Amazon Web Services ブログ
Amazon Aurora PostgreSQL から通知を送信する
企業のお客様は、Amazon Aurora PostgreSQL データベースで多くの日々のバッチジョブを実行し、そのようなジョブを完了した後にアクティビティを追跡するためにメールやテキストなどの通知方法が必要です。Aurora PostgreSQL はマネージドサービスであるため、セキュリティ上の理由から pgsmtp や pgplpythonu などのデータベース拡張機能へのアクセスを制限しています。これにより、他の自動メッセージングの手段で通知を送信するデータベースの必要性が高まります。
この記事では、組織が定期的にビジネス検証のために従業員の情報をプルし、ジョブの完了後に通知を必要とするシナリオを使用します。この記事では、Python を使用してサンプルジョブを作成し、AWS Lambda と Amazon SNS を使用して、E メールまたはテキストメッセージで通知する方法を示します。
前提条件
このソリューションには以下が必要です。
- 適切な AWS のサービスにアクセスできる有効な AWS アカウント。
- Aurora PostgreSQL データベース。詳細については、「Amazon Aurora DB クラスターの作成」を参照してください。
- VPC の外部に通知を送信するための、SNS の VPC エンドポイント。詳細については、「Amazon SNS の Amazon VPC エンドポイントの作成」を参照してください。
- データベースに接続するための pgadmin または PSQL Client ツールなどのクライアントツール。
- AWS Secret Manager にすでに設定および保存されているデータベースパスワード。詳細については、「AWS Secrets Manager とは」を参照してください
ソリューションアーキテクチャ
次のアーキテクチャは、Amazon RDS、PostgreSQL、Lambda と SNS がどのように統合されてバッチジョブの完了時に通知を送信するかを示しています。プロセスは次のとおりです。
- Lambda 関数がデータベースバッチジョブをトリガーします。
- データベースジョブは、データベースのキューテーブルにジョブステータスを 0 または 1 として挿入します。
- Lambda 関数は、キューテーブルからステータスを取得し、情報を SNS API にプッシュします。
- SNS は、サブスクライバーに E メールまたはモバイル通知を配信します。
次のアーキテクチャの図をご覧ください。
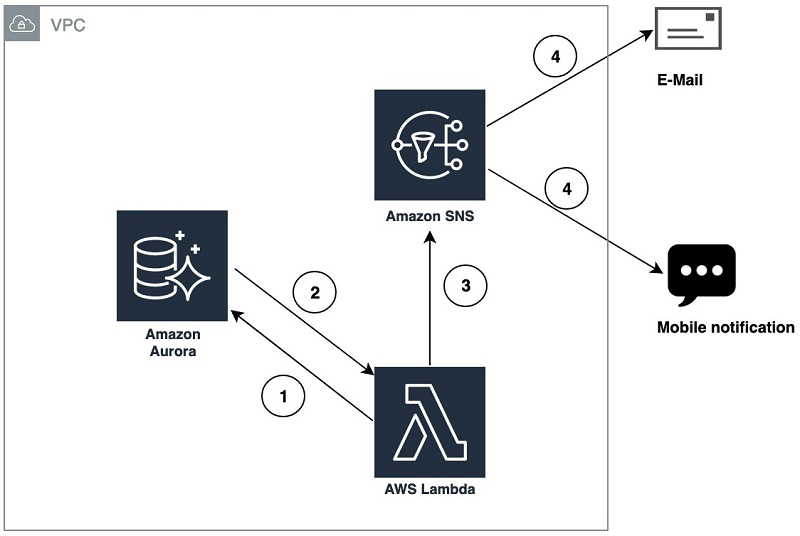
図 1: Aurora PostgreSQL から通知を送信するための設定を示すアーキテクチャ図
Aurora PostgreSQL データベースの設定
データベースを設定するには、次の手順を実行します。
- Linux ターミナルから次のコードを使用して、Aurora PostgreSQL データベースにログインします。
- プロンプトが表示されたら、パスワードを入力します。
別の接続方法については、RDS ユーザーガイドの「Amazon Aurora PostgreSQL DB クラスターへの接続」を参照してください。
- データベースに
pg_emailtableというテーブルを作成します。
このテーブルには、実行するジョブに関する情報が保存され、登録ユーザーが通知を受信したかどうかを追跡するのに役立ちます。次のコードをご覧ください。この記事では、関数
pgfunc_ins ()をバッチジョブの例として使用します。これは 5 分ごとに実行されるようにスケジュールされています。このサンプルバッチジョブは、特定の従業員 ID のデータベースから従業員の詳細を取得します。従業員 ID が存在する場合、実行ステータスが成功であるというレコードをキューテーブルに挿入します。そうでない場合は、失敗ステータスを挿入します。
pgfunc_ins()バッチジョブに次のコードを入力します。
SNS をセットアップして通知を有効にする
次の手順は、トピックを作成し、SNS サブスクリプションが通知を受信する適切なユーザーを追加する方法を示しています。
- AWS アカウントにログインして、SNS ダッシュボードに移動します。
- メニューから [Create topic] を選択します。
- [Name] には、
sns_pg_lambdaを入力します。 - オプションで、[Display name] を入力します。
次のスクリーンショットは Create topic オプションを示しています。
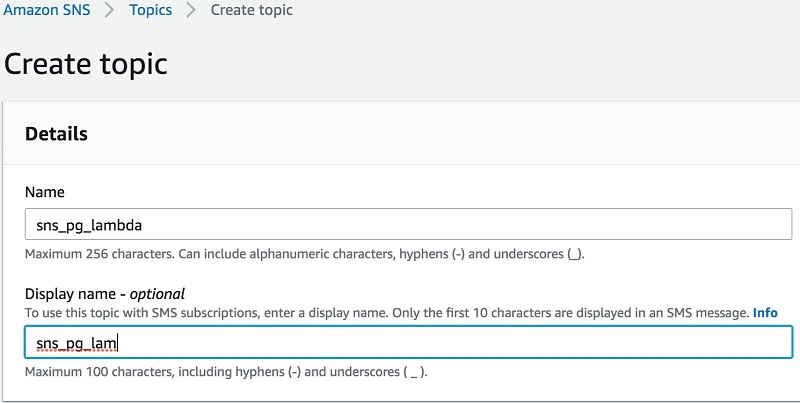
図 2: トピックを作成する
- メニューから [Subscriptions] を選択します。
- [Create subscription] を選択します。
- トピック ARN の場合、ステップ 4 で作成したトピック ARN を選択します。
- [Protocol] には、エンドポイントのタイプを選択します。
- [Endpoint] には、エンドポイント情報を入力します。このシナリオでは、E メールおよび SMS エンドポイントを作成しています。
次のスクリーンショットは、Create subscription の詳細を示しています。
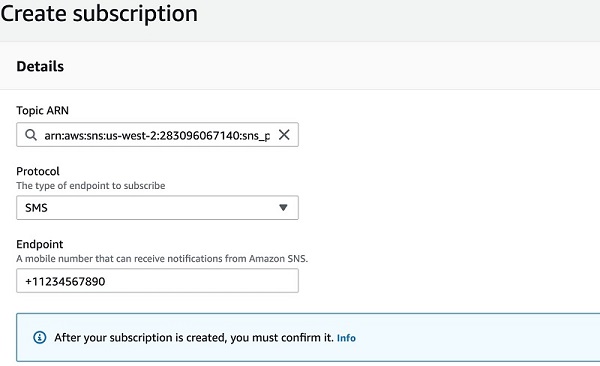
図 3: トピック ARN の SMS サブスクリプションを作成する
[Create subscription] をクリックします
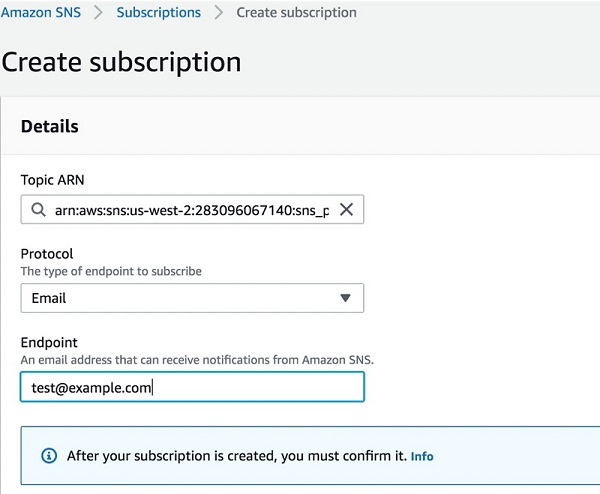
図 4: トピック ARN の E メールサブスクリプションを作成する
[Create subscription] をクリックします
- サブスクライブしているメールを開き、メールで受け取ったリンクをクリックしてサブスクリプションを確認します。
電話番号は自動的に確認されます。E メールおよび SMS プロトコルの確認のステータスは、図 5 に示すように、サブスクリプションページで確認できます。
サブスクリプションの検索結果の次のスクリーンショットをご覧ください。
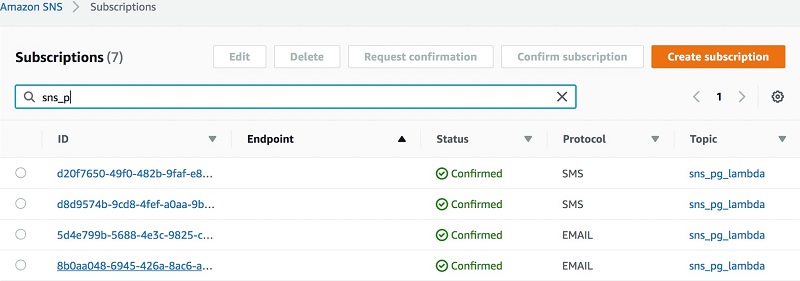
図 5: SMS および E メールプロトコルのステータス
IAM ポリシーのセットアップ
IAM ポリシーを設定するには、次の手順を実行します。
- IAM コンソールのメニューから [Policies] を選択します。
- [Create policy] を選択します。
このページでは、この特定のユースケースのために定義されたカスタムポリシーを作成できます。次のスクリーンショットは、[Create policy] ページを示しています。
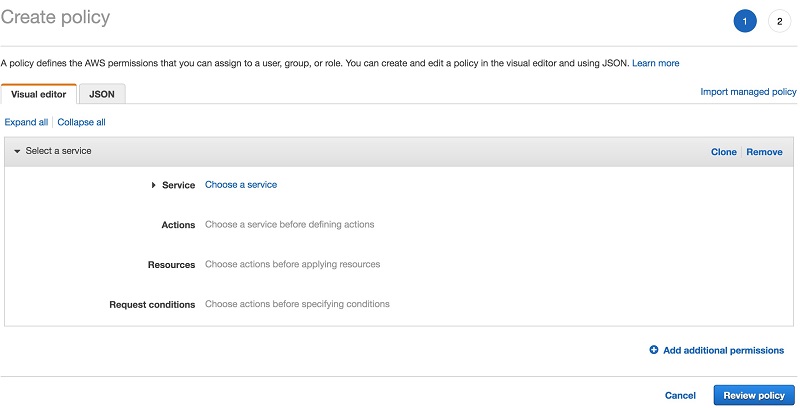
図 6: ポリシーを作成する
- タブから、[JSON] を選択します。
- 次のコードを入力します。
このコードは、関数を作成し、サブスクライバーにメッセージを公開するために最低限必要な権限を確立します。
- [Review policy] を選択します。
次のスクリーンショットは、[Review policy] ページを示し、ポリシーのカスタム「Name」と「Description」を入力します。このシナリオでは、「pgemailpubpolicy」をポリシー名として使用しました。
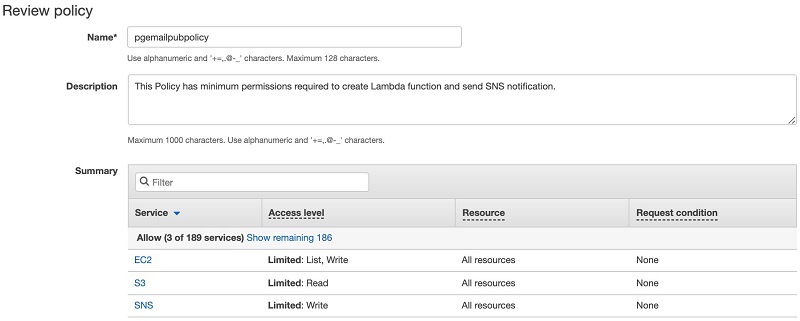
図 7: ポリシーを確認する
- [Create policy] を選択します。
Lambda 関数を設定する
これで、Lambda 関数を作成する準備ができました。以下の手順を完了してください。
- PyPI ウェブサイトの psycopg2 2.8.3 から Python モジュール
psycopg2をダウンロードします。
Python を使用して PostgreSQL データベースに接続するには、このモジュールが必要です。Lambda 関数は、PostgreSQL データベースのバッチジョブの実行を支援し、SNS API を使用して完了時にサブスクライバーに通知を配信します。 - 次のコードを入力して、ファイルを
apg_email_function.pyとして保存し、環境と要件に基づいて変更を加えます。
- ステップ 1 (psycopg2)、ステップ 2 (apg_email_function.py) でファイルを圧縮し、コンピューター上のアクセス可能な場所に圧縮ファイルを保存します。このシナリオでは、zip ファイルに「pgemaildbcode.zip」という名前を付けました
- Lambda ダッシュボードで、[Create function] を選択します。
- [Author from scratch] を選択します。
次のスクリーンショットは、[Create function] オプションを示しています。
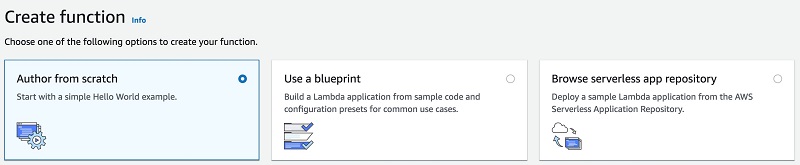
図 8: 一から Lambda 関数を作成する
- [Function name] には、関数のカスタム名を入力します。この記事では
mypgemailfuncを使用しています。 - [Runtime] には、言語を選択します。この記事では Python 2.7 を使用しています。
- [Execution role] では、[Use an existing role] を選択します。
- [Existing role] には、以前に作成したロールを入力します (この記事では
pgemailpubrole)。 - [Create function] を選択します。
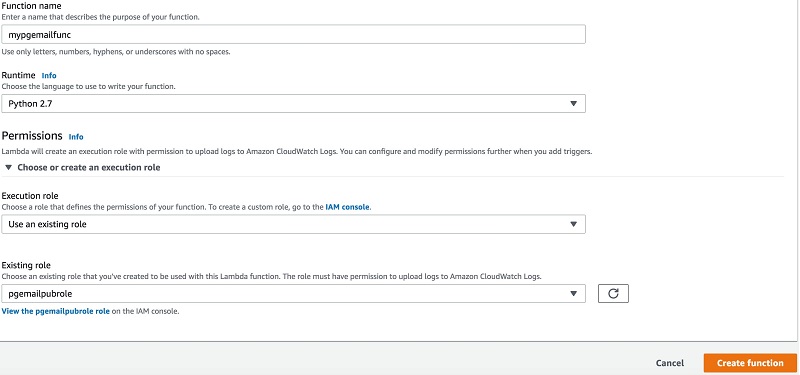
図 9: 関数変数の作成手順 6〜10
- 関数を正常に作成したら、Function code に詳細を入力します
- [Code entry type] では、[Upload a .zip file from Step 3] を選択します。
- [Runtime] では、[Python 2.7] を選択します。
- [Handler] には、
apg_email_function.lambda_handlerと入力します。
次のスクリーンショットは、Function code オプションを示しています。

図 10: コードをアップロードしてハンドラーを定義する
step2 で提供されるコードには、変数 dbname、hostname、username、passwordvalue、topicarn、username があります。これらは Environment variables フィールドに入力して、値を関数コードに動的に渡す必要があります。Environment variables フィールドの次のスクリーンショットをご覧ください。
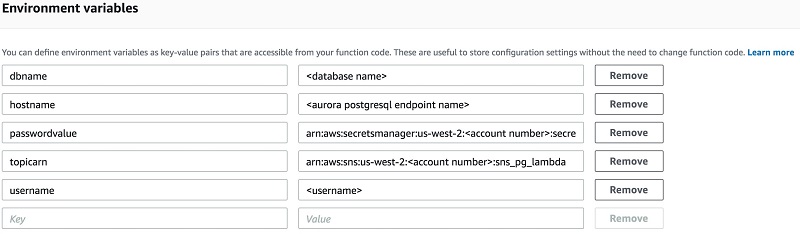
図 11: Python コードで定義された環境変数を入力する
- [Execution role] で、[Use an existing role] を選択します。
- [Existing role] では、先に作成した IAM ロールを選択します。
- [Basic settings] で、[Description] に
apgemailsettingsと入力します。 - [Memory] を 512 MB に設定します。
- [Timeout] には、0 min と 30 sec を入力します。
ジョブに適したメモリとタイムアウトを変更できます。
次のスクリーンショットは、Execution role と Basic settings オプションを示しています。
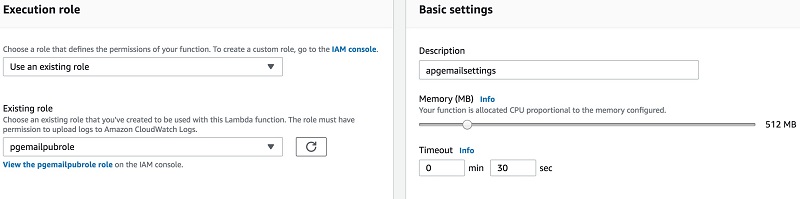
図 12: Lambda 関数の実行ロールと基本設定を入力する
- Network settings までスクロールダウンし、Aurora PostgreSQL インスタンスが存在する VPC を選択します。
RDS コンソールからの VPC、サブネット、セキュリティグループを含む Aurora PostgreSQL データベースクラスター設定の取得の詳細については、「Amazon Aurora DB クラスターを表示する」 を参照してください。
- [Save] を選択します。
Lambda 関数をテストする
これで、テストイベントを設定して、新しい関数をテストできます。
- Lambda コンソールの右上隅で、[Test] を選択します
- [Create new test event] チェックボックスを選択します。
- [Event template] では、テンプレート「Amazon SNS Topic Notification」 を選択します。
- [Event name] には、
samplesnseventと入力します。
次のスクリーンショットは、[Cofigure test event] ページを示しています。
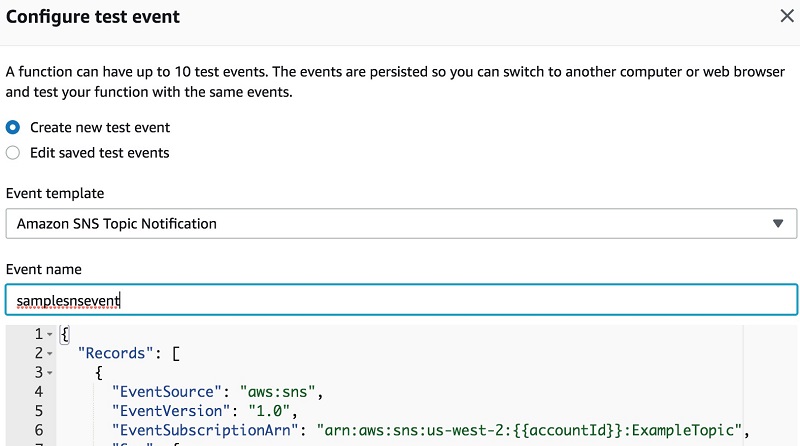
図 13: Lambda 関数のテストイベントを設定する
- [Create] を選択します。
mypgemailfunc関数をテストするには、Lambda コンソールの右上隅から [Test] を選択します。- Lambda 関数が実行されると、「Batch Job 1:employee id 100 found and job executed successfully at 2019-09-19 17:51:37.836658」という E メールとモバイルの通知を受け取ります。
次のスクリーンショットは、E メールの例を示しています。

図 14: Eメールの確認
次のスクリーンショットは、テキストメッセージの例を示しています。
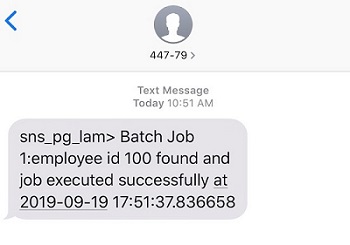
図 15: モバイル通知の確認
Lambda 関数を正常に実行した後、「select * from pg_emailtable」をクエリして、データベースの pg_emailtable テーブルに新しいレコードがあることを検証します
このスクリプトには、以前に配信された古いメッセージをクリーンアップするメカニズムが含まれています。ただし、理想的なテーブルパフォーマンスを得るには、自動バキュームをオンに維持し、積極的なバキューム処理を実行してテーブルパフォーマンスが低下しないようにし、他のデータベースメンテナンス操作とともに全体的なパフォーマンスが損なわれないようにする必要があります。詳細については、PostgreSQL ドキュメントの「VACUUM」、「Automatic Vacuuming」、および「Routine Vacuuming」を参照してください。
この記事では、テーブルで 1000 回の更新、挿入、および削除が行われるたびに自動バキュームが実行され、pg_emailtable で操作を実行しているときにパフォーマンスが低下しないようにします。ユースケースの値を選択するには、徹底的なテストを実行し、環境に適した値を選択します。次のコードをご覧ください。
テーブルの使用率が高く、1 時間または 1 日で数千の E メールを処理する場合は、vacuum analyze pg_emailtable コマンドを使用して手動でバキュームを実行することを検討してください。
概要
この記事では、Aurora PostgreSQL データベースで発生するイベントやジョブの通知を E メールまたはテキストメッセージとして送信するためのエンドツーエンドのソリューションを示しました。データベースバッチジョブの監査、監視、またはスケジュールのためにこのソリューションを実装し、ニーズに基づいてカスタマイズすることもできます。このソリューションを RDS および Aurora PostgreSQL データベースに適用できます。
このソリューションに関するコメントやご質問は、以下のコメントセクションからお送りください。
著者について

Rajeshkumar Sabankar は、アマゾン ウェブ サービスのデータベース専門アーキテクトです。 Amazon の内部顧客と連携して、AWS クラウドで安全でスケーラブルで復元力のあるアーキテクチャを構築し、顧客がオンプレミスデータベースから AWS RDS および Aurora データベースに移行するのを支援しています。

Santhosh Kumar Adapa は、アマゾン ウェブ サービスの Oracle データベースクラウドアーキテクトです。Amazon の内部顧客と連携して、AWS クラウドで安全でスケーラブルで復元力のあるアーキテクチャを構築し、顧客がオンプレミスデータベースから AWS RDS および Aurora データベースに移行するのを支援しています。