- AWS Builder Center
- builders.flash
AWS で始める機械学習はじめの一歩 ! AWS の主要な AI/ML サービスをグラレコで解説
2024-01-04 | Author : 米倉 裕基 (監修 : 辻 浩季、久保 隆宏)
はじめに
builders.flash 読者のみなさん、こんにちは ! テクニカルライターの米倉裕基と申します。
本記事では、AWS が提供する AI/ML (人工知能/機械学習) 関連のサービスをご紹介します。
今日において AI/ML のテクノロジーは、個人利用からビジネス利用、社会機能を支えるインフラに至るまで、あらゆる場面で活用されており、今後ますます需要が高まることが予想されます。AWS では、AI/ML を特に重要なサービスカテゴリーと位置づけ、多様なユースケースに対応した高機能なサービスを提供してきました。
たとえば機械学習エンジニアであれば、Amazon SageMaker で独自の ML モデルを構築したり、Amazon Bedrock で先進的な生成 AI をアプリケーションに組み込むことができます。一方、機械学習の知識がない開発者でも、自然言語処理や画像認識など、特定の目的に応じて簡単に利用できるマネージド AI/ML サービスも多数提供しています。このように、AWS の AI/ML サービスは、初心者から専門家まで幅広いユーザーに対応しているのが特徴です。
builders.flash メールメンバー登録
本記事で紹介する内容
本記事では、簡単に利用できるマネージド AI/ML サービスを中心に、代表的な 5 つのサービスを紹介します。各サービスの主なユースケースと使い方を順を追ってご説明します。
-
AWS における AI/ML サービス
-
個人に最適化されたレコメンド:Amazon Personalize
-
ノーコードで時系列予測:Amazon SageMaker Canvas
-
画像や動画を分析し、人やオブジェクトを検出:Amazon Rekognition
-
音声をテキストに自動変換:Amazon Transcribe
-
テキストからインサイトを検出:Amazon Comprehend
-
AI/ML サービスの共通ワークフロー
それでは、項目ごとに詳しく見ていきましょう。
AWS における AI/ML サービス
AWS が提供する AI/ML サービスは、大まかに特定のタスクに特化した AI サービスと、機械学習プラットフォームを提供する ML サービスの 2 種類に分けられます。AI サービスの多くは、専門知識がなくても簡単な操作で利用でき、ユースケースに応じて手軽に機械学習を使ったさまざまな機能を実装できます。ML サービスは、より高度な機械学習の専門家向けに、効率的な ML モデル開発を促進する機能を提供しています。
3 つのレイヤー
AI サービス
特定のユースケースに特化した ML モデルを利用するためのサービスです。画像や音声認識、テキスト分析やセマンティック検索など、特定のタスクに特化したサービスが提供されています。
AI サービス カテゴリー 機能と特徴 Amazon Rekognition 画像 入力した画像や動画から物体や人を認識するサービス。 Amazon Polly 音声 自然な音声で文章を朗読する音声合成サービス。 Amazon Transcribe 音声データを高精度でテキストに変換するサービス。 Amazon Comprehend テキスト 入力したテキストから、言語、キーワード、感情などの情報を検出するサービス。 Amazon Translate 入力したテキストを機械学習を用いて他言語に翻訳するサービス。 Amazon Textract 画像ファイルやスキャン文書から、テキスト、表、画像などの内容を抽出するサービス。 Amazon Kendra 検索 企業の膨大な文書データを検索可能にするサービス。 Amazon Lex チャットボット テキスト、音声対話が可能なチャットボットを構築できるサービス。 Amazon Personalize レコメンド ユーザーの行動データから個人に最適化された商品推薦を生成するサービス。 Amazon Fraud Detector 不正検知 オンライン取引における不正をリアルタイムで検知するサービス。 Amazon CodeGuru コードレビュー コードレビューや改善提案を自動化するサービス。 Amazon Connect Contact Lens コンタクセンター コンタクトセンターの顧客対応業務を支援するための AI サービス。ML サービス
MLモデルを独自に構築・調整することを目的としたサービスが提供されています。下記以外にも、Clarify や Feature Store、Data Wrangler など、Amazon SageMaker に統合される多くのサービス群が提供されています。
|
ML サービス |
カテゴリー |
機能と特徴 |
|
Amazon SageMaker |
ML モデル構築プラットフォーム |
エンドツーエンドの機械学習ワークフローを効率的に実行できるプラットフォーム。 |
|
Amazon SageMaker Ground Truth |
データラベリング |
機械学習のトレーニングデータを効率的にラベリングできるサービス。 |
|
Amazon SageMaker Canvas |
ノーコード機械学習 |
ノーコードで機械学習による正確な予測を可能にするサービス。 |
|
Amazon Bedrock |
生成 AI 基盤モデルプラットフォーム |
高性能な基盤モデル (FM) を単一の API で選択できるフルマネージド型サービス。 |
ML フレームワーク/インフラストラクチャ
AWS の機械学習サービスは、PyTorch などを始めとした、さまざまなオープンソースの ML フレームワークに対応しています。加えて、高性能な GPU インスタンスや機械学習専用に設計されたチップを搭載したインスタンスなど、機械学習のワークロードに最適化されたインフラストラクチャを提供しており、高度な計算リソースを活用して効率的に ML モデルをトレーニング・デプロイすることが可能です。
|
サービス |
カテゴリー |
機能と特徴 |
|
MXNet / TensorFlow / PyTorch |
フレームワーク |
オープンソースのディープラーニング向けフレームワーク。高いパフォーマンスと柔軟性を提供し、複雑なニューラルネットワークの構築とトレーニングを実現。 |
|
Gluon / Kera / Horovod |
ライブラリ |
MXNet に統合された、オープンソースの Python 用の高機能ライブラリ。ディープラーニングモデルの作成、トレーニング、デプロイをより直感的に行える。 |
|
インフラストラクチャ |
ML 向けリソース |
各種 ML フレームワークがプリインストールされた Deep Learning AMI や、Elastic Inference 対応インスタンスや AWS Trainium チップ搭載インスタンスなど、機械学習のワークロードに適したリソース。 |
AWS の AI/ML サービスを支えるこれらの 3 つのレイヤーについて詳しくは、AWS Samples の 「AWS ML JP」をご覧ください。
本記事では、機械学習に詳しくなくても簡単に利用できる AI/ML サービスの例として、Amazon Personalize、Amazon SageMaker Canvas、Amazon Transcribe、Amazon Comprehend、Amazon Rekognition の 5 つのサービスの機能と特徴を紹介します。
個人に最適化されたレコメンド - Amazon Personalize
Amazon Personalize (以下 Personalize)は、ユーザーの行動データを入力として、個々のユーザーの興味や好みを予測するサービスです。ユーザーの行動データとは、例えばウェブサイトやアプリなどでのユーザーの閲覧履歴、検索履歴、購買履歴など、個人の特性を表すさまざまなアクティビティを指します。
Personalize では、ユーザーの行動データを学習し、個人の特性に合わせた商品やコンテンツをおすすめするためのモデルを構築できます。レコメンドシステム構築の知識がなくても、Personalize が最適なアルゴリズムを選択してサポートするため、簡単に個人に最適化されたレコメンドを実行できます。
また、Personalize で構築したレコメンドモデルは、API を通じてアプリケーションなどから容易に呼び出すことができます。これにより、手軽にユーザーの個人特性に基づくおすすめ機能をアプリケーションに実装できます。
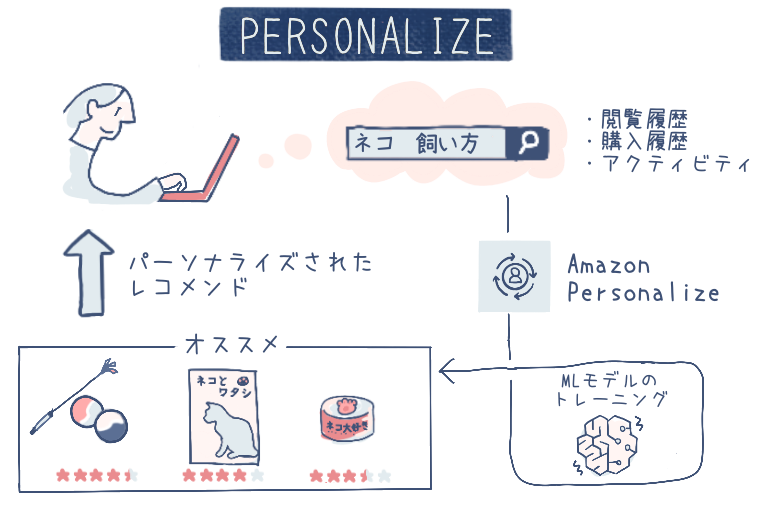
主なユースケース
基本的な利用手順
Personalize の簡単な使い方は以下のとおりです。詳しくは「デベロッパーガイド (英語のみ)」をご覧ください。
ユーザーの行動データ (閲覧履歴等) を用意します。データセットに、個人情報は含めないように注意します。
Personalize コンソールから、データセットグループを作成し、スキーマを定義します。
データセットとアルゴリズム、各種パラメータを指定したトレーニング用のレシピを作成します。
レシピを使って、モデルをトレーニングします。
レコメンドモデルを API で取得し、アプリケーションと連携します。
Personalize について詳しくは、製品ページの「Amazon Personalize」をご覧ください。
ノーコードで時系列予測 - Amazon SageMaker Canvas
Amazon SageMaker Canvas (以下 Canvas) は、ML モデルをノーコードで構築できる汎用プラットフォームです。
Canvas は、予測モデリング、画像分類、テキスト分類、異常検知など、多様な機械学習タスクに対応しています。時系列データを用いた需要予測などのタスクも、Canvas 上で簡単に構築することができます。
時系列データとは、時間的な順序や間隔を持って記録されたデータを指します。Canvas では時系列データから、周期性やトレンド、需要や在庫の将来予測が可能なモデルを構築できます。過去の気温、株価、販売実績などの時系列データを入力として、Canvas 上で前処理、特徴エンジニアリング、モデル構築を行うことで、高精度な時系列予測モデルを手軽に構築できます。
Canvas は、時系列予測以外にも多彩な用途の ML モデルの構築が可能な汎用プラットフォームです。2023 年 11 月には、Amazon Bedrock モデルや、Amazon SageMaker JumpStart モデルなど、生成 AI の基盤モデルにアクセスできるようになりました。これにより Canvas を使って、チャットボットや顧客対応アシスタントなど、対話アプリケーションの開発が可能になり、さらに活用の幅が広がりました。
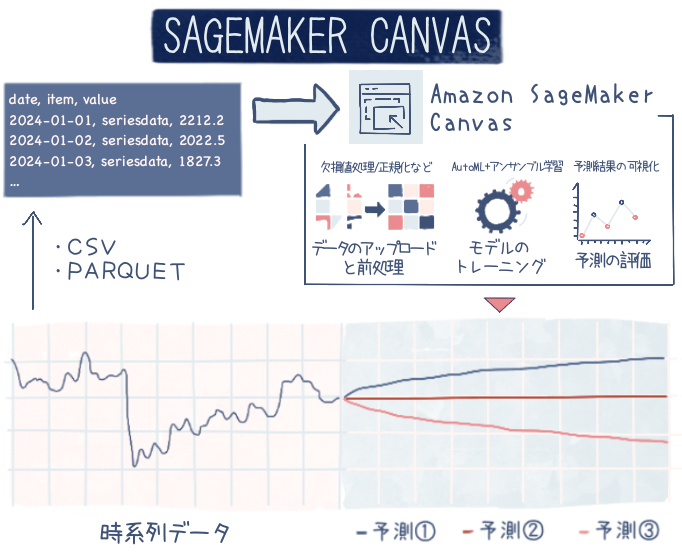
主なユースケース
下記は、時系列予測で利用した場合のユースケースです。
基本的な使い方
Canvas の基本的な利用手順は以下の通りです。詳しくは「デベロッパーガイド」をご覧ください。
需要実績や業績データを CSV または Parquet 形式で Canvas 上にアップロードし、Datasets を作成します。
Canvas 上でデータの欠損値処理や正規化、目的変数と説明変数の指定等の前処理と、傾向や周期性を捉える特徴量を生成します。
予測対象のカラム、予測頻度、予測期間などを指定して時系列予測モデルを構築します。Canvas では、AutoML とアンサンブル学習により自動で最適なモデルが構築されます。
構築したモデルの性能を Canvas 上で評価します。また、SageMaker にデプロイして API 化も可能です。
デプロイしたモデルに対して API リクエストを送信し、予測結果を取得してアプリケーションで活用します。
Canvas について詳しくは、製品ページの「Amazon SageMaker Canvas」をご覧ください。
画像や動画を分析し、人やオブジェクトを検出 - Amazon Rekognition
Amazon Rekognition (以下 Recognition) は、入力した画像や動画から、物体や人を識別するサービスです。機械学習を活用しており、高精度な物体検出が特徴です。
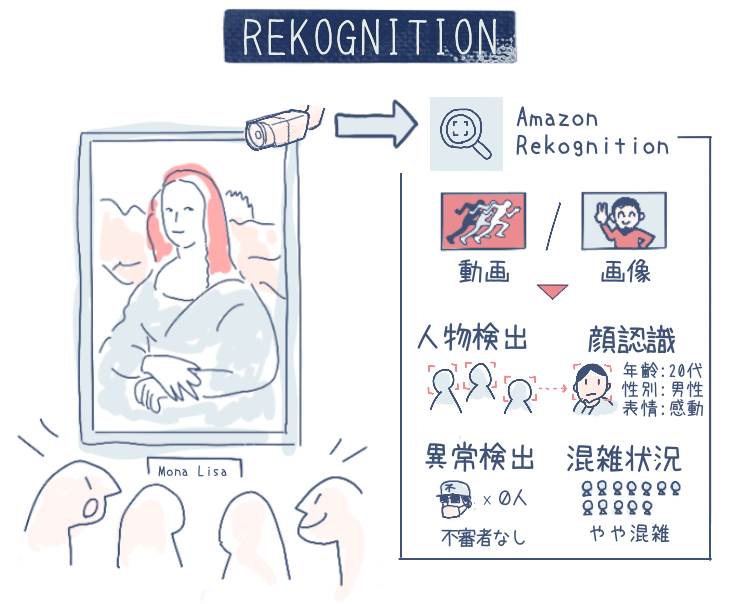
主なユースケース
基本的な使い方
分析対象の画像や動画ファイルを用意します。
Rekognition コンソールから分析ジョブを実行します。
検出された物体や人の情報を確認します。
分析結果は Rekognition API で取得し、アプリケーションと連携します。
Rekognition について詳しくは、製品ページの「Amazon Rekognition」をご覧ください。
音声をテキストに自動変換 - Amazon Transcribe
Amazon Transcribe (以下 Transcribe) は、音声データを入力として、テキストに変換するサービスです。会議の音声記録や電話の通話記録、動画の音声など、さまざまな形式の音声ファイルを入力として利用できます。
Transcribe は音声認識技術を使用して、音声データからテキストを高精度に抽出します。たとえば複数の話者が含まれる音声データでも、話者ごとにテキストを分離して書き起こすこともできます。音声認識技術の知識がなくても、Transcribe が最適な変換処理を行うため、簡単に音声の文字起こしが可能です。
Transcribe で構築した音声認識モデルは API 経由で呼び出すことができます。これにより、音声データをテキストに変換する機能を手軽にアプリケーションに実装できます。
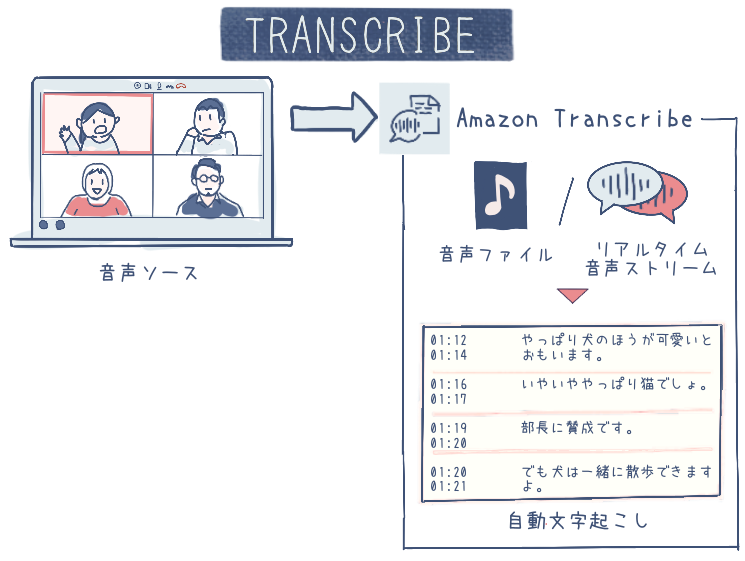
主なユースケース
基本的な使い方
Transcribe の基本的な利用手順は以下の通りです。詳しくは、「デベロッパーガイド」をご参照ください。
変換対象の音声ファイルを用意します。
Transcribe コンソールからトランスクリプトを作成します。
音声ファイルを指定して変換ジョブを実行します。
テキストに変換された結果を確認します。
変換結果は Transcribe API で取得し、アプリケーションと連携します。
Transcribe について詳しくは、製品ページの「Amazon Transcribe」をご覧ください。
テキストからインサイトを検出 - Amazon Comprehend
Amazon Comprehend (以下 Comprehend) は、入力したテキストから、自然言語処理を利用して、言語、キーワード、人名・地名・組織名、感情などの情報を検出するサービスです。
Comprehend はスケーラブルで、大量のテキストデータを処理することが可能です。また、継続的にモデルが改善されるため、分析精度が向上します。自然言語処理を活用したいが専門知識がない場合に、Comprehend は有用なサービスです。
Comprehend で構築した自然言語処理モデルは API 経由で呼び出すことができます。これにより、テキストデータ分析機能を手軽にアプリケーションに実装できます。
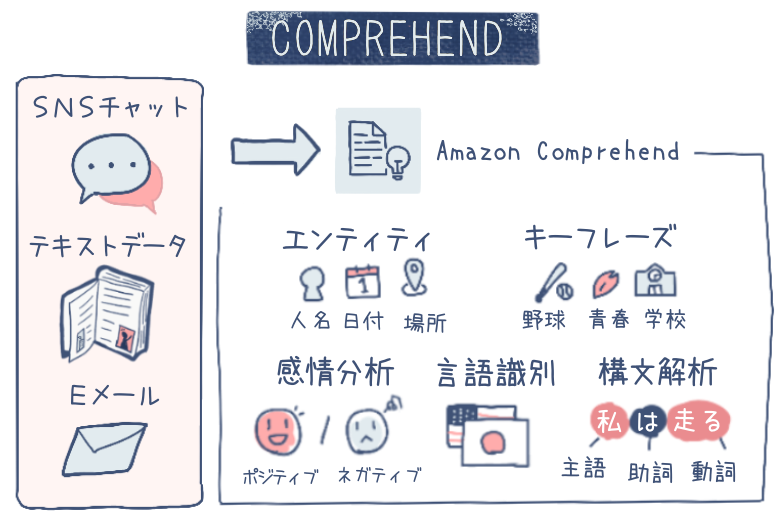
主なユースケース
基本的な使い方
Comprehend の基本的な利用手順は以下の通りです。詳しくは「デベロッパーガイド」をご参照ください。
分析対象のテキストファイルを用意します。
Comprehend コンソールから分析ジョブを実行します。
意図、感情、キーワードなどの分析結果を確認します。
分析結果は Comprehend API で取得し、アプリケーションと連携します。
Comprehend について詳しくは、製品ページの「Amazon Comprehend」をご覧ください。
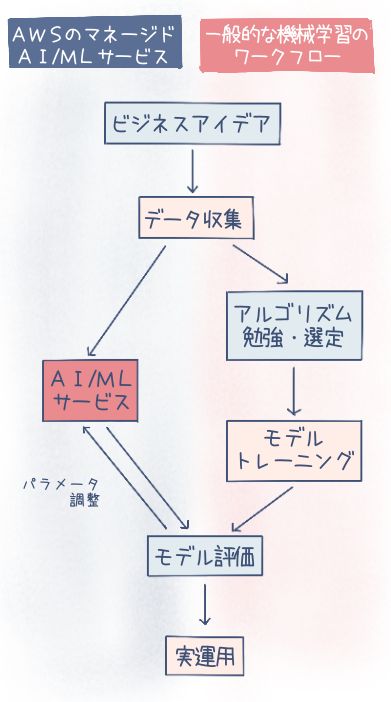
AI/ML サービスの共通ワークフロー
これまで見てきたように、AWS の AI サービスは、データの入力、モデルの構築、モデルの運用という一般的な機械学習のワークフローを共通のプロセスとして抽象化しています。開発者は、個々のサービスの違いを意識することなく、この一般的なワークフローで目的に応じた AI サービスを自由に選択できます。
共通するワークフロー
本記事で紹介した 5 つのサービス以外にも、多くの AI/ML サービスを以下のワークフローで操作できます。
-
データセットの収集:
利用目的に応じたデータセットを収集し、サービスにインポートする。 -
モデルの生成:
トレーニングジョブを実行すると、サービスが最適なアルゴリズムを自動で選択しモデルを生成する。 -
モデルの評価:
モデルの性能を評価し、必要に応じてパラメータ調整を行いモデルを再生成する。 -
実運用:
構築したモデルを API を通じて呼び出し、アプリケーションと連携する。
AWS の AI/ML サービスを使う利点
本来、アプリケーションに AI/ML の機能を実装するには、アルゴリズムの選定や環境構築、プログラミングなど、機械学習の知識が必要です。しかし、AWS のマネージド AI/ML サービスでは、こうしたプロセスの多くが自動化されるため、機械学習に詳しくない開発者でも簡単にサービスを利用することができます。このため開発者は、構築したモデルの精度を上げるためのパラメータ調整や、アプリケーションの UI/UX など、ビジネス上の重要な機能に集中することができます。
本記事では 5 つのサービスを例に説明しましたが、AWS では他にも多くの AI/ML サービスを展開しており、開発者はユースケースに合わせて自由に選択できます。また AWS エコシステムの中で利用することで、例えば Amazon S3 を使ったデータセットの管理や AWS IAM を使ったアクセスコントロールなど、AWS クラウドゆえの運用上のメリットも得られます。さらに高度な機械学習ワークフローを構築する場合は、 AWS Lambda を用いたデータ前処理や、 Amazon SageMaker との連携によるモデルの詳細な解析なども可能です。
他の AWS の AI/ML サービスについて詳しく知りたい場合は、公式サイトの「AWS での機械学習」をご覧ください。
まとめ
最後に、本記事で紹介した AI/ML サービスの全体図を見てみましょう。
2024 年 1 月現在、公式サイトの「AWS クラウド製品」では、48 種類の機械学習関連サービスを確認できます。AWS の AI/ML サービスは市場のニーズに合わせて継続的に拡充されています。たとえば生成 AI の需要の高まりに応じ、re:Invent 2023 では、Amazon Bedrock のナレッジベースの一般提供開始や、生成 AI アシスタントの Amazon Q、臨床ノート生成サービスの AWS HealthScribe など、さまざまな生成 AI 関連サービスが発表されました。
本記事を読んで AWS のマネージド AI/ML サービスに興味を持たれた方、実際に使ってみたいと思われた方は、ぜひ各種製品ページや、AWS Hands-on for Beginners の「AWS Managed AI/ML サービス はじめの一歩」や、AWS スキルビルダーなど入門者向けのコンテンツも合わせてご覧ください。
全体図
筆者・監修者プロフィール

著者プロフィール
米倉 裕基
アマゾン ウェブ サービス ジャパン合同会社
テクニカルライター・イラストレーター
日英テクニカルライター・イラストレーター・ドキュメントエンジニアとして、各種エンジニア向け技術文書の制作を行ってきました。
趣味は娘に隠れてホラーゲームをプレイすることと、暗号通貨自動取引ボットの開発です。
現在、AWS や機械学習、ブロックチェーン関連の資格取得に向け勉強中です。

監修者プロフィール
辻 浩季
アマゾン ウェブ サービス ジャパン合同会社
技術統括本部 西日本ソリューション部 ソリューションアーキテクト
発電プラント機器の異常検知システムの設計・開発を経て 2020 年にアマゾン ウェブ サービス ジャパン合同会社に入社。
主に西日本のお客様を支援。趣味はベースギターで、毎月どこかのクラブで演奏しています。

監修者プロフィール
久保 隆宏
アマゾン ウェブ サービス ジャパン合同会社
DevRel, Machine Learning
コンサルタント、機械学習エンジニア、プロダクトマネージャーを経て機械学習をプロダクトに活かすことに取り組んできました。DevRel では機械学習領域での AWS 認知拡大に取り組んでいます。 趣味はランニングとテニス、ライブに行くことです。最近の情勢を受けライブハウスに行けないのが目下の悩みです。 現在、Machine Learning Product Manager について勉強中です。