Amazon Web Services ブログ
Category: Learning Levels

Valkey が 2 周年を迎えました
本ブログでは、オープンソースの高性能キーバリューデータストアである Valkey の誕生 2 周年を振り返り、その急速な成長とコミュニティ主導のイノベーションについてご紹介します。Amazon ElastiCache for Valkey における Intuit、Tinder、Peloton などの大規模導入事例や、Valkey 9 で実現したスループット最大 40% 向上、Redis OSS 比で最大 60% の価格性能改善、フルテキスト検索やベクトル検索、ハッシュフィールド有効期限などの新機能を学ぶことができます。モダンなキャッシングとリアルタイムデータ基盤の最新動向を知りたい方におすすめの内容です。

Amazon ElastiCache 向け Valkey 9.0 のお知らせ
本ブログでは、Amazon ElastiCache で利用可能になった Valkey 9.0 の新機能についてご紹介します。フルテキスト検索やベクトル検索、ハイブリッドクエリを組み合わせた高度な検索機能、パイプライン処理で最大40%のスループット向上、ハッシュフィールド単位の TTL 設定、クラスターモードでのマルチデータベース対応など、リアルタイム分析や生成 AI ワークロードを支える多彩な機能強化を学べます。Amazon Bedrock や Amazon SageMaker AI と連携した RAG アーキテクチャの構築にも役立つ内容となっています。
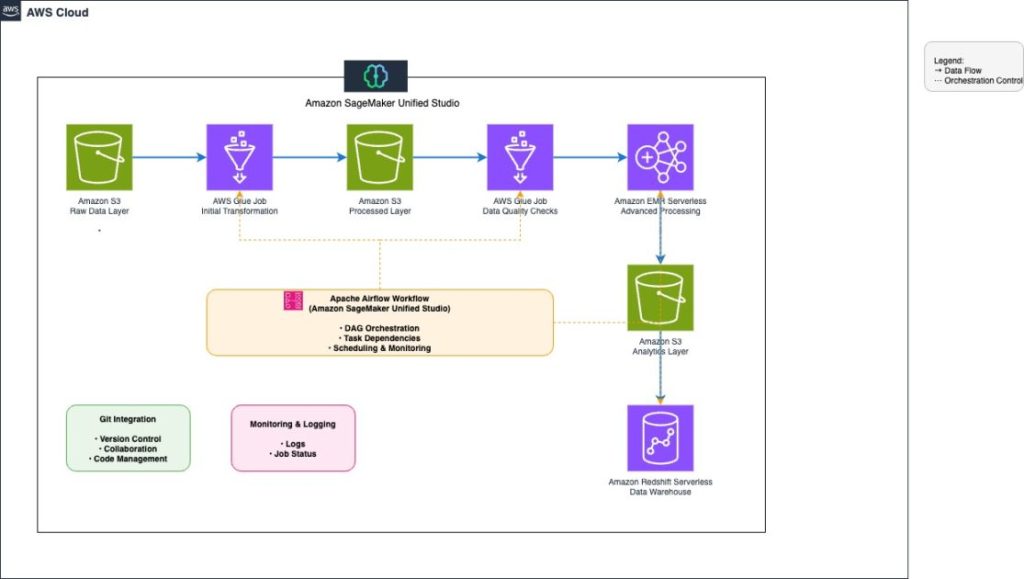
Amazon SageMaker ワークフローによるスケーラブルなエンドツーエンド ETL パイプラインのオーケストレーション
本記事では、Amazon SageMaker Unified Studio ワークフローでコードベースのエンドツーエンド ETL パイプラインを構築・管理する方法を紹介します。AWS Glue、Amazon EMR Serverless、Amazon Redshift Serverless、Amazon MWAA を組み合わせ、EC の顧客行動分析を例に、データ取り込みから変換、品質チェック、データウェアハウスへのロード、日次スケジュール実行まで、単一の統合 UI で構築する手順を解説します。

Amazon SageMaker Catalog でのビジネス用語集分類ルールの必須化
Amazon SageMaker Catalog で、資産レベルでの用語集タームの分類 (タグ付け) に対するメタデータ適用ルールがサポートされました。本記事では、金融サービスのユースケースを例に、プロジェクトから公開するすべての資産に特定のビジネス用語タームを必須化するルールの作成手順を紹介します。

Amazon DataZone によるデータガバナンスのスケール: Covestro の事例
本記事では、Covestro が中央集権型のデータレイクから Amazon DataZone と AWS Serverless Data Lake Framework (SDLF) を使ったデータメッシュアーキテクチャへ移行した事例を紹介します。標準化されたブループリントと自動化されたガバナンスにより、1,000 を超えるデータパイプラインを運用しながら市場投入までの時間を 70% 短縮し、部門横断のデータ共有と品質管理を実現した経緯を解説します。

データサイロの解消: Volkswagen の Amazon DataZone を活用したアプローチ
本記事では、Volkswagen が Amazon DataZone を使ってデータサイロを解消し、データメッシュアーキテクチャを実装した事例を紹介します。AWS CDK を使った自動登録ワークフローにより、Amazon Redshift データウェアハウスのデータ資産を中央のデータメッシュに自動公開する仕組みを構築し、データガバナンスを維持しつつデータ検出とアクセスを効率化する方法を解説します。

Amazon SageMaker のカスタムサブスクリプションワークフローによるデータガバナンスの加速
本記事では、Amazon SageMaker のサブスクリプションリクエスト承認を自動化するカスタムワークフローを紹介します。AWS Lambda、Amazon EventBridge、Amazon SNS を組み合わせたイベント駆動型のサーバーレスアーキテクチャにより、ガバナンスを維持しつつ機微でないデータセットへのアクセスを迅速化できます。

Amazon SageMaker Catalog を利用するガバナンスチーム向けメール通知の自動化
Amazon SageMaker Catalog で発生するイベントを中央ガバナンスチームに自動通知する仕組みを、Amazon EventBridge、AWS Lambda、Amazon SNS、Amazon SQS を組み合わせて構築する方法を紹介します。プロジェクト作成や資産公開といった重要なイベントをリアルタイムで捕捉し、メールアラートとして届けることで、組織のガバナンス標準をスケールしながら維持できます。

Amazon EVS で Windows Server ライセンスが利用可能に: ステップバイステップガイド
Amazon EVS で Microsoft Windows Server ライセンスが利用可能になりました。BYOL または vCPU 時間単位の AWS 提供ライセンスの 2 つのオプションから選択でき、EVS 環境内で Windows Server VM を柔軟に運用できます。本記事では、vCenter コネクタの作成からライセンスエンタイトルメントの設定、KMS サーバーによるアクティベーションまでの手順を説明します。

ボトルネックからブレークスルーへ:Dutchie のデータベース移行の軌跡
この投稿では、Dutchie が 2025 年の 4/20 週に向けて、ミッションクリティカルなワークロードを Amazon RDS for SQL Server に移行する際の課題をいかに成功裏に乗り越えたのかを探ります。