンチュートリアルでの使い始め方を解説します。

Amazon Aurora DSQL の接続: ドライバー、接続文字列、ベストプラクティス
本記事では、Amazon Aurora DSQL への接続方法を解説します。ドライバーの設定、IAM ベースの認証トークン生成、接続プーリング、ライフサイクル管理のベストプラクティスに加え、一般的な接続問題のトラブルシューティングガイドを紹介します。
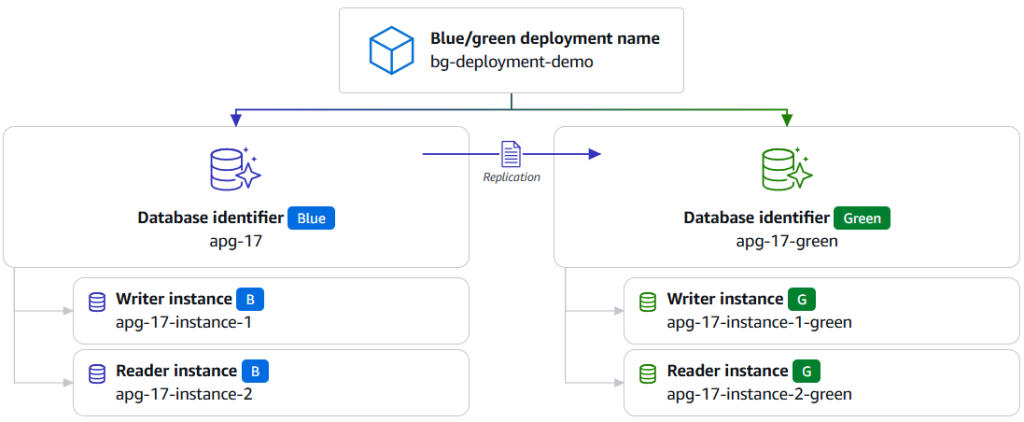
AWS JDBC Driver の Blue/Green デプロイメントプラグインでデータベースメンテナンスのダウンタイムをほぼゼロに
本記事では、AWS JDBC Driver の Blue/Green デプロイメントプラグインを紹介します。このプラグインは、Amazon RDS および Amazon Aurora の Blue/Green デプロイメント切り替え時に、接続ルーティングとトラフィック管理を自動化し、データベースメンテナンスのダウンタイムをほぼゼロにします。プラグインの設定方法とテスト結果を示し、従来の 30 秒超のダウンタイムを約 12 秒の一時停止に短縮できることを実証します。

AWS Security Agent のフルリポジトリコードスキャン機能のプレビュー提供開始
AWS Security Agent の新機能であるフルリポジトリコードレビューのプレビューリリースを発表。コードベース全体に対してコンテキスト認識型のセキュリティ分析を実行し、人間のセキュリティ研究者のように信頼境界やデータフローを推論します。従来の SAST が見逃す不整合や設計レベルの脆弱性を、透明性のある証拠と具体的な修復方法とともに検出します。本記事では仕組みと開発ワークフローへの組み込み方を紹介します。

Amazon Aurora DSQL での Change Data Capture 入門
Amazon Aurora DSQL は、パブリックプレビューで Change Data Capture (CDC) を発表しました。これにより、データベースの変更をほぼリアルタイムで Amazon Kinesis Data Streams にストリーミングできます。本記事では、Aurora DSQL CDC の仕組み、ストリーミングパイプラインの構成方法、変更イベントの消費方法を、CDC ストリームと Kinesis ストリームの作成から実際のイベント解析までの手順とともに説明します。
Amazon Aurora DSQL によるグローバル規模の金融トランザクション
Amazon Aurora DSQL を使用して、強い整合性と低レイテンシーを両立しながらグローバル規模の金融トランザクションを実行する方法を解説します。コアバンキング、グローバル経費管理、デジタル通貨インフラストラクチャの 3 つのユースケースを通じて、従来の 2 フェーズコミットや結果整合性のトレードオフを解消するアーキテクチャを紹介します。

Amazon Aurora スナップショットから Amazon Aurora DSQL へのデータ移行
Amazon Aurora DSQL はサーバーレスの分散 SQL データベースで、データ移行には COPY コマンドや dataloader スクリプトが利用できますが、テーブル単位の処理しかできず、データ変換の手段もありません。本記事では AWS Glue を使い、Aurora PostgreSQL のスナップショットから Aurora DSQL へ、データ型変換や主キーの UUID 化を含めて移行する手順を紹介します。

Amazon ElastiCache での集計機能のお知らせ
本ブログでは、Amazon ElastiCache の新機能である集計クエリ (aggregations) についてご紹介します。ElastiCache version 9.0 for Valkey で利用可能になったこの機能により、フィルタリング、グループ化、集計をキャッシュ内で直接実行でき、マイクロ秒レベルの低レイテンシーで分析が可能になります。ファセット検索、リアルタイムのトレンドランキング、運用レポートといったユースケースを、Python の valkey-py クライアントを使った実装例とともに解説しており、別途分析基盤を構築せずにリアルタイム分析を実現する方法を学べます。

Amazon ElastiCache での全文検索、完全一致検索、範囲検索、ハイブリッド検索
本ブログでは、Amazon ElastiCache for Valkey 9.0 で新たに利用可能になった全文検索、完全一致検索、数値範囲検索、ハイブリッド検索の機能をご紹介します。別途検索サービスを用意することなく、キャッシュ内で直接マイクロ秒単位の低レイテンシかつ毎秒数百万クエリのスループットで検索が可能になります。e コマースサイトを例に、タイプアヘッド検索、あいまい検索、フィルタ付きブラウジング、ベクトル類似度を組み合わせた商品レコメンデーションエンジンを Python と valkey-py で構築する手順を学べます。カタログ検索、エージェントメモリ、リアルタイムリーダーボードなどの実装に役立つ内容です。